
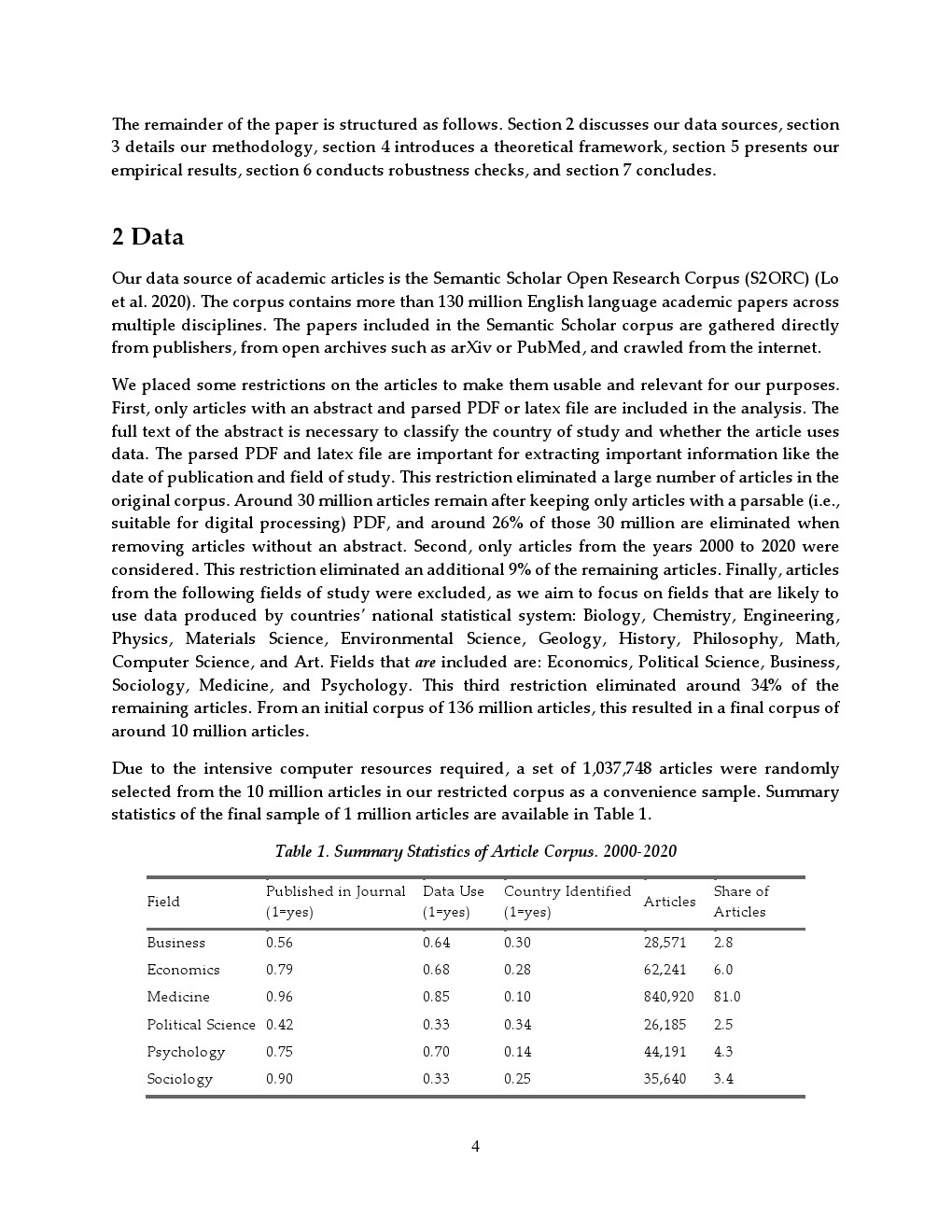
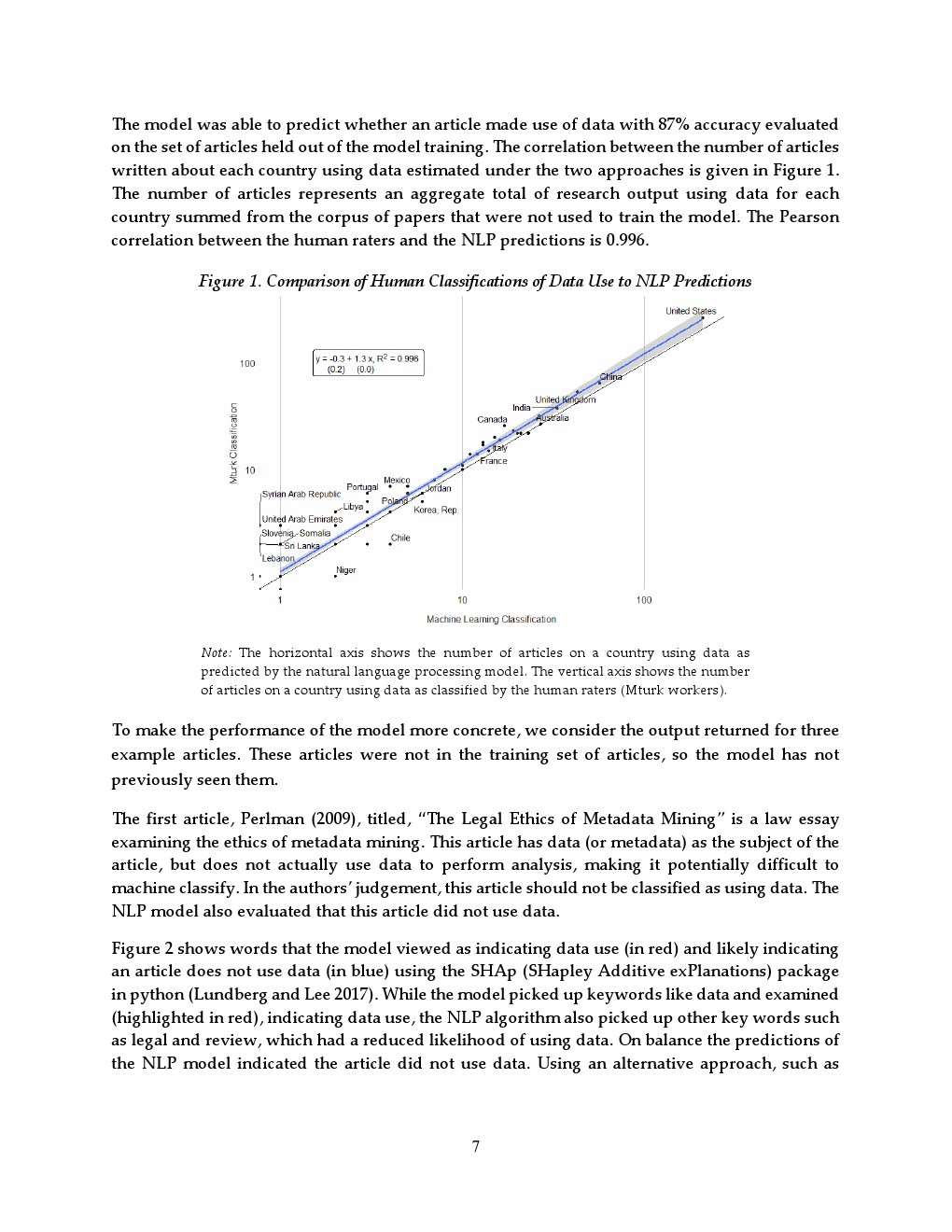
基于对超过100万篇学术论文的分析,该研究构建了一套利用自然语言处理识别“数据驱动研究”的方法,其分类准确率达到87%,国家层面与人工标注结果的相关性高达0.99,显著提升了对全球研究数据使用情况的量化能力 。这一方法突破了传统文献计量的局限,使研究者能够系统识别哪些国家被数据研究覆盖、哪些仍处于“证据盲区”。
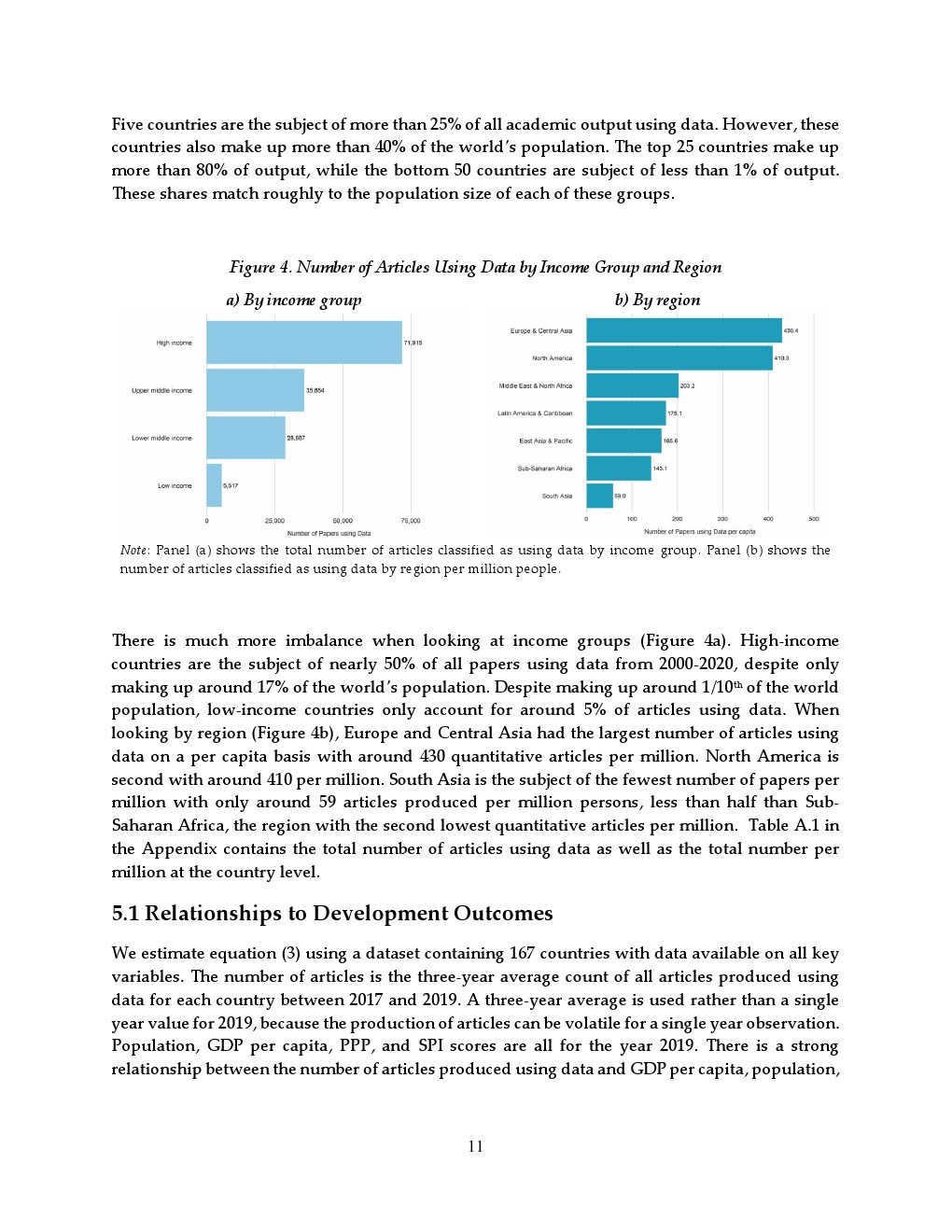
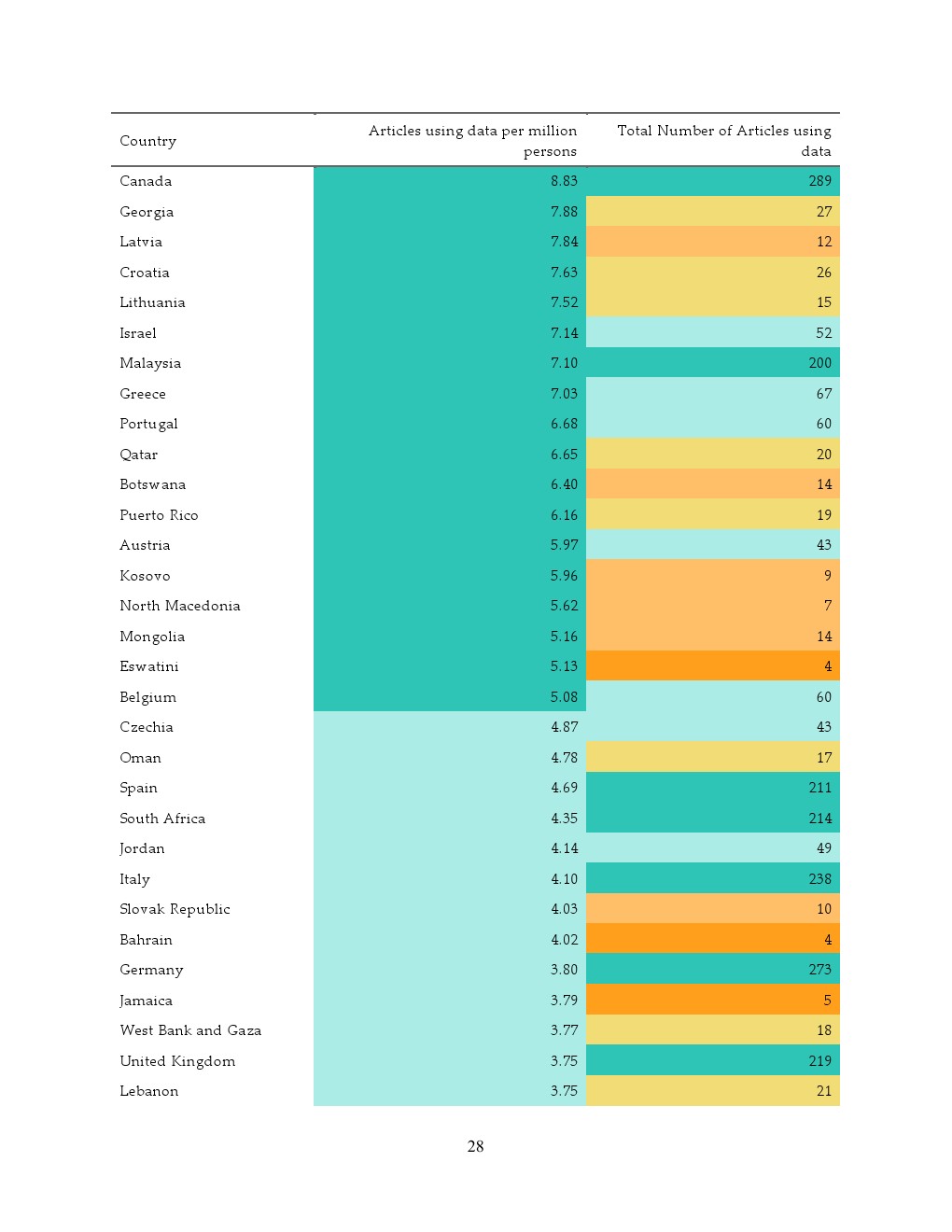
从全球分布看,数据驱动研究呈现明显集中趋势。2000至2020年间,美国和中国分别以约12273篇和12063篇位居前两位,印度、澳大利亚、日本紧随其后 。前五个国家贡献超过25%的研究产出,而前25个国家占比超过80%,底部50个国家合计不足1%。这一结构与人口规模大体匹配,但在收入维度上出现显著偏离,高收入国家占全球论文约50%,却仅占人口约17%,而低收入国家人口占比约10%,论文占比仅5%。
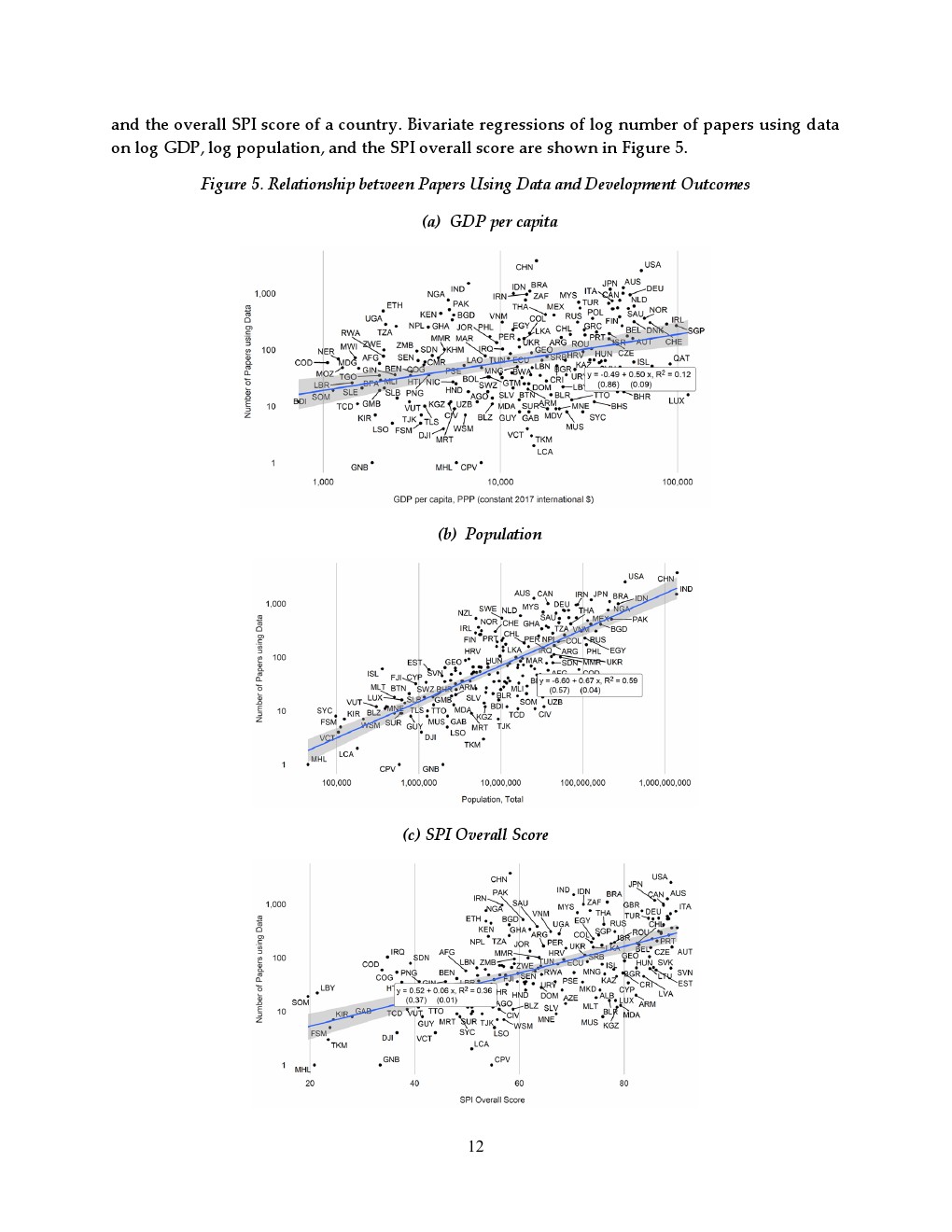
进一步分析显示,经济规模与人口是决定研究覆盖的核心变量。GDP与人口共同解释了约75%的国家间差异,其中GDP弹性约为0.5,即经济规模每增长10%,数据论文数量增加约5%;人口弹性约为0.67,是更强解释变量。与此同时,统计体系能力同样关键,统计绩效指标每提高10分,可带来约0.2%至0.6%的研究增长,说明数据基础设施直接影响知识生产能力。
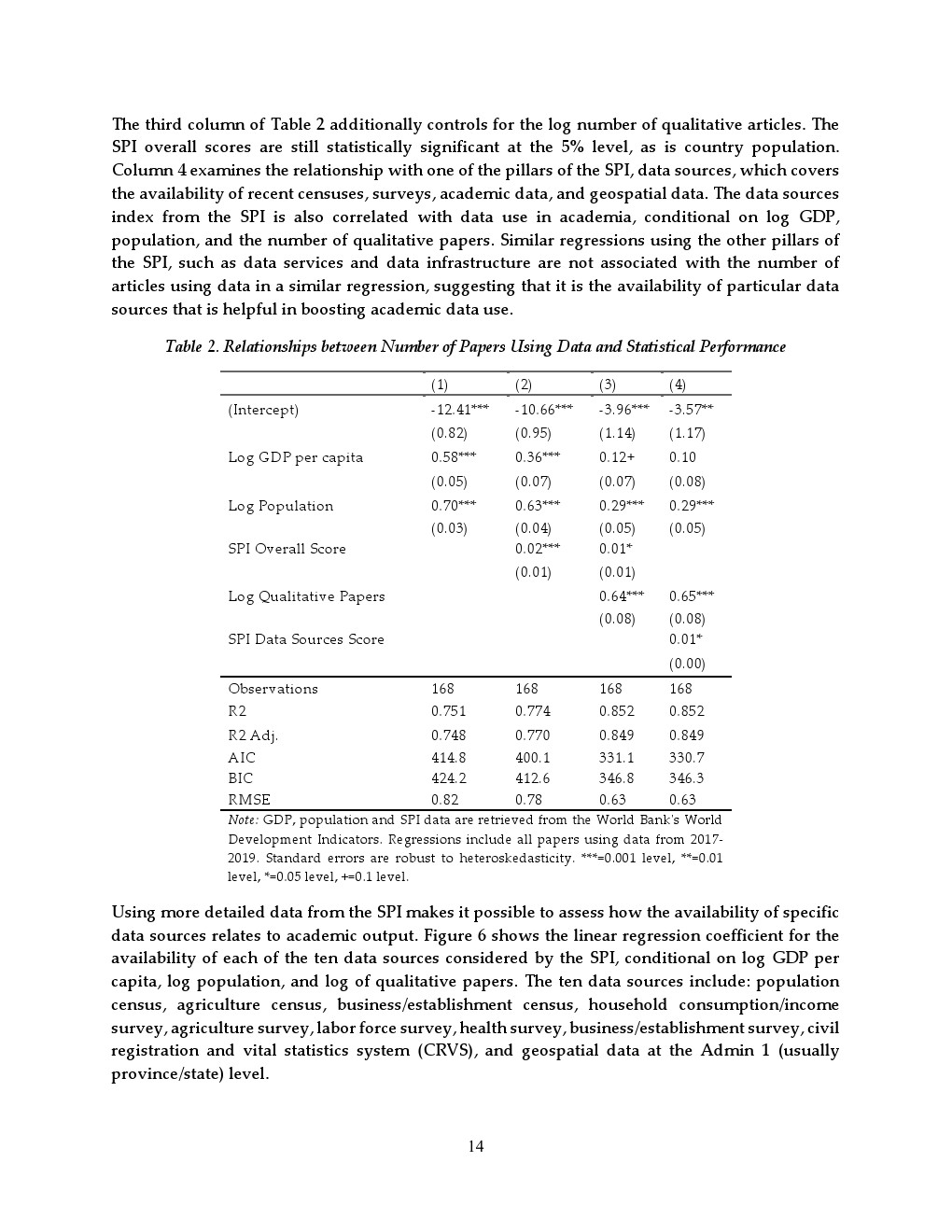
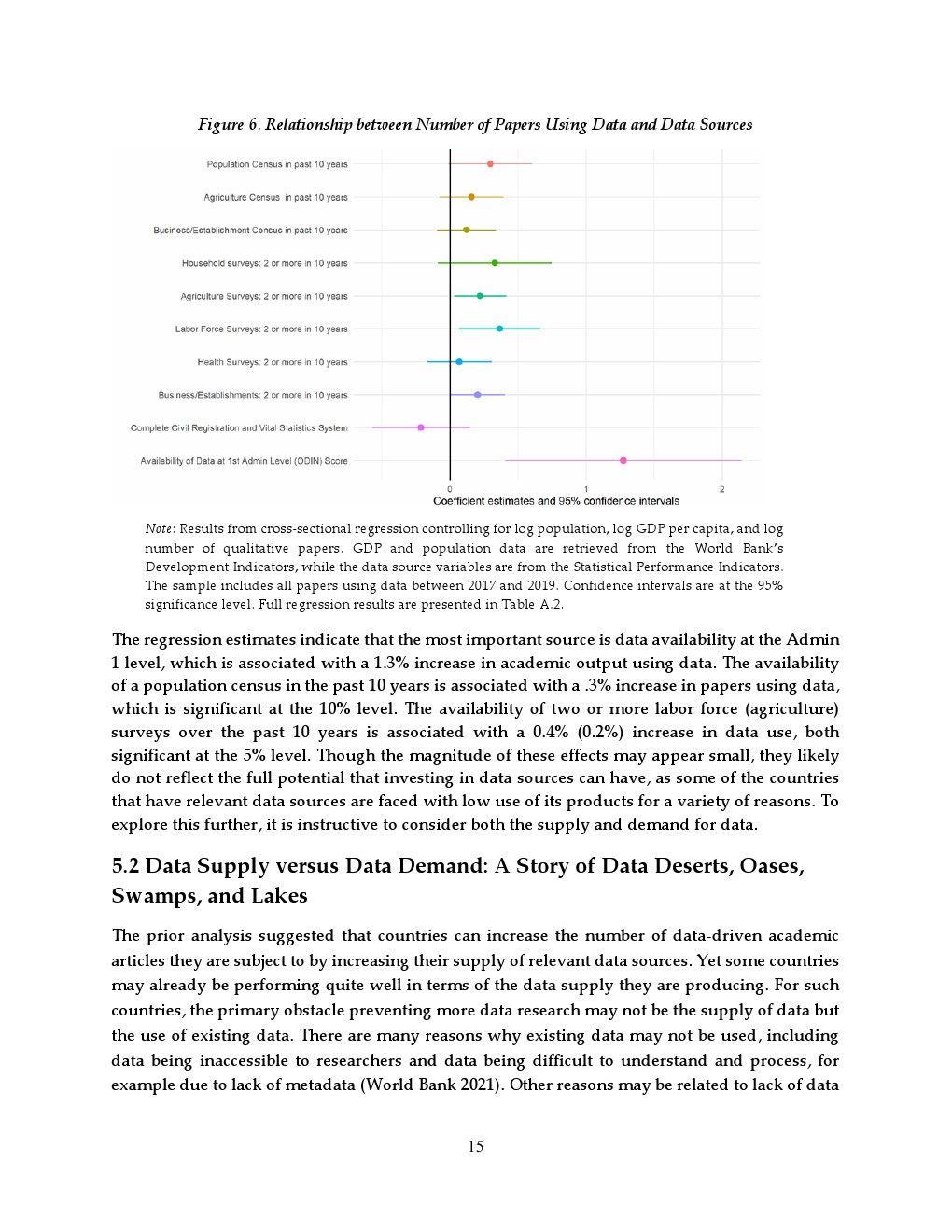
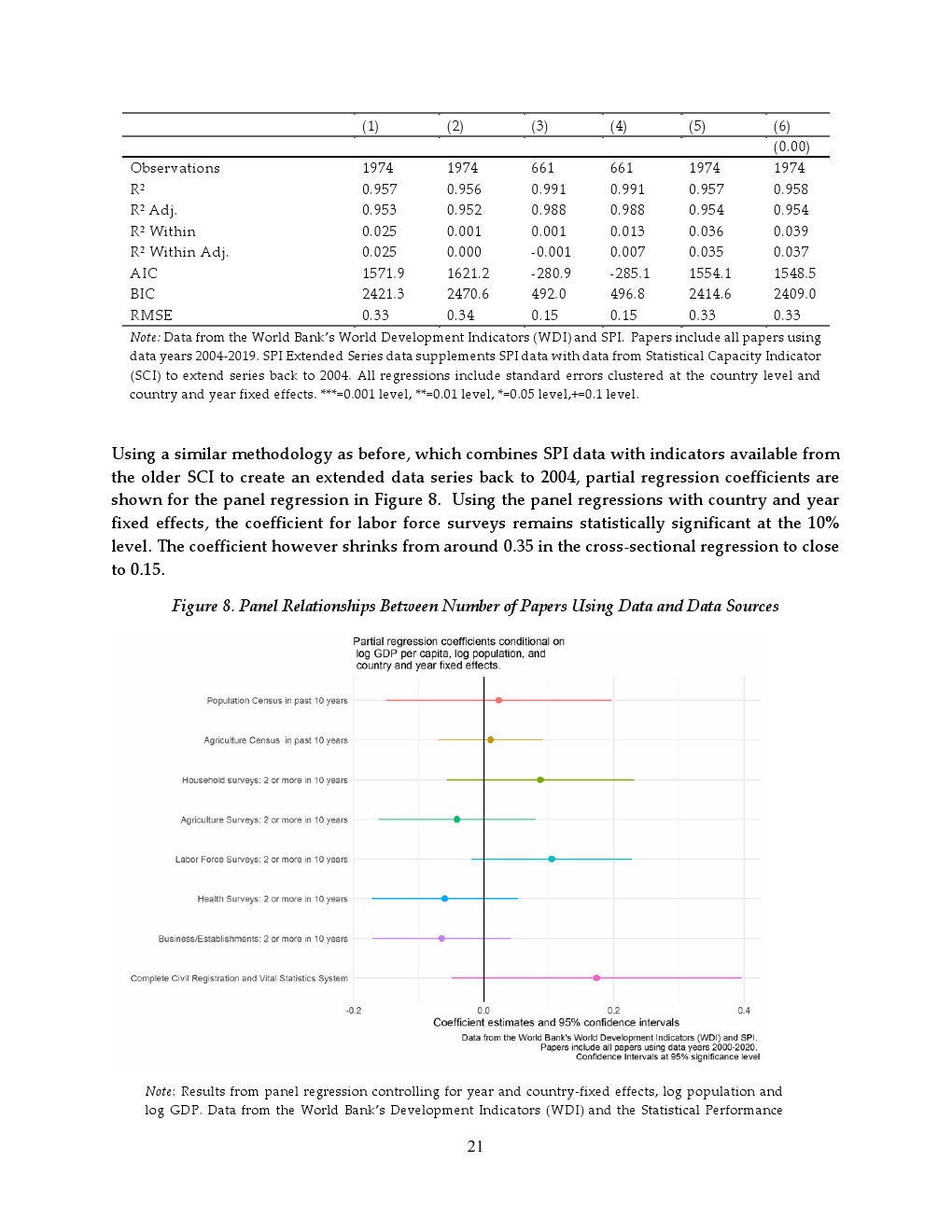
在数据供给层面,具体数据类型的可获得性对学术研究具有边际影响。省级地理空间数据可用性提升与约1.1%至1.3%的研究增长相关;近十年人口普查带来约0.3%的提升;两次及以上劳动力调查与农业调查分别对应约0.4%和0.2%的增长。这表明,相比宏观制度,细颗粒度、可操作的数据资源更直接驱动研究产出。
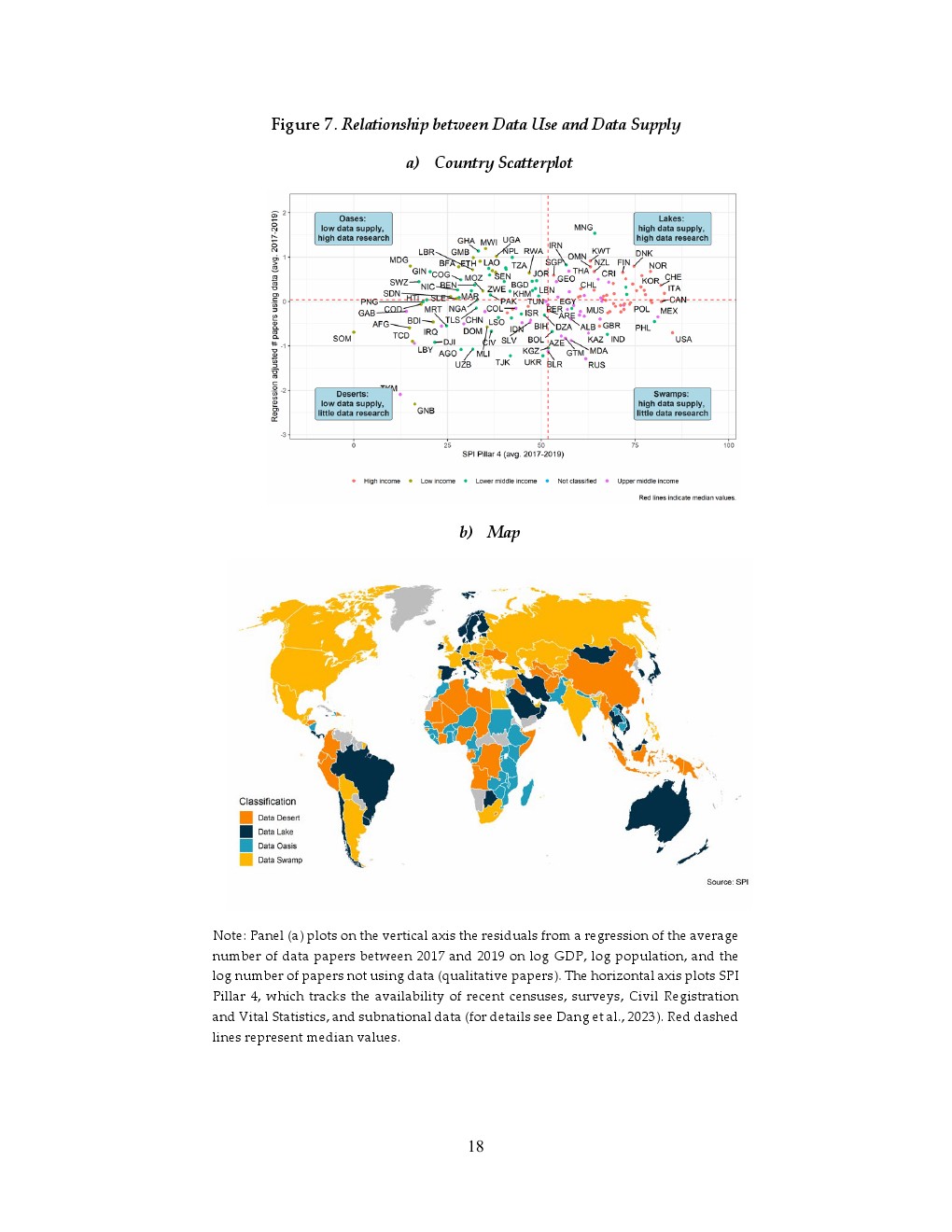
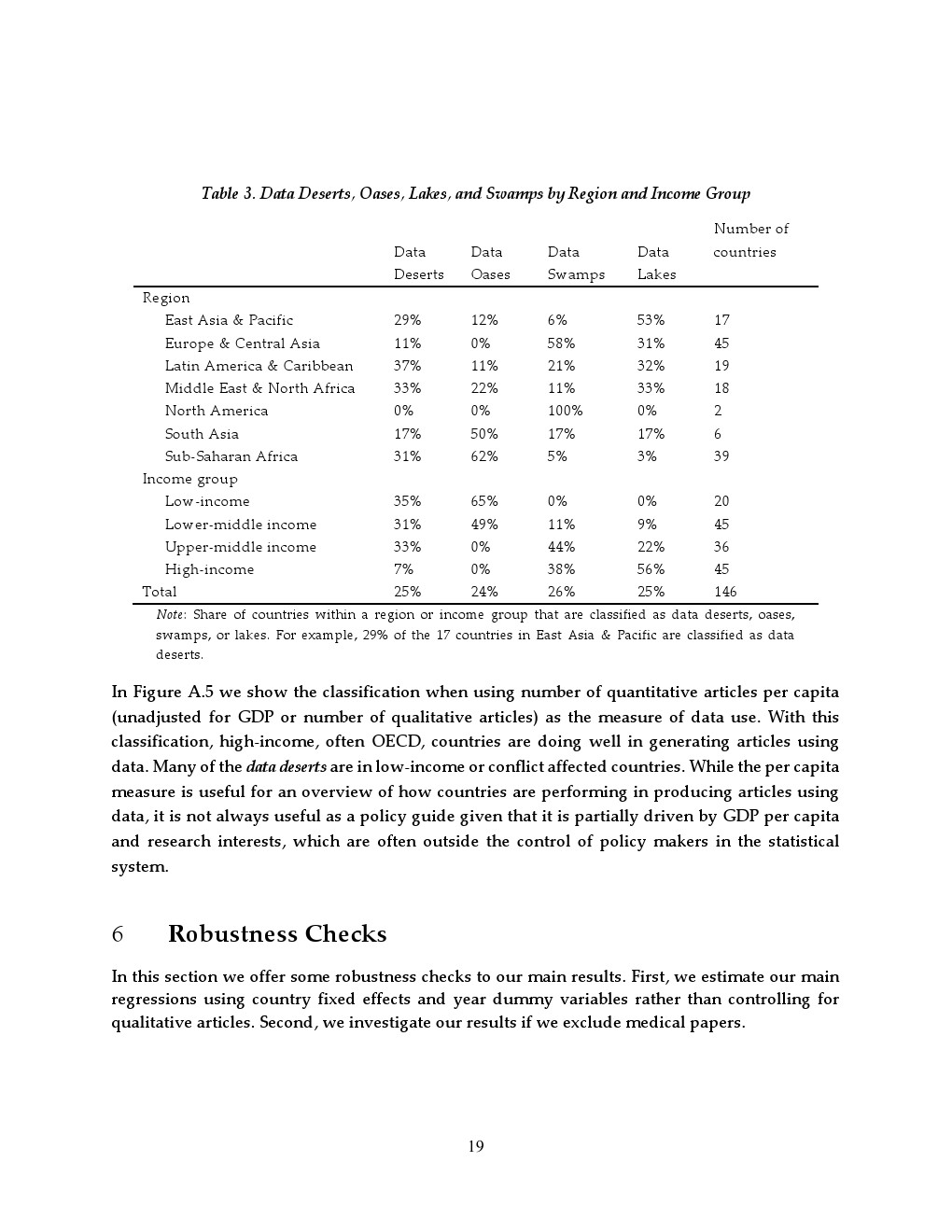
然而,数据供给并非唯一约束。研究进一步提出“数据供需四象限”框架,将国家划分为数据沙漠、绿洲、沼泽和湖泊。约三分之二低收入国家属于“数据绿洲”,即需求旺盛但供给不足,典型如乌干达、尼泊尔;而欧洲等高收入地区约半数国家为“数据沼泽”,即数据丰富但利用不足,反映出数据开放性与研究能力的结构性瓶颈。撒哈拉以南非洲93%的国家集中在供给不足类别,形成显著区域不平衡。
整体来看,全球学术数据使用呈现出“资源驱动+制度约束”的双重逻辑。经济体量决定研究关注度上限,而统计能力与数据可得性决定实际转化效率。未来趋势上,随着数据开放政策推进与数字基础设施改善,低收入国家若能提升数据供给,将可能快速缩小“证据缺口”;而高收入国家则需从“数据生产”转向“数据利用”,提升数据可访问性与研究转化效率,全球学术研究格局或将从数量集中走向结构再平衡。




















文档链接将分享到199IT知识星球,扫描下面二维码即可查阅!
更多阅读:
