
本篇论文是谷歌大脑(Google Brain)与多伦多大学合作的最新论文。谷歌大脑团队曾经负责研发了AlphaGo与TensorFlow框架等产品,其实力自然不消多说。而这一次谷歌大脑团队更是向当前深度学习架构繁多、应用领域不一等混乱现状发出挑战,霸气提出了通过单一模型联合学习多项任务。那么该模型是否真的如此神奇呢?赶紧随雷锋网AI科技评论来看看吧。
论文摘要
深度学习(Deep learning)算法在语音识别(Speeh recognition)、图像分类(Image classification)和翻译(Translation)等诸多领域都已经取得了非常好的结果。但是目前的缺陷是,针对这些不同领域的不同问题,要想深度学习模型能够取得较好的效果,研究员就需要针对当前具体问题去研究具体的深度模型架构,然后再花费大量的时间对模型的参数进行微调优化。
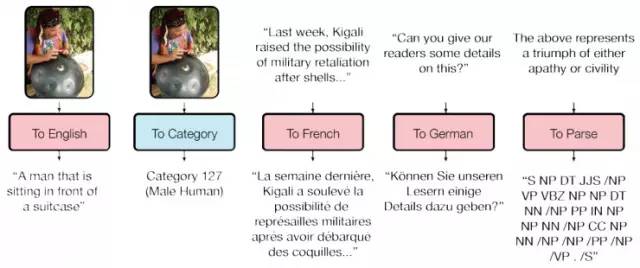
图一展示单个多模型(MultiModel)的解码示例,该模型在8个任务中进行了联合训练。其中红色的矩形框描绘了一种语言模式,而蓝色的矩形框描绘了分类模式。
本论文的研究员提出了一种单一模型,该模型能够在多个领域的不同问题中都取得较好的结果。另外值得一提的是,该单一模型可以在ImageNet、多项翻译任务、图像标注(Image captioning,采用COCO数据集)、语音识别数据集和英语解析任务中同时进行训练。据悉,该单一模型架构借鉴了来自多个领域的深度学习模型架构所使用的构建块(Building blocks),该模型具有卷积层(Convolutional layers)、注意力机制(Attention mechanism)和稀疏门控层(Sparsely-gated layers)。并且模型中的每一个计算块(Computational blocks)对于训练任务中的某一子部分都至关重要。
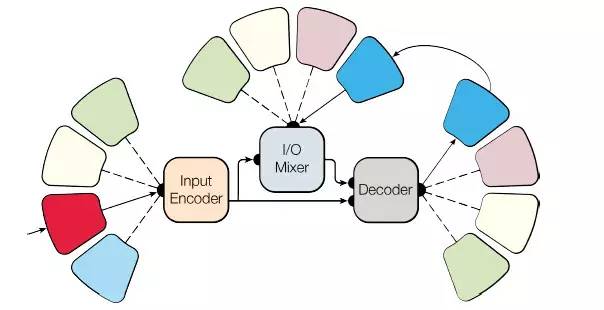
图二展示了一个多模型,该多模型具有模式网络(Modality-nets)、编码器(Encoder)和自回归解码器(Autoregressive decoder)。
在实验的过程中,研究员们还发现了一个非常有趣的现象,即使模型架构中的某一个计算块对于当前任务而言并不重要,但是实验结果表明添加该计算块到模型架构中并不会影响到最终效果,并且在大多数情况下,这种做法还能提高模型在所有任务上的表现效果。
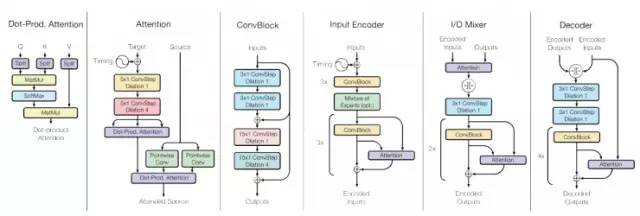
图三展示了多模型的架构,如果想获得关于该模型的具体信息,请阅读论文。
另外,在本论文中研究员们通过实验还表明具有较少数据量的任务,能够从将多个任务联合起来进行训练的方式中获得巨大的收益,而对于拥有大量数据的任务而言,这种训练方式将导致最终效果的略微下降。
来自:雷锋网编译
附英文版论文全版:









PDF版下载可加入我们小密圈,199IT感谢您的支持!

更多阅读:
