
前言
自手Q游戏中心V6.0改版以来,产品形态发生了较大的转变,不再是纯粹通过app列表做游戏分发,而是试图通过内容来带游戏分发,全新的产品形态给推荐算法带来了许多的挑战。截至4月初,算法一期的工作已接近尾声,借此机会写下总结,一方面是将整个游戏中心的推荐逻辑进行梳理,并将其中的一些经验沉淀总结,方便回溯;另一方面也试图在梳理的过程中,整理出遇到的一些挑战,能够更加明确算法二期的一些迭代思路。
背景
手Q游戏中心作为腾讯手游重要的分发渠道之一,既是用户发现感兴趣游戏的重要入口,同时也提供了各手游平台运营的能力。新版游戏中心不再是纯粹地通过传统app列表的方式做游戏分发,而是新增了一系列通过内容(攻略、视频、直播、礼包等)拉下载、拉活跃的场景(如图1所示)。为了更好地提升用户进入游戏中心的体验以及满足平台精细化运营(拉新、拉活、拉付费等)的需求,通过海量用户的行为流水挖掘用户游戏偏好,精准推荐用户感兴趣内容成为了必然趋势。为此,我们设计了全新的个性化推荐框架,给业务带来了显著的转化率提升。
图1:游戏中心个性化推荐场景
为了更好地制定算法二期的迭代计划,本文主要对算法一期的工作做一个简单的复盘,一方面是将项目开展过程中的一些经验进行总结沉淀,另一方面也是想对游戏中心推荐场景中比较有挑战性的问题进行梳理,以便算法二期迭代过程中更加具有针对性。
本节主要结合游戏中心个性化推荐的算法框架(如图2所示)以及工程框架(如图3所示),对项目过程中遇到的一些问题进行总结归纳。游戏中心所采用的推荐框架是业界常见的三段式推荐逻辑:offline—nearline—online。离线层主要负责存储全量用户在游戏中心的流水数据、计算用户长期的行为属性以及训练用户的游戏偏好模型等;近线层主要是为了解决离线层计算周期长,响应速度慢的缺点,通过实时计算用户的短期兴趣,反馈到线上,从而能够对用户在游戏中心的行为做到实时反馈;在线层可以理解为推荐引擎,主要是对业务请求通过一系列的计算,返回最终的推荐结果列表,在线层可以细分为召回层—精排层—重排层结构。

图2:游戏中心个性化推荐算法架构图

图3:游戏中心个性化推荐工程架构图
- 离线层
离线层适用于用户长期兴趣的计算、离线模型的训练、模型参数的实验以及其他对时效性要求不高的任务,因此离线层主要采取HDFS+Spark的工程实现(批处理的计算方式)。业务数据通过DC或者TDBank上报,累计一定的数据量(游戏中心是以每小时为周期)周期性落地到HDFS或者TDW中以库表的形式存在,以Spark为计算引擎,对库表数据进行一系列处理后,将结果数据推送到线上存储,构成线上推荐引擎的重要数据来源。对于游戏中心这个场景,离线层的工作流可以划分为6大步骤:推荐物料的准备、数据处理、样本设计、特征提取、模型训练、数据上线。
1、推荐物料的准备
对于推荐系统来讲,第一个需要确定的就是推荐物料(也就是推荐池子)。游戏中心推荐的物品主要有两大类:第一大类就是游戏app,目前游戏中心接入算法的游戏app主要包括精品游戏、单机游戏,基本上每天变化不大,因此该类物料由业务每天例行上报更新并推送到线上存储即可。第二大类就是游戏内容了,主要包括攻略、视频、直播等,该类物料相对来讲实时性要求会高一些(新游上线当天需要内容同步更新)。目前游戏中心的内容来源数据链路如图4所示,主要来源是一些上游PGC内容的采购,经过自动Tag提取之后进入到标签内容库,算法侧直接从标签内容库获取推荐物料,目前是按小时更新。

图4:内容源数据链路
2、数据处理
熟悉推荐流程的同学可能比较清楚,数据处理过程繁琐枯燥且耗时较长,占据了整个算法开发周期60%以上的时间,贯穿整个开发流程。没入坑之前有些人可能会以为推荐算法工程师是一个高大上的职位,每天舒舒服服地看下paper,研究下算法,做下实验,特别酷。入坑之后就会发现,每天干的最多的活就是处理数据。但这也充分说明了数据处理的重要性,毕竟只有充分了解数据才能更了解业务,才能更加合理地设计你的推荐策略。这儿讲的数据处理主要包括数据验证、脏数据过滤以及数据转换等。下面主要总结一下在数据处理过程中所踩过的坑:
(1)一定要做好数据上报准确性的验证:前端同学有时候可能不是特别了解算法同学对于上报数据的诉求,所以在上报的时候可能会出现目标不一致的情况。常见的情况有:上报逻辑出错(分页feeds曝光只上报了第一条feeds的数据)、上报id错位(曝光的operid报了下载的数据),上报id缺失等。而验证数据上报准确性的常规操作就是打开游戏中心,将每个场景你有可能会用到的用户行为都操作一遍,记下操作时间,一个小时后从流水中捞出你的数据,逐一验证是否合理(噩梦)。
(2)推荐逻辑出现问题时候优先考虑数据的准确性:当推荐结果产生问题或者出现bug的时候,优先检查数据的准确性。模型的鲁棒性以及容错性一般都较高,最可能出现问题的往往是数据环节。通常都是沿着数据链路往上游逐步排查从而定位问题。
(3)对业务流水数据做一层数据中间表做解耦:算法开发过程中,最好不要直接操作operid相关的逻辑,遇上业务改上报id时(比如产品改版换了新的一套operid),改代码改的你头疼。
(4)算法接入后一定要跟产品以及前端同学再三确认算法ID的上报准确性:业务在调用推荐引擎时都会获得一个算法ID,算法ID上报的准确性直接影响效果监控报表的可信度。很多时候上了一个算法策略结果发现线上效果突然下降,排查半天才发现原来部分转化行为的算法ID上报缺失,所以这儿一定要仔细验证清楚。
(5)脏数据过滤是一门玄学:脏数据的定义通常需要根据业务场景来决定,有时候信心满满地将所有脏数据都过滤之后,线上效果反而降了,所以在过滤数据时要留个心眼(什么样才是脏数据?脏数据是不是一定没用?不要想当然,还是用线上效果说话吧!)。
(6)建立完善的报表监控体系:推荐的一个重要环节就是报表监控,不仅仅包括对效果的监控,还包括对池子的监控、核心用户的监控、item场景表现的监控等。只有建立完善的监控体系,才能在推荐结果受到挑战时快速定位问题。

图5:游戏中心报表监控体系
3、样本设计
一般来讲,推荐问题都会转换成二分类问题,也就是判断用户对某个物品是否会产生操作行为(通常一个U-I对就是一个样本),那么要训练出一个看起来合理线上效果又比较理想的二分类模型,正负样本的设计显得极其重要,下面总结一下游戏中心在设计不同场景的样本时的一些经验:
(1)如何正确定义正负样本?在纯icon推荐的场景,咋一看可以理解为用户下载了该app就是正样本,没有下载就是负样本。但仔细一想这样做会产生两个问题,第一个问题就是正负样本极其不均衡(机器学习中经典问题之一),因为用户浏览几十个app可能也就下载1个app,当然,机器学习针对正负样本不均衡问题会有很多解决方法,这儿就不展开描述了;第二个问题就是用户没有下载并不代表就是不喜欢,这儿会有几个值得推敲的地方:1)用户曝光了但是从没有产生过下载行为,可能因为是无效曝光,用户关注的焦点不在这,所以无法判断用户到底是喜欢还是不喜欢;2)用户在游戏icon曝光的场景并没有产生下载行为,但是用户产生了点击行为,从而进入到游戏详情页后产生下载行为,这样是不是可以认为用户其实是喜欢的,产生的也是正样本呢?举这么个例子主要是为了说明,对于每个不同的推荐场景来说,正负样本的设计都应该充分结合业务特性,不然容易产生有偏样本。
(2)设计样本时应保证每个用户样本数的均衡:在app分发或者内容分发场景,容易存在一些刷量用户;该批用户频繁进入游戏中心从而产生多次操作行为,因此在设计样本时应对多次操作的U-I样本对去重,并保证每个用户样本数的均衡,从而避免模型被少数用户所带偏。
(3)样本权重的设计问题:在feeds推荐的场景中,不同推荐槽位所产生的样本权重应该有所不同;比方说首页feeds场景,用户刚进入场景时,注意力会比较集中,产生的负样本应该置信度较高,权重也较高;当用户下滑到后面feeds的时候,对feeds的内容可能会比较乏味了,产生的正样本置信度应该也是较高的,权重应该也设置较高。
(4)适当丰富样本来源的多样性:一般样本都是基于当前场景所产生的用户行为来选取的,而当前场景用户的行为某种程度是受推荐结果而影响的(“你给我推荐了王者荣耀,那么我只能喜欢王者,但是可能我更喜欢你没给我推的吃鸡呢”),随着算法的迭代,越到后面,算法其实是在迭代自身,越学越窄,这也是推荐系统经典的多样性问题。youtube所采用的一种缓解的方法就是从其他没有算法干扰的场景选取部分样本,来避免这个问题,而在游戏中心的样本设计中,都会单独开设一股没有算法干扰的小流量作为干净样本的补充。
4、特征提取
特征决定机器学习的上限,而模型只是在逼近这个上限。可想而知,特征设计的重要程度是多么的高。关于特征设计的方法论有很多,这儿就不具体讨论。这里主要介绍一下游戏中心各个场景在设计特征时候的通用思路以及为了解决首页feeds特征空间不一致时所采用的多模态embedding特征。
(1)通用特征设计思路:如图6所示。这儿需要提一下的是,游戏中心的推荐场景由于涉及平台利益,所以一般情况下,特征设计时都需要考虑特征的可解释性。
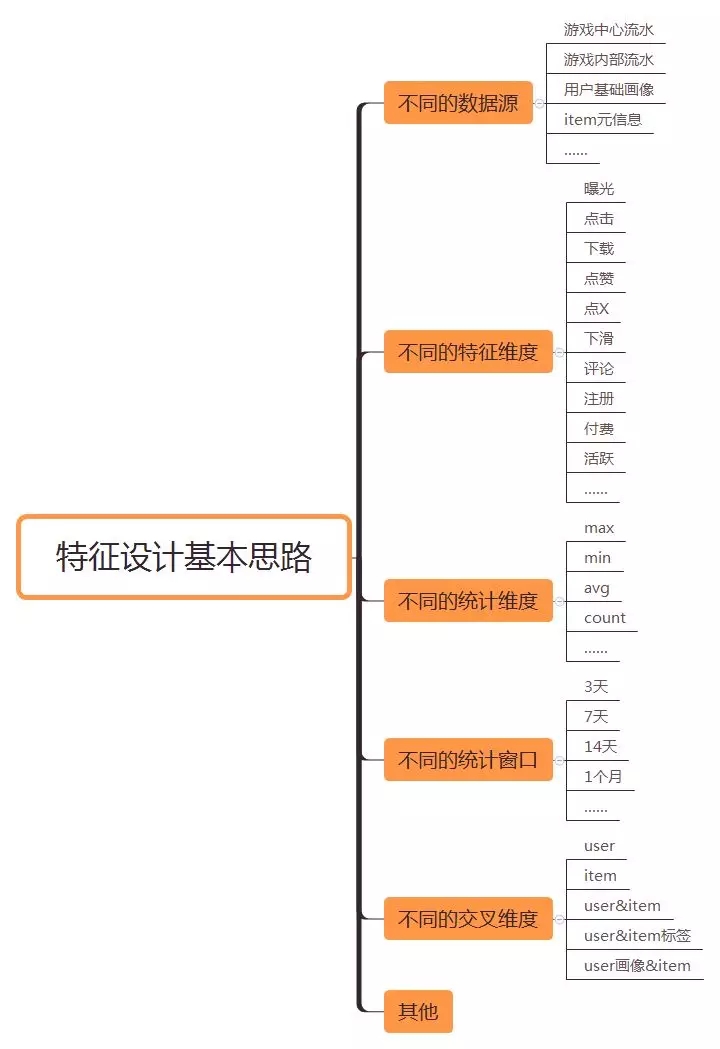
图6:特征设计思路
(2)多模态embedding特征向量:首页feeds流分发场景是一个具有挑战性的场景,其中一个比较有意思的难题就是待推荐的内容类型较多。传统的feeds推荐场景要么都是纯视频流、要么是纯文字feeds等,而游戏中心首页这儿待推荐的内容类型有攻略、视频、直播、活动、礼包等,而且每一种内容类型的二级承载页产品形态也不一致,这样会导致可提取的特征空间维度不一致。比方说视频承载页的观看时长与图文承载页的观看时长量级不一致,视频承载页有icon点击等操作而图文承载页则没有。特征空间的不一致会导致模型在打分的时候会有所偏颇,离线实验过程中发现视频由于特征维度较齐全,打分结果整体偏高。因此,为了减缓特征空间维度不一致问题,游戏中心首页feeds流引入了多模态embedding特征向量,该方法在企鹅电竞视频推荐场景已经取得了较好的效果(如图7所示)。多模态embedding特征向量的设计主要参考youtube的论文,从而获得每个user、item的低维特征向量,一方面解决item的原始特征空间维度不一致问题,另一方面也根据用户的历史行为,学习user、item的隐语义特征维度,起到信息补充的作用。
 图7:多模态embedding网络
图7:多模态embedding网络
5、模型训练
好了,终于到了别人所认为的高大上的步骤了——模型训练,其实一点都不高大上,尤其是有了神盾推荐这个平台。目前神盾推荐离线算法平台已经集成了大部分常见的推荐算法,包括LR,Xgboost,FM,CF等,因此离线训练只需要准备好样本跟特征,配置好参数,就可以一键点run喝咖啡了(开玩笑开玩笑,是继续搬下一块砖)。傻瓜式的模型训练(调包侠)其实并没有太大的坑,但是有几点经验也在这稍微写一下哈:
(1)注意调参的正确姿势:目前神盾默认是将数据集划分为train跟test,如果盯着test数据集的指标来调参的话,是很有可能出现线下高线上低的情况。因为盯着test指标进行调参的话容易加入个人先验,本身就是一种过拟合的操作,正规的操作应该是将数据集划分为train-test-validation。
(2)同样的业务场景建议共用一个大模型:新版游戏中心目前有9个场景需要算法接入,如果每一个场景都单独建模的话,一来维护成本高,二来浪费人力。适当对场景问题进行归纳,训练通用模型可以有效地节省开发时间。比如说首页分类列表推荐,游戏Tab的热游列表推荐等,其实都是纯icon的推荐,可以用统一的大模型来建模。通用模型首先要考虑的问题就是样本、特征的选取,样本可能比较好设计,汇总所有场景的样本即可,最多就是根据场景特性设计不同的权重;而特征就需要好好斟酌,是分场景提取特征还是汇总后提取、不同场景特征维度不一致如何处理等。
(3)选择合适的机器学习方案:目前首页feeds是将排序问题转化为二分类问题,评估指标选取的是auc,所以优化的重点在于尽可能地将正负样本区分开(正样本排在负样本前面),但对于正样本之间谁更“正”却不是二分类模型的关注重点。神盾近来已经支持pari-wise的LTR算法,可以解决任意两样本之间置信度问题,后续可以在首页feeds场景上做尝试。
(4)选择合适的优化指标:对于视频瀑布流场景,优化的目标可以有很多,比如人均播放个数、播放率、人均播放时长,具体需要跟产品同学沟通清楚。
(5)避免对分类问题的过度拟合:前面已经提过,在推荐场景,经常将推荐问题转化为分类问题来处理,但是需要注意的是,推荐问题不仅仅只是分类问题。分类问题是基于历史行为来做预测,但推荐问题有时候也需要考虑跳出用户历史行为的限制,推荐一些用户意想不到的item,因此,推荐是一个系统性问题,应当避免过度拟合分类问题。
6、数据上线
数据上线可以说是推荐系统中较为核心的环节,其中会面临很多难题。这儿的数据主要指的是离线计算好的物料数据、特征数据(用户、物品)、模型数据等。目前神盾会周期性地对需要上线的数据出库到hdfs,通过数据导入服务推送到线上存储,主要是grocery(用户特征)跟共享内存ssm(物品特征以及池子数据等查询较为频繁的数据)。目前这儿会有几个小问题:
(1)数据的一致性问题:离线模型在训练的时候,会对样本数据跟特征数据做拼接,通常都是将当前周期的样本跟上一周期的特征做拼接,以天为例,也就是今天的样本会跟昨天的特征数据做拼接。但是离线数据的计算以及上线是会有时间延迟的,尤其是特征数据。有可能今天的凌晨0点到5点,线上所拉到的特征数据其实是前天的特征数据,5点之后,昨天的特征数据才计算完并更新到线上。也就是说凌晨5点之前,所产生的推荐结果其实是用前天的特征数据来计算的,那么离线训练的时候,拼接的特征数据就会与实际的数据不一致。
(2)数据的实时性问题:前面也讲了,业务数据一般会周期(按小时)落地到hdfs或者tdw以库表形式存在,基于spark进行数据处理之后又推送到线上存储,这种复杂的数据处理链路导致数据时效性得不到保证(频繁地数据落地以及数据上线所导致)。因此,离线层仅适用于对数据时效性不高的任务,比如长期兴趣的计算等。
- 近线层
前面已经提到,离线层在数据时效性以及数据一致性的问题上面临较大的挑战。本质上是由于数据频繁落地以及上线导致的延迟所引起的,给游戏中心推荐带来较大的困扰。企鹅电竞也面临同样的问题,因此,两个业务联合设计了近线层(如图8所示)。目前整个数据链路已经打通,并且也在企鹅电竞业务上试点成功。整个框架是基于kafka+spark streaming来搭建的,目前主要实现两个功能点:实时特征的提取以及实时样本特征的拼接。由于近线层不需要落地以及线上导数据服务,而是直接对业务流水进行操作后写入线上存储,因此耗时较少,基本可以做到秒级别的特征反馈,解决了离线层计算周期长的缺点,适用于用户短时兴趣的捕捉。
实时样本特征的拼接主要是为了解决数据一致性问题。离线层对样本、特征进行拼接的时候一般都是默认当前周期样本拼接上一周期的特征,当由于特征上线的延迟,有部分当前周期样本的产生其实是由t-2周期的特征所导致,因此为了保证训练数据的准确性,我们在近线层设计了实时的样本特征拼接。当用户请求时,会带上读取的特征数据,拼接到用户的操作流数据上,构成离线层的训练数据。
 图8:近线层功能逻辑
图8:近线层功能逻辑
- 在线层
在线层是推荐系统的关键环节,直接影响最终的推荐结果。一般分为召回层,精排层、重排层(或者是matching、ranking、rerank)。召回层一般是起到粗筛的作用,对于内容推荐来说,推荐的池子一般都是上万级别,如果直接进行模型打分的话,线上服务压力会比较大,因此,通常都会采用各种召回的策略来进行候选集的粗筛。目前游戏中心所采用的召回策略主要有标签、热度、新鲜度、CF等。精排层所干的事情就比较纯粹了,一般就是模型加载以及模型打分,对召回的物品进行一个打分排序。最后就是重排层,主要是对模型打分结果进行一个策略的调整。游戏中心的重排排层主要有以下几个逻辑:1)分类打散:首页feeds在推荐的时候,如果只由模型进行打分控制的话,容易出现游戏扎堆的现象,也就是连续几条feeds都是同款游戏,因此需要重排层来调整展示的顺序;2)流量分配:游戏的分发涉及平台的利益,每款游戏的曝光量会影响平台的收入,因此需要合理分配每款游戏的展示量;3)bandint策略:主要是用于兴趣试探,feeds场景会涉及多种内容类型,如何在推荐用户历史喜欢的内容类型以及尝试曝光新的内容类型之间做平衡是推荐系统典型的E&E问题,这儿我们设计了一个简单的bandint策略,下面会详细讲一下。4)运营策略:一些偏业务性质的运营策略也会在重排层体现。
推荐系统中会遇到一个经典的问题就是Exploitation(开发) VS Exploration(探索)问题,其中的Exploitation是基于已知最好策略,开发利用已知具有较高回报的item(贪婪、短期回报),而对于Exploration则不考虑曾经的经验,勘探潜在可能高回报的item(非贪婪、长期回报),最后的目标就是要找到Exploitation & Exploration的trade-off,以达到累计回报最大化。对于游戏中心首页feeds而言,一味推荐用户历史喜欢的内容类型或者大量尝试曝光新的内容类型都是不可行的;首先用户的兴趣可能会有所波动,过去可能喜欢视频类型,但是下一刻就可能不喜欢了;其次一味推荐用户历史喜欢的内容类型,可能会让用户产生厌倦。为了平衡两者之间的关系,我们在重排层设计了一个简单的策略,具体如图9、图10所示。
 图9:游戏中心bandit策略算法逻辑
图9:游戏中心bandit策略算法逻辑
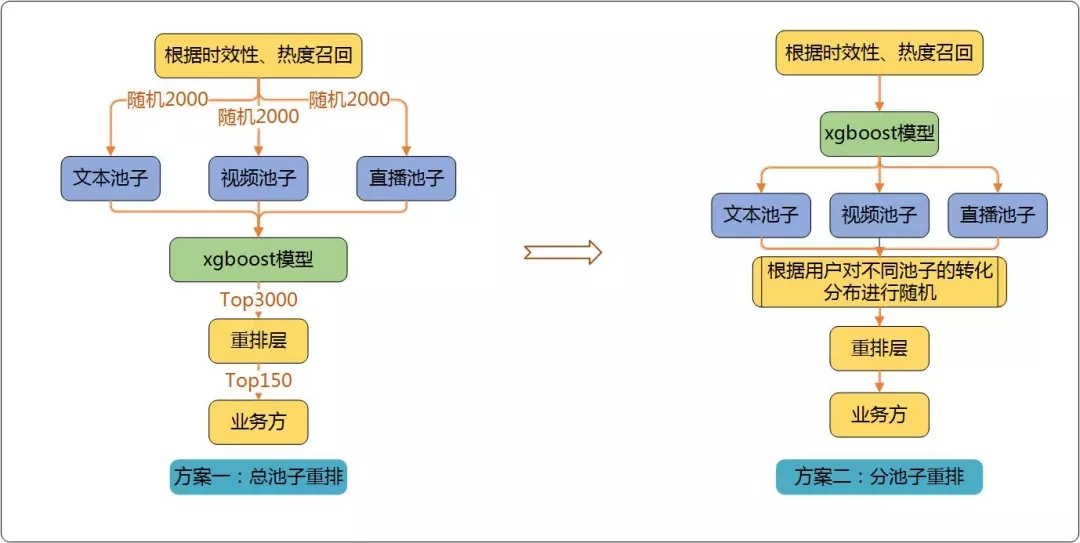 图10:游戏中心bandit策略具体实现
图10:游戏中心bandit策略具体实现
目前游戏中心个性化推荐所遇到的难点以及下一步的迭代计划主要如下:
1、外部数据的引入:1)结合第三方数据做推荐:目前游戏中心个性化推荐的依据主要是用户的场景表现、游戏内表现以及一些基础的画像数据,数据来源较为单一。引入更多的第三方业务数据(比如企鹅电竞),一方面可以丰富用户的特征维度,另一方面可以给用户带来体验上的提升(用户刚在企鹅电竞看了个吃鸡的直播,来到游戏中心就给推荐了“刺激战场”)。2)丰富推荐物料:目前游戏中心的内容来源部分存在“同质化”现象,素材类型还不是特别丰富,需要引入更多优质的外部内容。
2、多模态特征提取:游戏中心的推荐内容类型较为丰富,包括了视频、图文、活动、礼包等,如何在同一个特征向量空间对各个item进行信息抽取是目前遇到的难题之一。现有的解决方案是基于youtube的embedding网络进行user、item的embedding向量学习。该网络的输入是无序的,也就是没有考虑用户历史行为的轨迹,那么是否可以用图来表示行为的轨迹,基于graph embedding的方法获得信息更加丰富的item向量?目前业界也有若干基于graph embedding的推荐案例(手淘首页 、阿里凑单 )。
3、内容元信息的提取:目前游戏中心对于item的特征提取要么是基于统计的特征,要么就是基于item历史行为的embedding特征或者tag提取,对于内容本体信息的提取还较为薄弱,如何有效地提取非结构化内容的信息是下一步迭代需要考虑的问题。
4、模型的快速更新:对于用户兴趣的实时捕捉,不仅依赖于数据的实时更新,同样依赖于模型的实时更新。目前线上的模型是按天例行更新,如何快速地训练模型以及部署模型是后续不可避免的问题。
5、优化指标考虑收入相关因子:当前的优化指标基本是转化率、时长等推荐系统常见的指标,但游戏中心涉及平台收入,需要综合考虑每个游戏的收益(类似广告系统中的竞价)。如何设计合理的优化指标(考虑游戏arpu、ltv等)以及在用户体验跟平台收入之间做平衡也是下一步迭代的关键。
6、流量分配问题:首页feeds场景既涉及游戏流量的分配,也涉及内容类型流量的分配,如何有效地设计流量分配方案,从而减轻重排逻辑的负担也是需要考虑的优化点。
7、拉活还是拉新:如何根据用户在游戏生命周期的不同阶段推荐合适的内容是首页feeds场景需要考虑的问题。
8、新品试探:目前我们只是在内容类型上做了一些简单的策略,后续还需要调研更加成熟的解决方案来解决E&E问题。
总结
本文主要是对游戏中心在算法一期的接入过程所遇到的问题做一些总结,以及梳理下一步迭代的计划。由于算法一期的重心在于算法的快速接入,因此整个个性化推荐框架中所涉及到的策略可能都略显“着急”,希望各位同行大佬多多包涵。关于游戏中心推荐问题,欢迎随时交流。
来源:腾讯QQ大数据
更多阅读:
