
查阅了部分资料,笔者拙见,打标签问题无论是文本、图像和视频,涉及到较多对内容的“理解”,目前没有解决得很好。主要原因有以下一些方面,标签具有多样性,有背景内容标签,细节内容标签,内容属性标签,风格标签等等;一些标签的样本的实际表现方式多种多样,样本的规律不明显则不利于模型学习;标签问题没有唯一的标准答案,也存在一定的主观性,不好评估的问题则更不利于模型学习。
依然笔者拙见,视频打标签问题目前还没有很好的解决办法,也处于探索阶段。方法上主要有以下一些思路:可以从视频角度出发,可以从图像角度出发;可以利用caption生成的思路,可以转化为多分类问题。
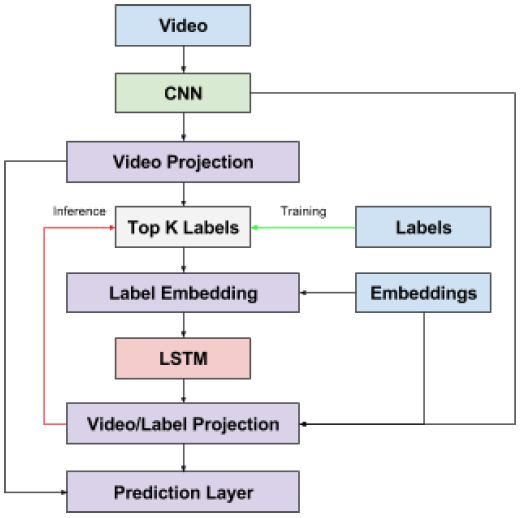
直接从视频角度出发,即从视频整体的角度出发,提取图像帧,甚至字幕或者语音信息,进一步处理得出视频标签的结果。Deep Learning YouTube Video Tags,这篇文章提出一个hybrid CNN-RNN结构,将视频的图像特征,以及利用LSTM模型对标签考虑标签相关性和依赖性的word embeddings,联合起来,网络结构如下图。
Large-scale Video Classification with Convolutional Neural Networks提出了几种应用于视频分类的卷积神经网络结构,在网络中体现时空信息。single frame:就是把一帧帧的图像分别输入到CNN中去,和普通的处理图像的CNN没有区别;late fution:把相聚L的两帧图像分别输入到两个CNN中去,然后在最后一层连接到同一个full connect的softmax层上去;early fution:把连续L帧的图像叠在一起输入到一个CNN中去;
slow fution:通过在时间和空间维度增加卷积层,从而提供更多的时空全局信息。如下图所示:

另一方面,为了提高训练速度,这篇文章还提出Multiresolution CNNs,分别将截取中间部分的图像和缩放的图像作为网络的输入,如下图所示:

这篇文章主要研究了卷积神经网络在大规模视频分类中的应用和表现。通过实验,文章总结网络细节对于卷积神经网络的效果并不非常敏感。但总的来说,slow fusion网络结构的效果更好。
从图像角度出发,即从视频中提取一些帧,通过对帧图像的分析,进一步得出视频标签的结果。对图像的分析,也可以转化为图像打标签或者图像描述问题。Visual-Tex: Video Tagging using Frame Captions,先从视频中提取固定数量的帧,用训练好的image to caption模型对图像生成描述。然后将文本描述组合起来,提取文本特征并用分类方法进行分类,得到tag结果。这篇文章对生成的描述,对比了多种不同的特征和多种不同的分类方法。可见,图像打标签对视频打标签有较大的借鉴意义。另一种思路,CNN-RNN: A Unified Framework for Multi-label Image Classification可以看作将图像打标签问题转化为多分类问题。将卷积神经网络应用到多标签分类问题中的一个常用方法是转化为多个单标签的分类问题,利用ranking loss或者cross-entropy loss进行训练。但这种方法往往忽略了标签之间的联系或者标签之间语义重复的问题。这篇文章设计了CNN-RNN的网络结构里,并利用attention机制,更好地体现标签间的相关性、标签间的冗余信息、图像中的物体细节等。网络结构主要如下图所示,主要包括两个部分:CNN部分提取图像的语义表达,RNN部分主要获取图像和标签之间的关系和标签之间的依赖信息。

针对空间部分短视频数据,笔者设计了一个简单的视频打标签的方案,并进行了实验。由于预处理和算法细节的很多进一步改进和完善工作还没有进行,在此只是提出一种思路和把实验结果简单地做个分享。
方法介绍:
整体思路:图片打标签 => 视频打标签
也就是说,对视频提取帧,得到视频中的图片;然后对图片进行打标签;最后将视频中帧图片的标签进行整合,得到视频标签。
1、从图片描述说起:
图片描述典型框架:利用deep convolutional neural network来encode 输入图像,然后利用Long Short Term Memory(LSTM) RNN decoder来生成输出文本描述。

2、在打标签任务中,我们把标签或类别组合,构造成“描述”:
一级类别+二级类别+标签(重复的词语进行去重)
3、利用预训练和强化学习,对训练样本图片和标签构造模型映射。
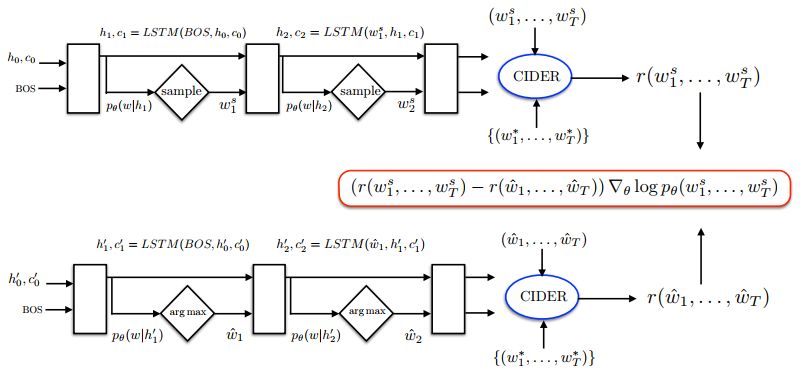
《Self-critical Sequence Training for Image Captioning》
网络模型有三种:fc model;topdown model;att2in model;模型细节见论文。
一般地,给定输入图像和输出文本target,,模型训练的过程为最小化cross entropy loss(maximum-likelihood training objective):
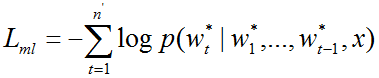
利用self-critical policy gradient training algorithm:

其中,是reward funtion
![]()
通过根据每一个decoding time step的概率分布进行采样获得,是baseline output,通过最大化每一个decoding time step的概率分布输出获得,也就是a greedy search。论文里提到,利用CIDEr metric作为reward function,效果最好。
4、根据视频帧图片的标签,对视频打标签。具体有两种思路:
记录视频提取的所有帧图片中每一个出现的标签,以及标签出现的次数(有多少帧图片
被打上了这个标签)。按照出现次数排序。
1.将帧图片的最多前n个标签,输出为视频标签。
2.将帧图片中,出现次数大于阈值c的标签,,输出为视频标签。
数据示例:
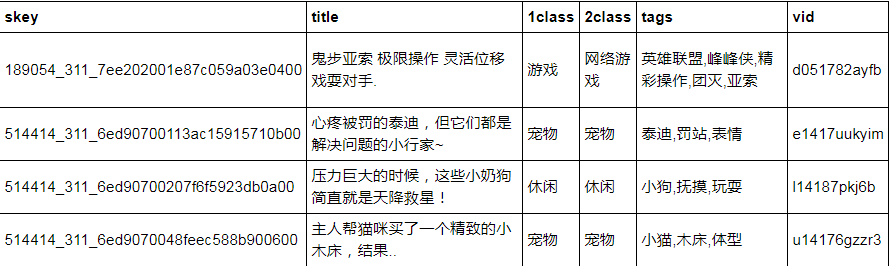
其中1class表示一级类别,2class表示二级类别。
实验结果示例:
截取一些实验结果展示如下,其中output指模型输出的结果,reference指人工标定的参考结果。


总的来说,游戏类视频的数据量最大,效果较好;但具体不同英雄的视频数据如果不平衡,也会影响算法结果。其他类型视频数据不算太稀疏的效果也不错,长尾视频的效果不行。
总结:
数据预处理、模型结构、损失函数、优化方法等各方面,都还有很多值得根据视频打标签应用的实际情况进行调整的地方。后续再不断优化。方法和实验都还粗糙,希望大家多批评指导。
来源:腾讯QQ大数据
更多阅读:
