
目前,某产品营收运营正处在从过去依赖产品经理的经验到通过数据来驱动增长(Growth Hacking)的过渡期。在这里梳理一下通过数据模型帮助该产品营收的一些经验。
正文
本文主要包括7部分:定义目标:转化为数据问题、样本选择、特征搭建、特征清洗、特征构造、特征选择、模型训练与评估。如图1下:
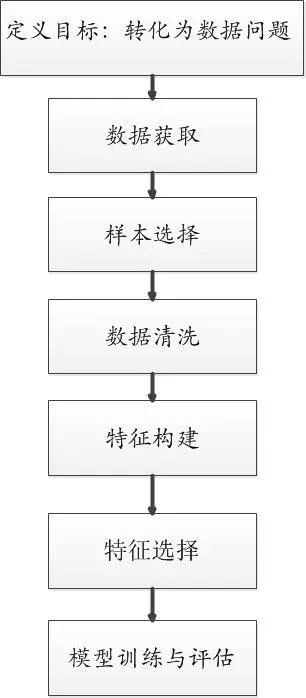
图1
一、定义目标:转化为数据问题
营收活动就是要从大盘中找出那些响应活动的高潜用户,这实际上是一个有监督的分类问题。通过训练集找出典型的响应用户特征,得到模型。再将模型用于实际数据得到响应用户的分类结果。这里选择逻辑回归(Logistic Regression)。为什么是逻辑回归?因为逻辑回归鲁棒性好,不容易过拟合,结果便于解释,近些年有很多新的算法可能分类效果会更好,但很多前辈的经验表明,精心做好特征准备工作,逻辑回归可以达到同样好的效果。
二、数据获取
特征主要包括画像和行为数据,画像数据最稳定且易获取,行为数据预测能力最强。基础特征包括画像数据(取自达芬奇)、特权操作、平台操作、历史付费行为、QQ和空间活跃等共计236个特征。
三、样本选择
选择最具代表性的样本,如果样本倾斜严重,则进行抽样,保证正样本比率不低于10%。
训练样本的选择决定模型的成败,选择最能代表待分类群体的样本。最佳选择是用先前该活动的数据做训练集,如果是新的活动,用先前相似的活动数据。
有时遇到这样的情况,先前活动的号码包是通过模型精选出来的,通常,这些号码包不是整体的有效代表,不能直接用来做为新的模型的训练样本,当然如果这些号码包占整体用户的80%以上基本就没问题。一种解决办法是随机选取样本投放活动等待响应结果来构建模型,这种方法比较耗时耗力,通常不用;另一种方法是抽取部分未投放的号码标记为非响应群体,这样构建的模型虽然不是效果最优的,但却能提升模型的泛化能力。
样本多大合适?没有标准答案,一般来说特征越多,需要的样本越大。我们建模一般有上百的特征,训练样本会选择几十万数据级。
当前计算机的计算能力已经提高了很多,抽样并不是必须的,但抽样可以加快模型训练速度,而且用单机来做模型的话,抽样还是很有必要的。通常目标用户的占比都很低,比如该产品某次活动的目标用户占比只有1‰,这样数据是严重倾斜的,通常做法是保留所有目标用户并随机抽取部分非目标用户,保证目标用户占比大于10%,在该产品营收模型训练中,一般用目标用户:非目标用户=1:4。
四、数据清洗
了解数据特性是保证优质模型的第一步。数据清洗是最无聊最耗时但非常重要的步骤。包括脏数据、离群数据和缺失数据,这里了解数据的先验知识会有很大帮助。用箱线图来发现离群点,这里关于数据的先验知识会有很大帮助。如果变量太多,不想花太多时间在这个上面,可以直接把脏数据和离群数据处理成缺失值。对于缺失值,先给缺失值建一个新变量来保留这种缺失信息,连续变量一般用均值、中位数,最小值、最大值填充。均值填充是基于统计学中最小均方误差估计。如果数据是高度倾斜的话,均值填充是较好的选择。或用局部均值填充,如年龄分段后所属年龄段的均值。还可以用回归分析来填充,实际中用的比较少。分类变量一般用频数填充。
五、特征构造
已经有原始特征,为什么要进行特征构造?特征构造的必要性主要体现在发现最适合模型的特征表现形式。
清洗工作之后,就可以进行特征构造了,主要有3种特征构造方法:汇总、比率、日期函数。
- 汇总:如按天、周、月、年汇总支付金额,近三天、近7天、近14天、近21天、近31天听歌/下载次数,统计用户近一年累计在网月份等。
- 比率:曝光点击转化率、曝光支付转化率、点击支付转化率、人均支付金额、次均支付金额。
- 日期衍生:首次开通服务距现在时长、最近一次到期时间距现在时长,到期时间距现在时长。
- 转换特征:对原始连续特征做平方、三次方、平方根、立方根、log、指数、tan、sin、cos、求逆处理。然后从所有转换中选择2个预测性最好的特征。实际中,使用最多log处理。
逻辑回归本质上是线性分类器,将预测变量尽量线性化,虽然我们的特征有连续变量和分类变量,模型训练时会把所有变量当做连续变量。
连续变量可以直接用来训练模型,但分段会使得变量更具有线性特征,而且可以起到平滑作用,经验表明分段后的特征会提升模型效果。分段一般依据经验划分或先分为均等10段然后观察各段中目标变量占比来确定最终分段。如年龄分段主要基于常规理解,分为幼儿园、小学、初中、高中、大学、硕士、博士、中年、壮年、老年。
六、特征选择
特征选择的目的是要找出有预测能力的特征,得到紧凑的特征集。
特征成百上千,对每一个变量进行深入分析并不是有效的做法,通过相关系数和卡方检验可以对特征进行初步筛选。相关性强的特征去掉其一,对每个特征进行单变量与目的变量间的回归模型,如果卡方检验小于0.5,说明预测能力太弱,去掉该变量。
做过初步变量筛选后,用剩余变量训练模型,根据得到的回归系数和p值检验,剔除回归系数接近0和p值大于0.1的特征,得到最终用于建模的特征集。
特征多少个合适?这个没有标准答案,主要原则是保证模型效果的同时鲁棒性好,并不是特征越少,鲁棒性越好。主要取决于市场,如果市场比较稳定,变量多一些会更好,这样受单个变量变动的影响会较小;当然如果想用用户行为来预测未来趋势,变量少一些比较好。对我们做营收增长来说,模型特征尽量简化,这样便于从业务角度进行解读,便于跟老板和产品同事解释。
七、模型训练和评估
前面花了大量时间来确定目标、准备特征、清洗特征。使用一些简单的技术来过滤一些预测性弱的特征。接下来,用候选特征来训练和验证模型。
模型实现步骤:
1、 通过挖掘算法获取不同群体的差异特征,生成模型用于分类。
2、 待分类用户群通过分类器筛选出目标人群,形成标识和号码包。
3、 用户号码包通过渠道进行投放,营销活动正式在外网启动。
4、 收集曝光、点击、成交数据用于评估模型效果,明细数据用于修正模型的参数。
5、 重复1——4
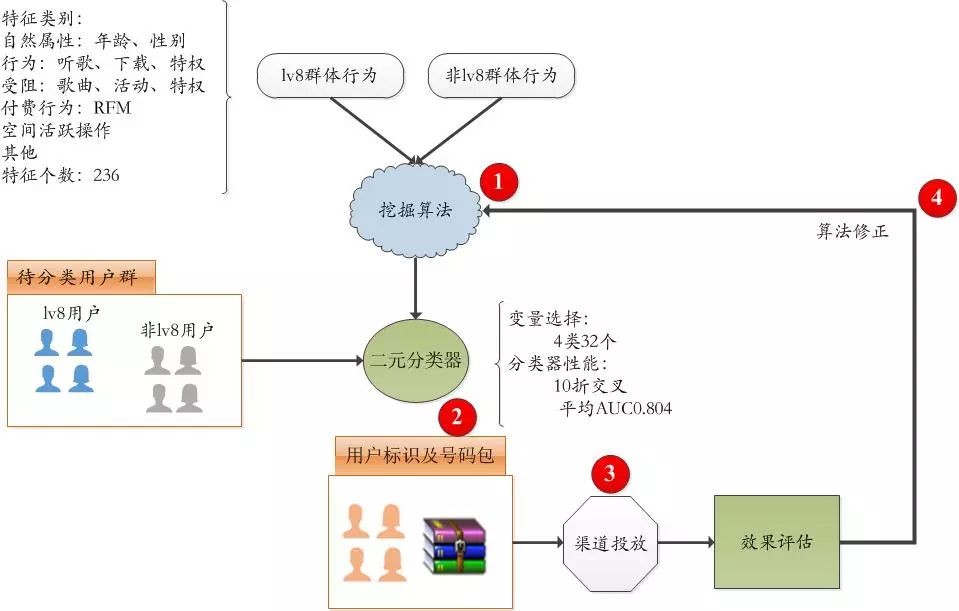
图2
另外,活动投放参见组选择很有必要,一般是依据产品经验或随机选取,参照组的效果一般不如模型选择的,这会导致收入有所减少,有时很难说服产品,但对于对比、监控和检验模型效果来说很有必要。
该产品营收依据模型精细化运营以来,收效显著,支付转化率提升30%~150%。
最后致上一句名言:Your model is only as good as your data!
参考文献
[1]. OP Rud. Data mining cookbook: modeling data for marketing, risk, and customer relationship management. 2001
[2]. https://zh.wikipedia.org/wiki/逻辑回归
来源:腾讯QQ大数据
更多阅读:
