
1 问题
1.1 某业务拉新场景—冷启动决策问题
拉新场景是指在大流量业务场景中投放拉新业务的相关优质内容,从而吸引用户访问,快速增加用户量。这个拉新场景需要从4千+专辑池(每日会加入一些新的物品)中挑选出两个专辑投放给用户,使用这两个专辑来吸引新用户,从而达到拉新的目的。由于是投放给新用户,所以没有历史行为数据作为依据去推测该用户喜欢什么。能够依赖的数据包含专辑本身的特征,如:分类信息、更新时间等,用户的画像数据(达芬奇画像维护和挖掘了用户的基本画像数据),如:年龄、性别、地域等。开始时,我们使用传统的机器学习模型,如LR、FM等,将每日拉新用户量做到了5千-1.1万。这里存在的问题是,传统机器学习非常依赖正负样本的标注。对于某些新物品,如果它从来没有被曝光,那么它永远也不可能被标记为正样本,这对于新物品来讲是不公平的,也是推荐领域不愿看到的现象。一种比较直接的做法是,保留一股流量专门用来做新物品的探索,但是这里又会有一些新的问题产生,如:这股流量用多大?探索的时机该怎么把握?新物品中每一个物品曝光多少次、曝光给谁是最合适的?如何保证整体收益是最大的, 等等一系列问题,而MAB(Multi-armed bandit problem,多臂老虎机)方法正是解决这类决策问题的。所以我们尝试使用MAB的思想来解决新用户和新物品的推荐问题。事实证明,该方法是可靠的,使用MAB中的UCB算法之后,该拉新场景每日拉新量提高到最初base的2.3倍。
1.2 短视频推荐结果多样性控制
短视频推荐场景的特点是在保质的前提下,需要向用户推荐有创意、多样的、新鲜、热点等不明确讨厌的短视频。从直观的体验结合相关流水统计分析来看,用户非常反感连续推荐同一主题的短视频,所以需要使用一定的策略来对多样性进行控制,提高用户体验,尽可能把用户留下来。在腾讯内部某短视频推荐场景中,我们使用MAB中的Exp3算法来进行多样性控制。事实证明,Exp3用在探索新用户的兴趣场景下,与随机、Thompson sampling等方法对比,视频平均观看时长提升了10%,对于老用户增加了推荐结果的多样性,视频平均观看时长略有提升。
2 神盾如何解决拉新场景的冷启动问题
2.1 MAB如何解决决策问题
在说明神盾如何解决冷启动问题前,这里先对MAB问题做一个综述性的介绍。
什么是MAB问题?
MAB的定义非常有意思,它来源于赌徒去赌场赌博,摇老虎机的场景。一个赌徒打算去摇老虎机,走进赌场一看,一排排老虎机,外表一模一样,但是每个老虎机吐钱的概率可不一样,他不知道每个老虎机吐钱的概率分布是什么,那么想最大化收益该怎么办?这就是MAB(多臂赌博机)问题。怎么解决这个问题呢?最好的办法是有策略的试一试,越快越好,这些策略就是MAB算法。
推荐领域的很多问题可以转化为MAB问题,例如:
1. 假设一个用户对不同类别的内容感兴趣程度不同,那么我们的推荐系统初次见到这个用户时,怎么快速地知道他对每类内容的感兴趣程度?这就是推荐系统的用户冷启动问题。
2. 在推荐场景中,往往会有多个算法或模型在线上做A/B Test,一般情况下我们会把流量按照一定比率来进行分配,而在不同的时间点,不同的算法线上效果往往是不一致。我们期望每时每刻都能把占比大的流量分配给效果最好的算法。有没有比A/B Test更合适的流量分配方法来让业务的收益最大化?
可以看到全部都属于选择问题。只要是关于选择的问题,都可以转化成MAB问题。在计算广告和推荐系统领域,这个问题又被称为EE问题(Exploit-Explore问题)。Exploit意思是,用户比较确定的兴趣,要尽可能的使用。Explore意思是,要不断探索用户新的兴趣,否则很快就会越推越窄。
MAB的数学表述:
- A.设共有k个手柄(对应拉新场景中的k个专辑)
- B.k个手柄的回报分布<D1,D2,D3……Dk>(对应拉新中,专辑推荐带来的新用户量的分布情况)
- C.回报均值 u1,u2……uk(对应每一个专辑在以前的实验的平均收益)
- D.回报方差 v1,v2……vk(对应每一个专辑每一次实验收益的稳定性)
- E.最佳手柄平均收益
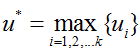
- F.T轮之后的Regret值 ,使用一定的算法策略使得其T轮之后最小
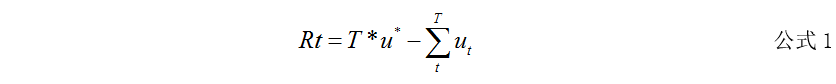
Rt是后悔值,T表示实验轮数,u*最佳手柄平均收益,ut表示t时刻,所选手柄的收益
MAB问题目前常用算法:
1. 朴素选择算法:其思想是对于每个手柄都进行k次实验,选择出平均收益最高的手柄。在之后的所有手柄选择中都选择这个最好的。
2. Epsilon-Greedy算法(小量贪婪算法):每一轮在选择手柄的时候按概率p选择Explore(探索),按概率1-p选择Exploit(历史经验)。对于Explore,随机的从所有手柄中选择一个;对于Exploit,从所有手柄中选择平均收益最大的那个。
3. Softmax算法:该算法是在Epsilon-Greedy算法的基础上改进的,同样是先选择是Explore(探索)还是Exploit(原有)。对于Exploit阶段,与Epsilon-Greedy算法一致。对于Explore,并不是随机选择手柄,而是使用Softmax函数计算每一个手柄被选中的概率。armi表示手柄i,ui表示手柄i的平均收益,k是手柄总数。
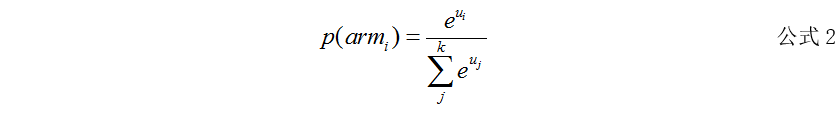
4. UCB(Upper Confidence Bound)算法:通过实验观察,统计得到的手柄平均收益,根据中心极限定理,实验的次数越多,统计概率越接近真实概率。换句话说当实验次数足够多时,平均收益就代表了真实收益。UCB算法使用每一个手柄的统计平均收益来代替真实收益。根据手柄的收益置信区间的上界,进行排序,选择置信区间上界最大的手柄。随着尝试的次数越来越多,置信区间会不断缩窄,上界会逐渐逼近真实值。这个算法的好处是,将统计值的不确定因素,考虑进了算法决策中,并且不需要设定参数。在选择手柄时,一般使用如下两个公式进行选择:
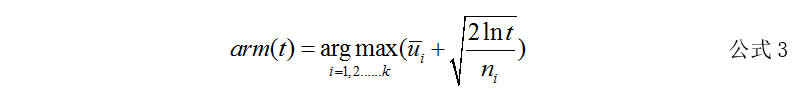
t表示t时刻或者t轮实验,arm(t)表示t时刻选择的手柄, ui均值表示手柄i在以前实验中的平均收益,ni表示手柄i在以前实验中被选中的次数。α是(0,1)为超参数,用以控制探索部分的影响程度。
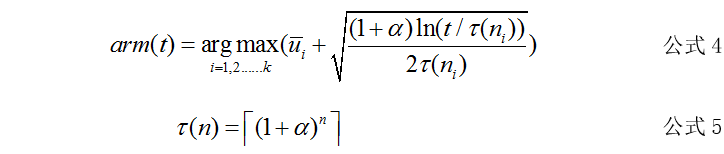
“选择置信区间上界最大的手柄”这句话反映了几个意思:
如果手柄置信区间很宽(被选次数很少,还不确定),那么它会倾向于被多次选择,这个是算法冒风险的部分。
如果手柄置信区间很窄(被选次数很多,比较好确定其好坏了),那么均值大的倾向于被多次选择,这个是算法保守稳妥的部分。
UCB是一种乐观的算法,选择置信区间上界排序。如果是悲观保守的做法,是选择置信区间下界排序。
5. Thompson sampling:该算法跟UCB类似,Thompson sampling算法根据手柄的真实收益的概率分布来确定所选手柄。假设每个臂是否产生收益,其背后有一个概率分布,产生收益的概率为p。不断地试验,去估计出一个置信度较高的概率p的概率分布就能近似解决这个问题了。 假设概率p的概率分布符合beta(wins, lose)分布,它有两个参数: wins, lose。每个臂都维护一个beta分布的参数。每次试验后,选中一个臂,摇一下,有收益则该臂的wins增加1,否则该臂的lose增加1。每次选择臂的方式是:用每个臂现有的beta分布产生一个随机数b,选择所有臂产生的随机数中最大的那个臂去摇。
以上算法优缺点:
1. 朴素选择算法需要为每一个手柄准备合适次数的实验,用以计算每个手柄的平均收益,并不适合物品快速迭代的场景,同时会浪费大量流量。
2. Epsilon-Greedy算法与Softmax算法有一个很明显的缺陷是它们只关心回报是多少,并不关心每个手柄被拉下了多少次。这就意味着,这些算法不再会选中初始回报特别低的手柄,即使这个手柄的只被测试了一次。而UCB算法,不仅关注回报,同样会关注每个手柄被探索的次数。Epsilon-Greedy and Softmax的特点,默认选择当前已知的回报率最高的手柄,偶尔选择那些没有最高回报的手柄。
3. Thompson sampling。UCB算法部分使用概率分布(仅置信区间上界)来量化不确定性。而Thompson sampling基于贝叶斯思想,全部用概率分布来表达不确定性。相比于UCB算法,Thompson sampling,UCB采用确定的选择策略,可能导致每次返回结果相同(不是推荐想要的),Thompson Sampling则是随机化策略。Thompson sampling实现相对更简单,UCB计算量更大(可能需要离线/异步计算)。在计算机广告、文章推荐领域,效果与UCB不相上下。
LinUCB算法:
以上介绍的MAB算法都没有充分利用上下文信息,这里所说的上下文信息包括用户、物品以及其他相关环境相关的特征。而LinUCB算法是在UCB算法的基础上使用用户、物品以及其他相关环境相关的特征来进行UCB打分。LinUCB算法做了一个假设:一个Item被选择后推送给一个User,其回报和相关Feature成线性关系,这里的“相关Feature”就是上下文信息。于是预测过程就变成:用User和Item的特征预估回报及其置信区间,选择置信区间上界最大的Item推荐,然后依据实际回报来更新线性关系的参数。
相关论文中(见附件)提出两种计算办法,这里将论文中算法伪代码贴出来,方便大家阅读,详情请查阅附件论文。


2.2 神盾推荐如何使用UCB来解决拉新场景推荐问题
神盾在UCB算法的基础上,尝试为其添加上下文环境信息,该环境信息主要包括用户画像、物品画像、环境信息(时刻,节假日,网络环境)等,因此将其命名为PUCB(Portrait Upper Confidence Bound)。该算法包括两部分,第一部分使用用户已有的行为数据生成物品在某些画像特征下的UCB得分(该分数综合考虑物品的历史平均收益和潜在收益)。第二部分使用预训练好的分类器,在对user-item pair打分时,将原有特征值替换为UCB打分,然后计算最终的打分。
UCB打分
数据准备阶段
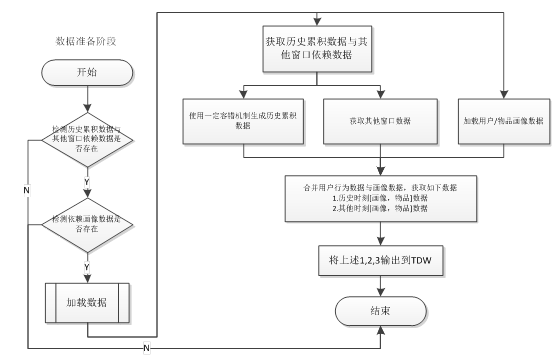
图 1 神盾PUCB-数据准备阶段示意图
该阶段的目的是确保使用用户行为数据和画像特征数据生成所需时间窗口下的【画像,物品ID,行为统计数】。这部分神盾在实现时,考虑了一些容错机制,如:当历史时刻数据不存在时,是否可以根据已有时刻的行为数据和已有时刻的【画像,物品ID,行为统计数】统计数据来重新生成等等。
统计打分阶段
使用公式6,基于时间窗口内的数据,采用一定的衰减策略来计算ucb分。对某一物品某种画像进行ucb打分。其中i表示物品ID,j表示画像特征MD5编码,cij 表示t时刻j特征编码的物品i的点击量,Cij 表示历史时刻j特征编码的物品i的点击量,λ表示新行为对得分的影响程度,λ越大表示最新行为越大,反之亦然,eij表示t时刻j特征编码的物品i的曝光量,Eij表示历史时刻j特征编码的物品i的曝光量,e为无意义初始值防止分母为0,Thj表示当前时刻j特征编码的物品总的曝光次数,Taj表示历史时刻和当前时刻所有专辑j特征编码的物品总的曝光数,α表示bonus项用于探索物品的权重,α越大越容易出新物品。
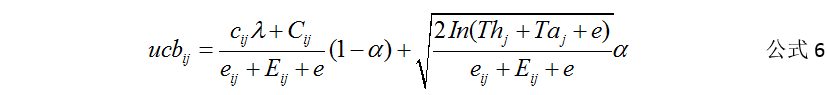
是否需要对Cij,Eij,Taj全部进行衰减,如下公式为计算历史数据的公式。d(t)表示t时刻的统计量,d’(i)表示i时刻的实际统计量,f(|t-i|)表示时间衰减函数,θ表示时间衰减参数,新时刻行为的影响越大,就应该跳大θ,反之亦然。
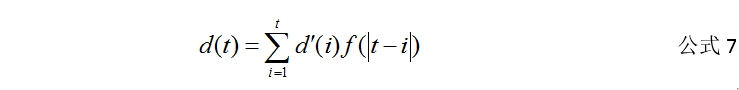
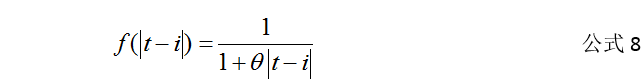
伪代码如下:
doStatistic()
Input: 历史时刻物品-画像曝光点击统计数据hisFirstItemPortraitStatis
(t-w+1, t)时刻物品-画像曝光点击统计数据otherItemPortraitStatis
isUseDefaultValue历史时刻数据是否使用默认值
toolItemID池子所有物品ID
Output: itemPortraitUCBScore ItemID,画像MD5的ucb得分
1 if isUseDefaultValue then
2 向hisFirstItemPortraitStatis补充缺失的物品曝光和点击数据(使用默认值)
3 hisRDD,realRDD←对hisFirstItemPortraitStatis,otherItemPortraitStatis分组合并统计
4 itemPortraitUCBScore ← 使用上述公式计算ucb得分
5 return itemPortraitUCBScore
分类器糅合UCB打分
经过上述处理之后,我们会得到图2所示信息,其中owner列为特征值,primary_key为历史实时行为标记,secondary_key为物品ID,value为统计到的次数。
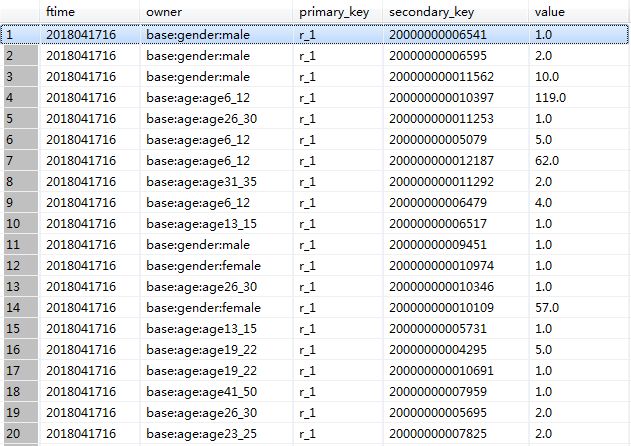
图 2 PUCB算法中间统计结果-示例图
换句话说,经过上述处理,我们将原始的特征抽象为UCB得分,接下来需要做的事情是使用一定的策略将不同维度的信息糅合起来。论文中使用了岭回归的方式来为每一个特征维度计算权重,神盾这里设计的比较灵活,可以使用任意一种分类器(如:LR、FM等)来糅合最终的结果,需要注意的是该分类器所使用的特征应该跟计算UCB打分的特征体系一致。
3
神盾如何保证短视频推荐场景中的多样性
3.1 exp3多样性保证
Exp3(Exponential-weight algorithm for Exploration and Exploitation)算法是2001年提出来的一种解决MAB问题的算法。它的核心思想是维护一组臂的权重信息,然后使用数学方法得到一组臂的概率分布,接着每次掷骰子去选择臂,根据选择后观察到的收益情况去调整臂的权重,如此迭代下去。论文中证明了使用这种策略能够保证后悔值的在一定可以接受的范围内,从而保证了结果不会是最坏的一种情况。
Exp3算法伪代码如下:

ϒ是一个超参数,值域为[0,1],可以采用固定值,在实验轮数确定的情况下,建议使用公式9来计算ϒ,其中K为臂的个数,T为实验的轮数。
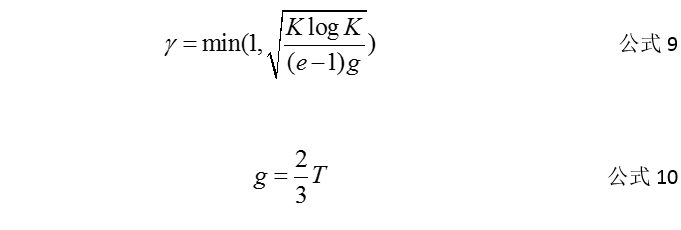
首先为每一个臂初始化权重为1,然后使用算法1步骤中的公式计算每一个臂的概率,该公式保证了所有臂的概率和为1,接着随机出一个[0,1]之间的值,观察该值落在哪个臂中,选择之后观察该臂的收益情况,使用公式11计算其预估收益。

使用公式12来更新权重。

该算法在计算臂的概率时,虽然有可能趋向于0,但是不会等于0,所以对于任意一个臂,都有机会被选中,只是收益高的臂更容易被选中,收益低的臂更不容易被选中。
3.2 神盾推荐如何应用exp3来做多样性控制
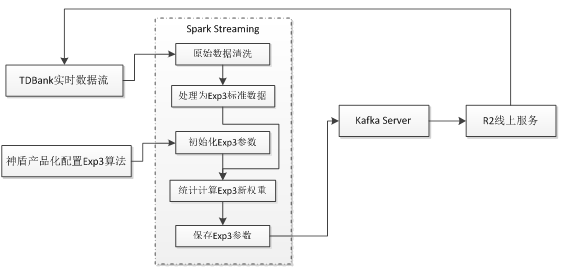
图 3 神盾Exp3算法流程
1. 首先规划Exp3的臂策略,最简单的臂策略为不同的召回策略,复杂一些可以按照一定的业务规则来对物品进行重分桶,如:在短视频推荐中按照物品类别信息(游戏、风景、美女等)构建了20+个臂。
2. 在tesla(腾讯内部集群任务调度系统)上配置Spark Streaming任务,这个任务的目的是分钟级消费TDBank业务数据,按照业务规则构建正负反馈数据,然后使用一定的更新策略来更新权重。神盾推荐在这里设计了三种权重更新策略。
a.原版算法更新策略,使用每条反馈数据来更新。这里存在的问题是由于TDBank数据收集,近线训练和线上服务链条较长,近线训练的结果不能非常实时的推送到线上去,存在一定的误差。
b.小batch更新策略,收集一段时间的数据(神盾使用1分钟的数据)对每个臂的收益值做归一化,然后更新算法参数。与a相比,优点是权重更新更加稳定,缺点是收敛速度相对比a缓慢。
c.在b的基础上引入窗口概念,会周期性的使用初始值来重置算法参数。
其他:在实际推荐业务场景中可以依照实际的应用情况,对正负反馈构建,权重更新策略,为每位用户构建Exp3选择器等。
3. 推送计算参数到Kafka Server,更新R2线上算法参数。
4. 神盾推荐在短视频推荐上应用Exp3的结构如下图所示,可以看到exp3被应用在ReRank层,每一个臂都可能被摇到,同时从数学角度保证整体选择的收益肯定远高于最坏情况,进而在保证多样性的同时,整体收益高于最坏收益。
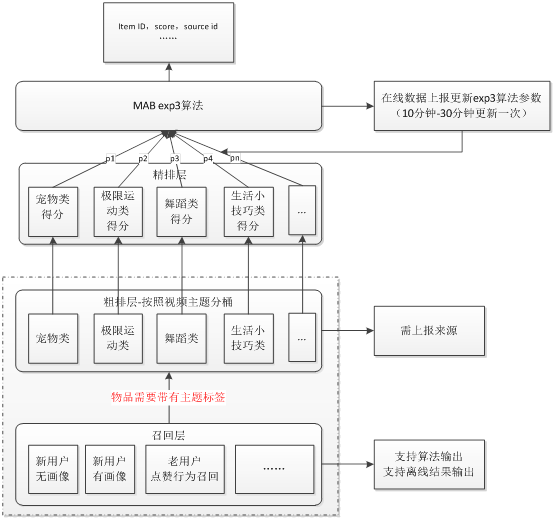
图 4 神盾推荐短视频推荐上Exp3算法结构示意图
4 总结
综合上述场景的实际应用情况,说明在面临用户或物品冷启动的情况时,值得使用PUCB的方法进行尝试,而内容类对多样性有要求的场景,可以尝试使用Exp3来解决。
本文所述MAB方法的经验来自组内所有同事在实际业务中的总结。欢迎大家交流讨论!
参考资料:
exp3数学推导: https://jeremykun.com/2013/11/08/adversarial-bandits-and-the-exp3-algorithm/
Python版demo:https://github.com/j2kun/exp3
https://zhuanlan.zhihu.com/p/21388070
//blog.csdn.net/scythe666/article/details/74857425
//x-algo.cn/index.php/2016/12/15/ee-problem-and-bandit-algorithm-for-recommender-systems/
Adversarial Bandits and the Exp3 Algorithm
来源:腾讯QQ大数据
更多阅读:
