
本文介绍了神盾推荐系统中基于热传导模型的相关推荐模块. 神盾推荐系统是 SNG 数据中心立身 QQ 大数据构建的通用化推荐平台. 服务于应用宝, 手Q手游推荐, 企鹅 FM 等多个应用场景, 为业务方提升收入, 提高用户体验做出巨大贡献.
神盾的基于热传导模型的相关推荐模块的代号是 “反浩克装甲” (Hulk Buster), 来源于”复仇者联盟2” 中钢铁侠开发用来对抗绿巨人浩克的专用装备. 其以模块化思路设计, 平时运行在近地轨道中, 有需要的时候可以分散投射到战场组合使用.

反浩克装甲
神盾推荐的反浩克装甲起步于应用宝的推荐场景, 其后在企鹅 FM 的相关推荐场景上进行了快速的迭代升级. 最终取得对比原始 ItemCF 超过 25% 的效果提升.
在推荐系统发挥用武之处的各个场景中, 相关类的推荐是一个比较常见的场景. 其要面对的场景可以定义为:用户在找到自己喜欢的东西并进行消费的时候或者消费行为完成之后, 对用户展示一些相关的物品以便用户继续消费.
这可以是电台 app 里面的 “收听过这个电台的用户还听过…”, 也可以是书城里面的 “看了又看”, 也可以是视频网站里面的 “相关视频”. 通过相关推荐, 我们可以为用户提供更好的浏览体验, 并把用户和更多的服务连接起来.
应用宝和企鹅 FM 的相关推荐场景
本文讨论的问题是基于物品相关的解决方案:针对每一个待推荐的物品计算一个相似物品列表, 然后在用户访问的时候, 拉取相似度最高的几个物品用于展示.
这种方法的特点是每个用户的推荐结果是一样的, 是一种非个性化的解决方案. 由于所需存储资源和内容库里面的物品数量相关, 因此好处在于能够节省资源, 避免用户增长带来的成本问题. 而且只要物品相似度模型建好了, 用户体验都能够达到令人比较满意的程度. 但这种方法只适合物品数量不会爆发式增长的场景, 例如应用宝的应用推荐, 或者视频网站的视频推荐. 另外, 其毕竟是一个非个性化推荐算法, 每个用户看到的内容都是一样的, 从而推荐效果存在较低的天花板.
物品相关算法最经典的应该是 ItemCF 算法. 但在神盾的相关推荐场景中, 我们大量使用了周涛1提出的热传导算法, 因为其在我们大量线上实验中获得了更好的推荐效果.
但在此我们更想强调算法背后的复杂网络思维. 这个算法把推荐实例中的用户和待推荐物品的关系类比为二分图, 当用户对物品的行为有操作的时候, 我们就可以在中间连一条线. 通过构建用户 – 物品二分图, 我们可以认为被同一个用户操作过的物品是相互关联的. 这种把问题看做一个图的研究视角, 给我们之后的进一步优化提供了便利.

通过把用户和物品当作网络上的节点的形式, 我们可以更直观的思考推荐
ItemCF 等物品相关算法, 大多都是根据用户的行为利用统计方法计算得到, 并不是根据某个目标函数朝着最优解优化. 在实际的推荐场景中实现某个优化项的时候, 我们通常会面临许多超参数的选择. 例如, 要选择多长时间的用户行为去构建二分图, 或者热传导算法参数的选择. 有时候囿于流量我们可能没有办法把每一个候选集合都试一遍, 因此在实际操作中我们会构建一个离线训练场景, 用于调试新的算法特性, 然后推到线上用 a/b test 去验证.
至于离线场景的构建, 一般是利用用户的实际流水, 看相关推荐的结果是否能够预测用户的下一步行动. 这里的技巧在于, 构建离线训练场景之后需要依此在线上投放几次 a/b test, 以验证线下场景的有效性.
为了获得更精准的推荐结果, 神盾推荐团队在热传导模型的基础上做了大量的努力, 最终得到现在的代号为反浩克装甲的相关推荐模块. 下面介绍该模块的主要特性:
▲ 引入热传导, 调整热门和冷门物品的权重, 平衡推荐的精确度和多样性.
在热传导算法的论文中, 作者强调该算法能够平衡推荐的精确度和多样性, 能够在保证精确度的情况下, 让长尾物品的相关度靠前. 在实际操作中, 我们可以利用算法的参数, 调整 “冷门” 和 “热门” 物品的权重, 从而适应不一样的场景. 例如, 我们发现相比应用宝的 app 推荐, 企鹅 FM 的电台相关推荐应该要用一个更加偏向冷门的权重.
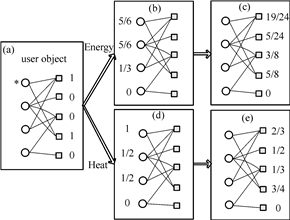
热传导算法1实际上是两种能量传递模式的组合, 一个倾向于推荐流行物品, 另一个倾向于推荐冷门物品. 图片来源2
▲ 用户和物品的链接, 应该是建立在用户真正喜欢这个物品的基础上
在用户 – 物品的二分图上, 边的定义是第一步, 也是最重要的一步. 因为有一些用户操作可能并不代表用户真正喜欢这个物品, 盲目投入用户对物品的所有操作行为, 可能会出现 “Garbage In Garbage Out” 的情况. 因此神盾团队在构建推荐算法时, 会分析先行, 用数据确定什么情况下用户和物品才能够有一条链接.
以企鹅 FM 为例, 我们统计企鹅 FM 用户收听比例 (收听时长/节目总时长) 的分布, 发现用户收听行为主要集中在两类, 一类是收听比例<10%, 一类是收听比例>90%. 我们可以认为, 如果用户收听一个节目不足总时长的 10% 就停止播放了, 那么很有可能他们并不喜欢这个节目, 把这些数据投入算法可能会造成不好的影响, 因此在构建二分图前去掉.
▲ 过滤用户数较低的物品, 让推荐更有把握, 多阈值融合, 保证覆盖率.
如果一个物品只被一个用户喜欢, 按照热传导的逻辑, 这个用户喜欢的其他物品会出现在这个物品的相关列表中. 但这样实际上很容易把不相关的东西联系在一起, 因为一个用户的兴趣可能非常广泛. 因此, 有必要过滤掉一部分用户数较少的物品.
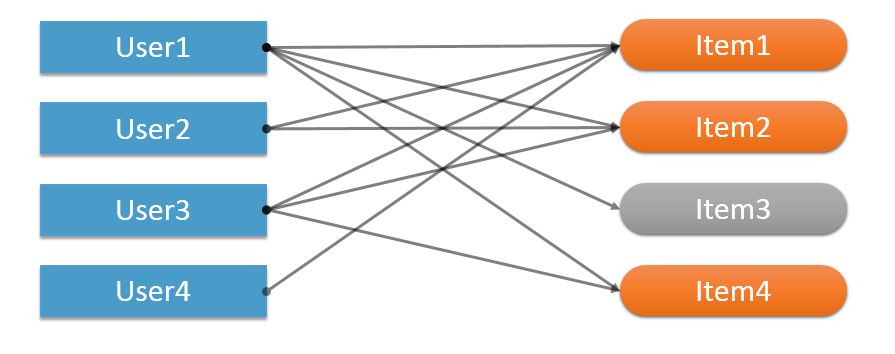
度小于一定阈值的节点将会被被隔离在训练之外, 取阈值为2, Item3 会在训练前被舍去
以用户 – 物品二分图的视角来看, 喜欢某个物品的用户数量, 就是这个物品的度, 在我们看来, 这个度的越大意味着它的推荐结果越有把握. 对物品的过滤, 实际上就是把度较低的物品进行一次过滤.
支持度过滤阈值越大, 对推荐结果的把握也越大, 但是能够获得推荐结果的物品的数量就会越少. 为了保证覆盖率, 可以分别用两个阈值训练出两个模型, 然后用低阈值的结果给高阈值的结果做补充.
▲ 融合用户和物品的属性及不同行为的行为特征, 能提高推荐的覆盖率, 解决冷启动问题, 充分发挥不同特征的数据价值.
在推荐中, 一般除了用户在应用内的行为数据之外, 我们还能够获得其他的一些信息. 例如用户的基础画像, 或者物品的基础信息. 但热传导算法的作者并没有提出如何把多种特征融合到模型中.
这里我们采用了大特征的概念3, 把特征本身当作一个节点加入到二分图中. 例如, 我们可以把企鹅 FM 里面的专辑分类当作一个 “用户”, 专辑对某个分类的隶属关系, 在二分图中可以看做某个分类 “喜欢” 这个专辑. 用户的属性依然, 我们能够把性别(男/女)当作一个物品, 引入到二分图中.
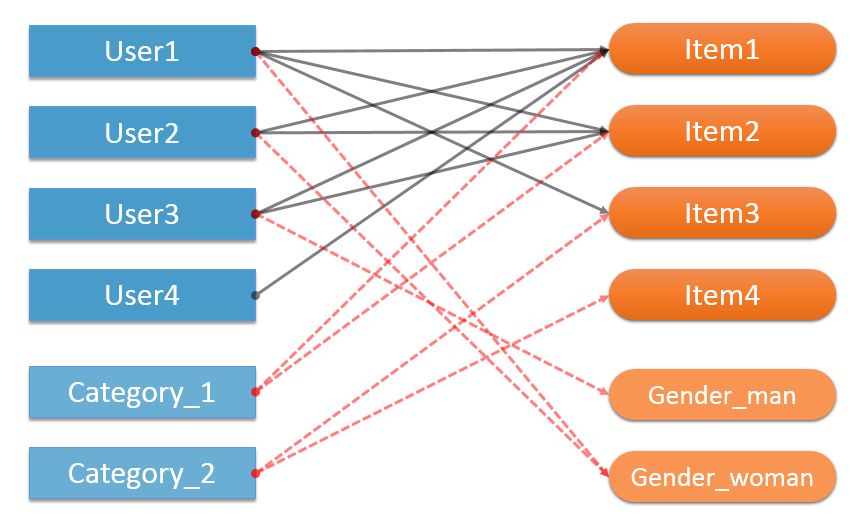
用户的特征被当做一个物品加入到二分图中, 物品的特征则看做一个用户, 此时冷门 Item4 也能获得关联
这样做有一个好处, 就是能够提高推荐的覆盖率, 让一些没有用户操作过的冷门物品(或者新物品)也能够通过物品的基础属性(例如分类)连接起来. 从而能够解决冷启动问题. 但通过简单的推导可以发现, 如果有一个物品没有用户操作行为数据, 只有一个”分类”属性, 那么在热传导算法的推荐结果中, 它会给出同分类最冷门的物品, 也就是另一个没有用户操作行为的物品. 这实际上不怎么合理. 这里的解决办法有二, 一个是引入更多的物品信息, 让物品尽可能多维度的连接起来, 另一个是做物品度过滤.
▲ 利用时间因素, 去掉时间间隔较大的两次用户行为生成的链接.
现有的模型在选定了训练时长后, 会将用户该时间段内形成有效链接的所有物品关联在一起, 这样可能会把一些具有时效性的内容关联在一起. 以企鹅 FM 为例, 用户白天听的 DJ 摇滚和晚上的轻音乐, 躺在床上听的《鬼吹灯》和车上听的交通电台, 都有可能被链接起来.
为了解决这个问题, 我们把用户对物品的操作时间引入到推荐中, 从而让两个物品不再因为时间跨度较大的行为而联系在一起, 这里我们采用的方法是把处在不同时间窗口的用户看做多个节点, 从而强化同一个时间窗口内被操作的两个物品的联系.
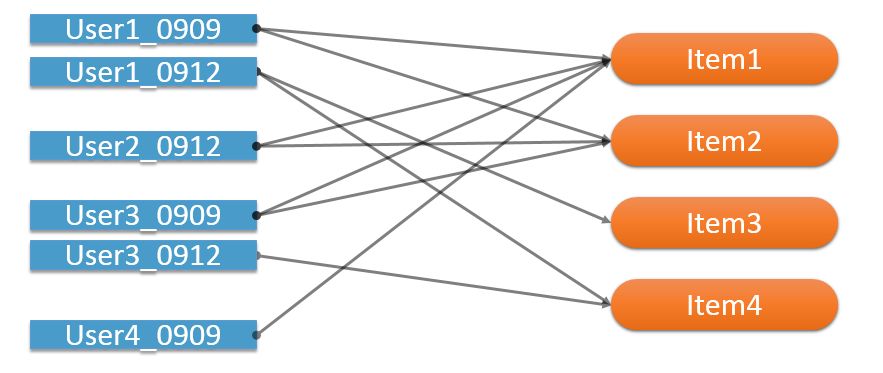
用户根据操作日期被看做成多个节点, 从而只有同一天的操作行为会把物品关联起来, 这里 User1 被分割成 9月9日的 User1 和 9月12日的 User1
▲ 可以利用用户对推荐结果的反馈信息, 修正推荐结果.
虽然特征的丰富和模型的优化能够很大的提高推荐的效果, 但我们认为推出看起来不怎么准确的结果仍是很难避免的. 对此我们的一个做法是: 把推荐的结果推给用户, 看看用户是否有点击, 对于用户喜欢点击的物品, 提高它的权重; 对于没有点击的物品, 则降低它在推荐列表中的排序.
为了利用用户的实际行为修正推荐结果, 我们计算了每一个待推荐物品和相关物品的转化率, 然后用转化率对权重进行调整. 而这里需要考虑的是有些相关物品限于槽位并不会被用户看到, 从而无法计算转化率, 这里我们利用了神盾实现的点击转化率平滑4模块, 对点击量过小的物品赋予一个预估的转化率.
▲ 按用户属性分群, 各群分别构建热传导, 开创个性化的相关推荐模型.
在服务资源有限的情况下, 非个性化物品相关推荐能够用较少的资源为海量用户提供服务. 但当资源充足的时候, 我们可以考虑把用户的因素考虑进去. 在神盾推荐系统中, 我们实现了按照用户的基础信息和画像分群投放热传导的推荐逻辑. 具体的思路是针对每个群体训练一个热传导模型, 当用户发起推荐请求的时候, 给出对应群体的推荐结果. 为了发挥 QQ 海量用户画像的价值, 神盾对用户展现的推荐结果, 可以由用户所属不同群的推荐结果进行加权获得
本文介绍了神盾推荐团队这几个月内在相关推荐这个场景下的工作成果. 我们在一个简单的网络的基础上, 构建了一个多层次, 能利用多种数据源的推荐策略. 经过线上数据检验, 这个方法能够获得对比传统 ItemCF 算法超过 25% 的性能提升.
但是相关推荐并不是我们努力把物品更准确的链接起来的唯一目的. 计算物品关联还有其他的用处:
1、物品相关的结果可以直接或者间接的被用于个性化推荐,可以根据用户的历史行为, 找出跟用户历史最为相似的物品, 推荐给用户;也可以把物品相似度看做一个特征, 融入到其他模型中;
2、通过把物品关联起来, 我们可以构建一个物品网络, 对物品网络的分析, 能够让我们更加的了解每一个物品. 例如, 我们尝试把企鹅 FM 的电台通过物品相关构建一个电台网络,在分析中我们发现相似的电台会形成社团, 我们认为这隐含了物品的基础特征.
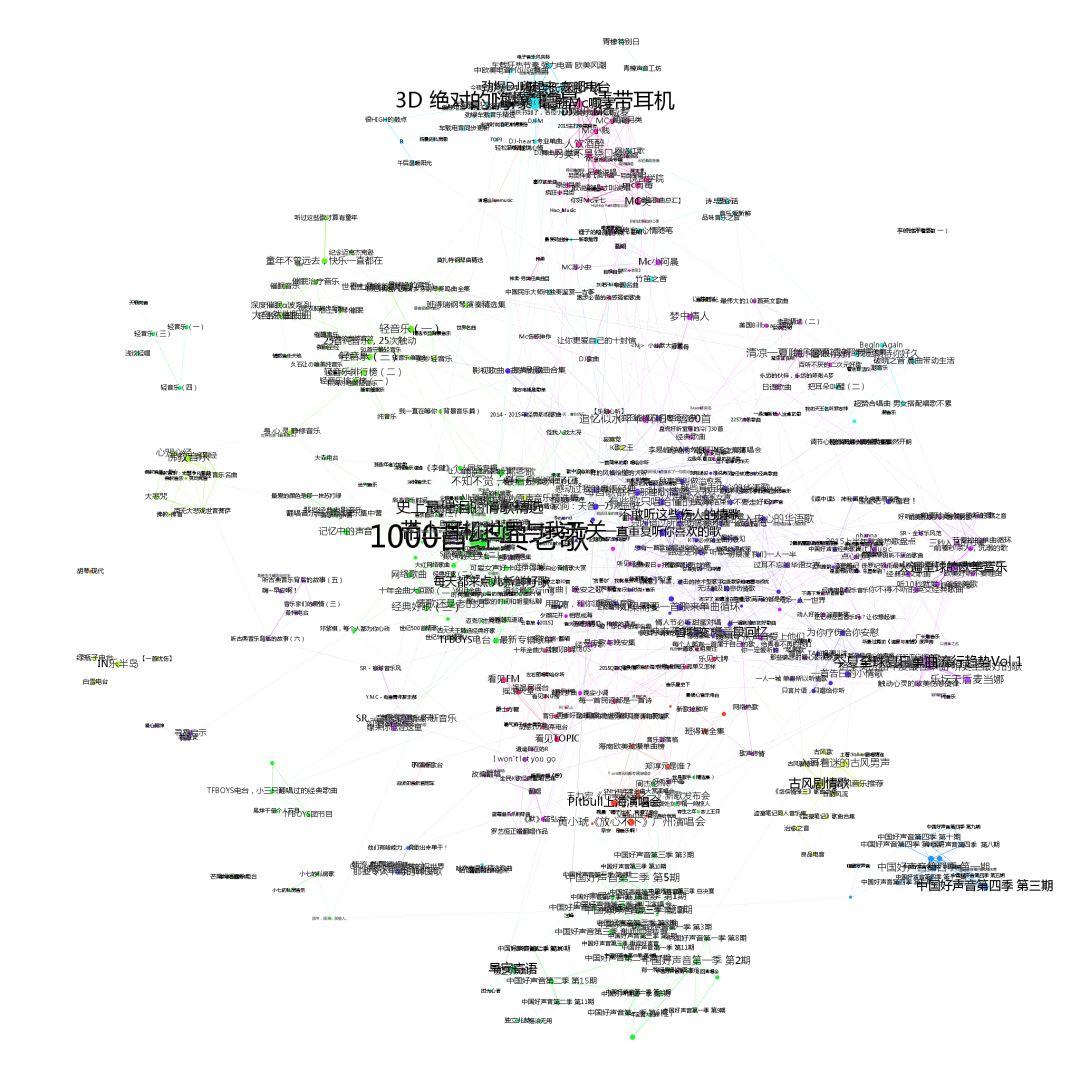
对企鹅 FM 的音乐分类的物品关联网络进行可视化, 节点大小与被关联次数相关, 颜色为社区发现结果
这两个应用场景, 我们认为将可以有效提升推荐效率以至于我们对用户的理解, 因此非常值得我们进一步探索和研究.
热传导算法是一个利用了复杂系统中热扩散思路计算物品相似度的推荐算法. 该算法的把用户和物品看做两类不同的点, 并把用户和物品的操作看做一条边连起来, 从而生成一个二分图. 算法假定每一个物品都分配了一定的能量, 然后沿着二分图的边, 进行能量的传递, 传递后的能量状态揭示了物品的相关程度.
算法原文探讨了两种能量传递的方法, 可以导出两种不同的物品相似度计算方式:
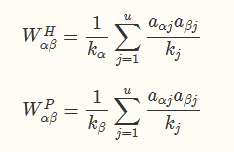
这里 α和 β是两个物品, aαi=1代表用户 i与物品 α有一条边, aαi=0表示没有. 而 ki=∑αaαi是用户的度, 即连接到用户的边的数目, 类似的 kα为物品的度.
可以看到两个相似度计算方式的差异主要在系数上. kα实际上计算了该物品被多少人操作过, 一定程度上代表了物品的热度. 因此 WαβP的计算方式很好的抑制了物品 α和热门物品的相似程度. 从而会让冷门的物品获得更高的关联得分.而真正的热传导模型, 则是通过引入控制参数 λ来实现兼顾精确度和多样性:
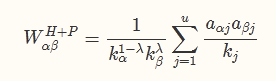
参考文献:
1、Zhou T, Kuscsik Z, Liu J G, et al. Solving the apparent diversity-accuracy dilemma of recommender systems[J]. Proceedings of the National Academy of Sciences, 2010, 107(10): 4511-4515. :leftwards_arrow_with_hook:
2、https://www.zybuluo.com/chanvee/note/21053 :leftwards_arrow_with_hook:
来源:腾讯QQ大数据
更多阅读:
