
主要介绍了深度学习的训练方法和技巧、深度学习的挑战和应对方法等问题。文末,刘博士结合眼下AI的研究进展,对深度学习领域深刻的“吐槽”了一番,妙趣横生且发人深省。
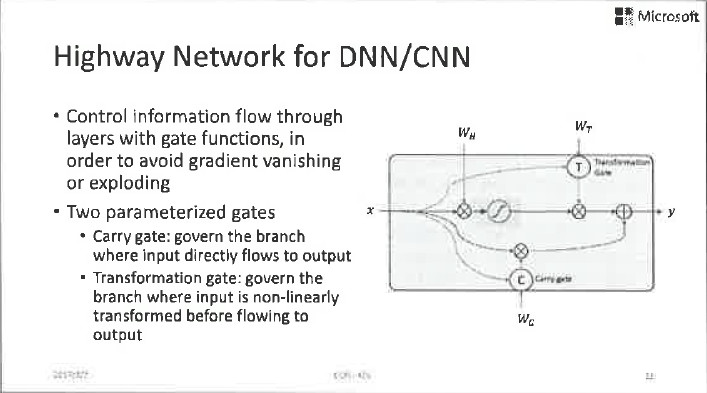
前面提到的BN方法还不能解决所有的问题。 因为即便做了白化,激活函数的导数的最大值也只有0.25,如果层数成百上千,0.25不断连乘以后,将很快衰减为0。所以后来又涌现出一些更加直接、更加有效的方法。其基本思路是在各层之间建立更畅通的渠道,让信息流绕过非线性的激活函数。这类工作包含Highway Network、LSTM、ResNet等。
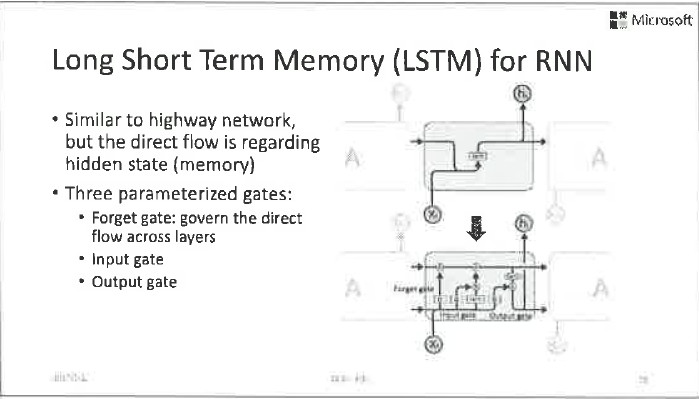
Highway Network和LSTM一脉相承,除了原来的非线性通路以外,增加了一个由门电路控制的线性通路。两个通路同时存在,而这两个通路到底谁开启或者多大程度开启,由另外一个小的神经网络进行控制。
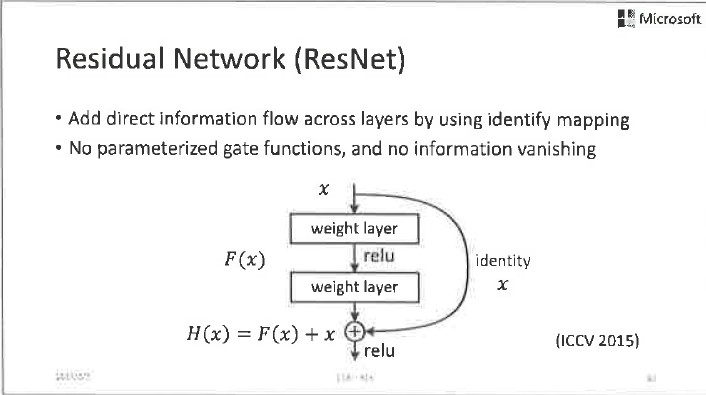
相比之下,ResNet的做法更加直接,它不用门电路控制,而是直接增加总是开通的线性通路。虽然这些方法的操作方式不同,但是它们的基本出发点是一样的,就是在一定程度上跳过非线性单元,以线性的方式把残差传递下去,对神经网络模型的参数进行有效的学习。
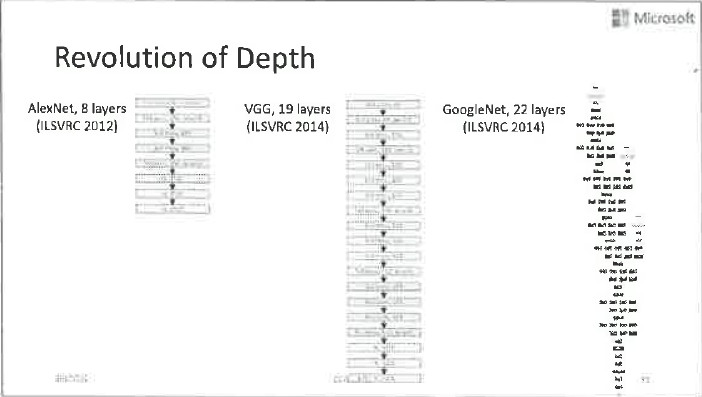
在前面提到的各项技术的帮助下,深层神经网络的训练效果有了很大的提升。这张图展示了网络不断加深、效果不断变好的历史演变过程。2012年ImageNet比赛中脱颖而出的AlexNet只有8层,后来变成19层、22层,到2015年,ResNet以152层的复杂姿态出场,赢得了ImageNet比赛的冠军。
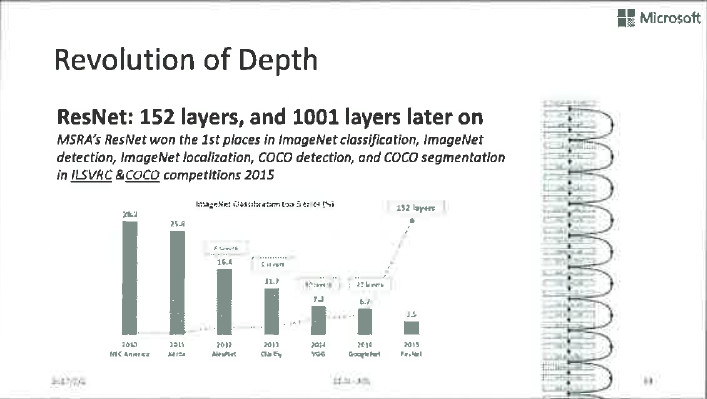
从这张图上可以看出,随着层数的不断变深,图像的识别错误率不断下降,由此看来,网络变深还是很有价值的。
到此为止,我们把深度学习及其训练方法和技巧给大家做了一个非常简短的介绍。
深度学习的挑战
接下来我们进入下一个主题:深度学习的挑战和机遇。很多人都在讨论为什么深度学习会成功,说起来无外乎来源于机器学习优化过程的三个方面。
基本上所有的有监督机器学习都是在最小化所谓的经验风险。在这个最小化的式子里包含以下几个元素:
一个是数据:X是数据的输入、Y是数据的标签;
二是模型,用f表示(L是loss function);
三是针对f的寻优过程。
首先对数据X、Y而言,深度学习通常会利用非常大量的数据进行训练。举个例子,机器翻译的训练数据通常包含上千万个双语句对,语音识别常常使用几千或者上万个小时的标注数据,而图像,则会用到几百万甚至几千万张有标签的图像进行训练。前面还提到了下围棋的AlphaGo,它使用了3千万个棋局进行训练。可以这么说,现在主流的深度学习系统动辄就会用到千万量级的有标签训练数据。这对于十几年前的机器学习领域是无法想象的。
其次,深度学习通常会使用层次很深、参数众多的大模型。很多应用级的深层神经网络会包含十亿或者更多的参数。使用如此大的模型,其好处是可以具备非常强的逼近能力,因此可以解决以往浅层机器学习无法解决的难题。
当然当我们有那么大的数据、那么大的模型,就不得不使用一个计算机集群来进行优化,所以GPU集群的出现成为了深度学习成功的第三个推手。
成也萧何败也萧何,深度学习受益于大数据、大模型、和基于计算机集群的庞大计算能力,但这些方面对于普通的研究人员而言,都蕴含着巨大的挑战。我们今天要探讨的是如何解决这些挑战。
首先,让我们来看看大数据。即便在语音、图像、机器翻译等领域我们可以收集到足够的训练数据,在其他的一些领域,想要收集到千万量级的训练数据却可能是mission impossible。比如在医疗行业,有些疑难杂症本身的样例就很少,想要获取大数据也无从下手。在其他一些领域,虽然有可能获取大数据,但是代价昂贵,可能要花上亿的成本。那么对于这些领域,在没有大的标注数据的情况下,我们还能使用深度学习吗?
其次,在很多情况下,模型如果太大会超出计算资源的容量。比如,简单计算一下要在10亿量级的网页上训练一个基于循环神经网络的语言模型,其模型尺寸会在100GB的量级。这会远远超过主流GPU卡的容量。这时候可能就必须使用多卡的模型并行,这会带了很多额外的通信代价,无法实现预期的加速比。(GPU很有意思,如果模型能塞进一张卡,它的运算并行度很高,训练很快。可一旦模型放不进一张卡,需要通过PCI-E去访问远端的模型,则GPU的吞吐量会被拖垮,训练速度大打折扣。)
最后,即便有一些公司拥有强大的计算资源,同时调度几千块GPU来进行计算不成问题,也并表示这样可以取得预期的加速比。如果这些GPU卡之间互相等待、内耗,则可能被最慢的GPU拖住,只达到了很小的加速比,得不偿失。如何保证取得线性或者准线性加速比,并且还不损失模型训练的精度,这是一个重要且困难的研究问题。
深度学习“大”挑战的应对策略

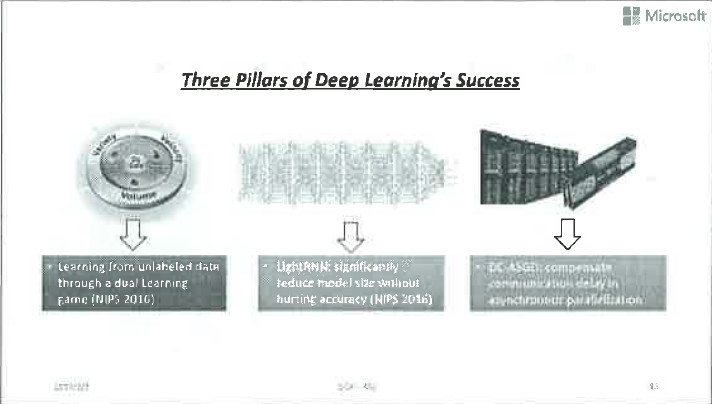
接下来我会介绍我们研究组是如何解决前面提到的有关大数据、大模型、大规模训练的技术挑战的。为此,我会简要介绍我们最近从事的三项研究工作:
一个对偶学习Dual Learning;
二是轻量级算法LightRNN;
三是Delay-Compensated ASGD。
对偶学习Dual Learning

对偶学习是我们去年年底发表在NIPS(NIPS是机器学习领域最顶级的学术会议)上的一篇论文,发表之后收到了很大的反响。这个论文提出了一个听起来很简单的思路,有效地解决了缺乏有标签训练数据的问题。那我们是如何做到这一点的呢?

我们的基本思路是在没有人工标注数据的情况下,利用其它的结构信息,建立一个闭环系统,利用该系统中的反馈信号,实现有效的模型训练。这里提到的结构信息,其实是人工智能任务的对偶性。
什么是人工智能任务的对偶性呢?让我们来看几个例子。比如机器翻译,我们关心中文到英文的翻译,同时也关心从英文到中文的翻译。比如语音方面,我们关心语音识别,同时也关心语音合成。同样,我们关心图像分类,也关心图像生成。如此这般,我们发现,很多人工智能任务都存在一个有意义的相反的任务。能不能利用这种对偶性,让两个任务之间互相提供反馈信号,把深度学习模型训练出来呢?
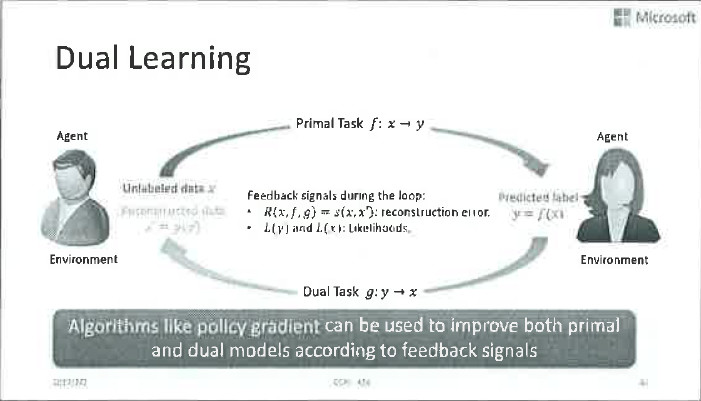
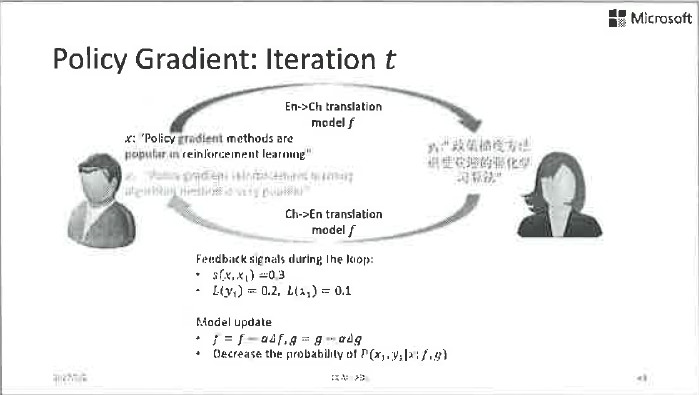
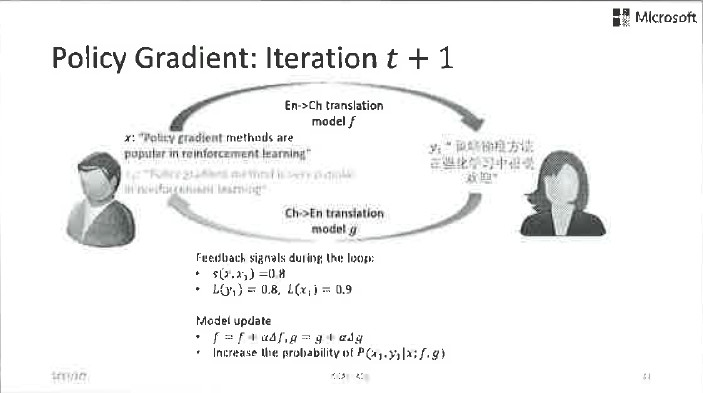
这是完全可行的。举一个简单的例子,比如左边的Agent很懂中文,并且想把中文翻译成英文,他有一点关于英文的基础知识,换句话说他拥有一个中到英翻译的弱模型。右边这个agent则相反,他精通英文并想把英文翻译成中文,但只拥有一个英到中翻译的弱模型。
现在左边的agent拿到了一个中文句子,用他的弱模型将其翻译成了英文,丢给右边的agent。右边的agent做的第一判断是她收到的句子是否是个合理的英文句子?如果从英文语法的角度看,这个句子乱七八糟的看不懂,她就会给出一个负反馈信号:之前的中到英的翻译肯定出错了。如果这个句子从语法上来看没啥问题,她就会用自己的弱翻译模型将其翻译回中文,并且传给左边的agent。同样,左边的agent可以通过语法判断这个翻译是否靠谱,也可以通过这个翻译回来的句子和原本的中文句子的比较来给出进一步的反馈信号。双方可以通过这些反馈信号来更新模型参数。这就是对偶学习,是不是特别简单?
这个过程听起来简单,但真正做起来不那么容易。因为这个闭环中很多的反馈信号都是离散的,不容易通过求导的方式加以利用,我们需要用到类似强化学习中Policy Gradient这样的方法实现模型参数的优化。我们把对偶学习应用在机器翻译中,在标准的测试数据上取得了非常好的效果。我们从一个只用10%的双语数据训练出的弱模型出发,通过无标签的单语数据和对偶学习技术,最终超过了利用100%双语数据训练出的强模型。


除了前面提到的机器翻译的例子,还有很多对偶学习的例子:比如说语音信号处理、图像信号处理、对话等等,都可以做对偶学习。这几张PPT分别展示了在这些应用里如何定义反馈信号,实现有效的参数优化。
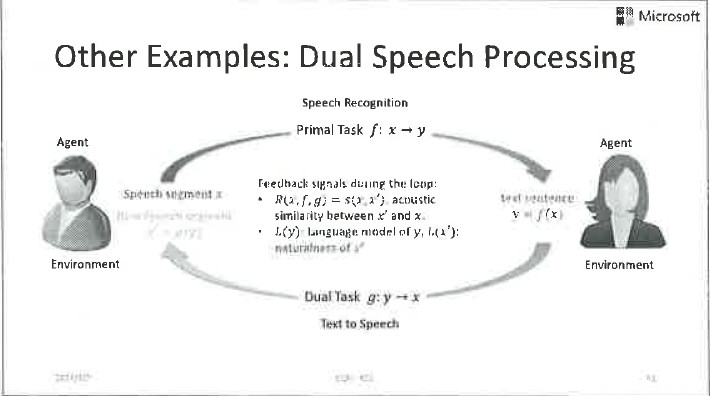
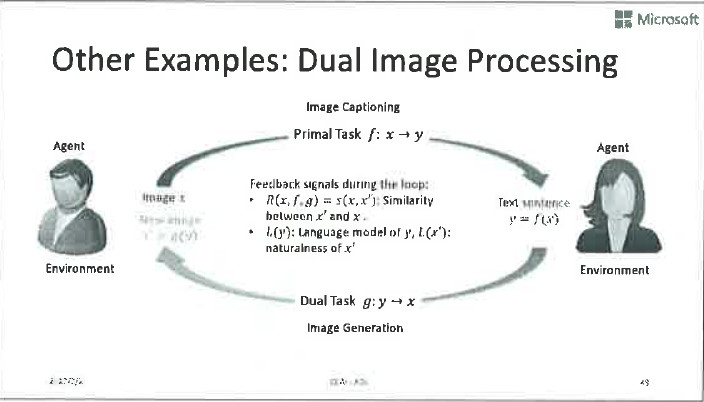
其实人工智能任务的对偶性是非常本质的,用好了在很多地方都会取得意想不到的结果。它不仅可以帮助我们把无标签数据用起来,还可以显著地提高有标签数据的学习效果。接下来我们将会展示对偶学习的各种扩展应用。
首先,有人可能会问,你举的这些例子里确实存在天然的对偶性,可以也有些任务并没有这种天然的对偶性,那能不能使用对偶学习技术来改善它们呢?答案是肯定的。如果没有天然的对偶性,我们可以通过类似“画辅助线”的方法,构建一个虚拟的对偶任务。只不过在完成对偶学习之后,我们仅仅使用主任务的模型罢了。大家可能也听过这几年很火的GAN(Generative Adversarial Nets),它就可以看做一种虚拟的对偶学习。
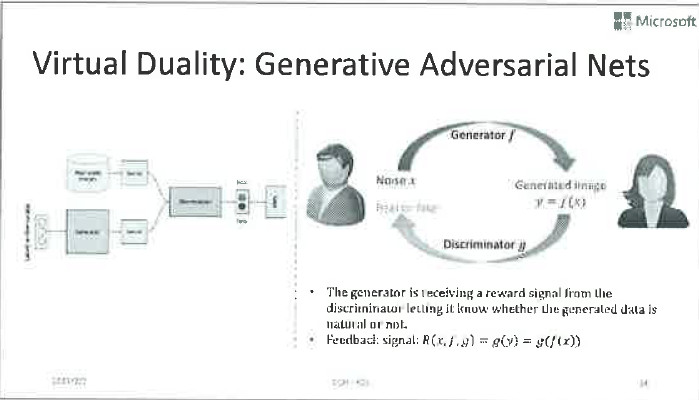
其次,还有人可能会问,对偶学习主要是解决无标签数据的学习问题,那我如果只关心有监督的学习问题,这个结构对偶性还有帮助吗?答案也是肯定的。
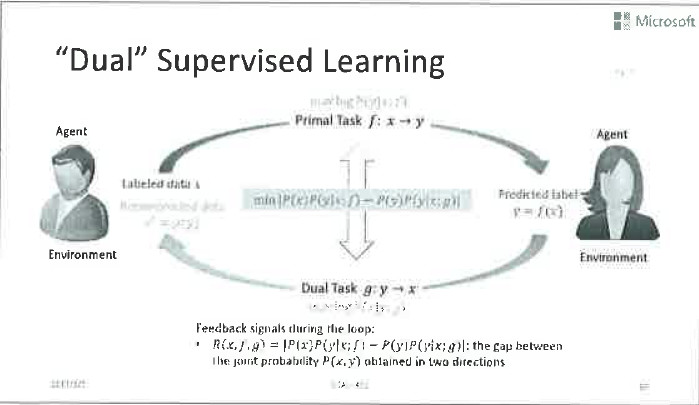
以前人们在训练一对对偶任务的时候,通常是独立进行的,也就是各自利用自己的训练数据来训练,没有在训练过程考虑到还存在另一个有结构关系的训练任务存在。其实,这两个训练任务是存在深层次内在联系的。大家学过机器学习原理的话,就知道我们训练的分类模型其实是去逼近条件概率P(Y X)。那么一对对偶任务的模型分别逼近的是P(Y X)和P(X Y)。他们之间是有数学联系的:P(X)P(Y X)=P(Y)P(X Y)。其中的先验分布P(X)和P(Y)可以很容易通过无标签数据获得。
因此,我们在训练两个模型的时候,如果由他们算出的联合概率不相等的话,就说明模型训练还不充分。换言之,前面的等式可以作为两个对偶任务训练的正则项使用,提高算法的泛化能力,在未知的测试集上取得更好的分类效果。
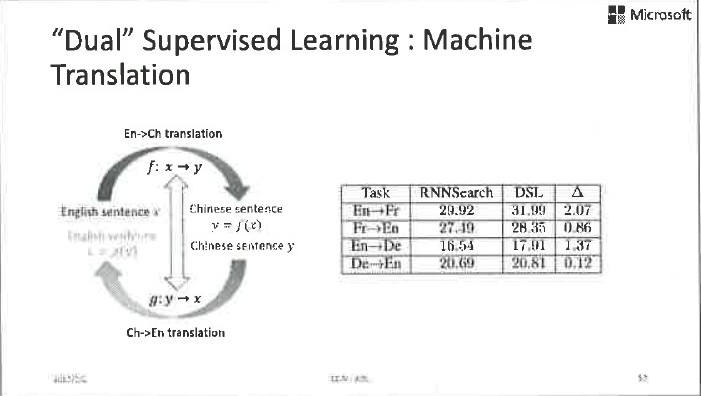
我们把这个正则项应用到机器翻译中,再次取得了明显的提升,从英法互译的数据上看,BLEU score提高了2个点。
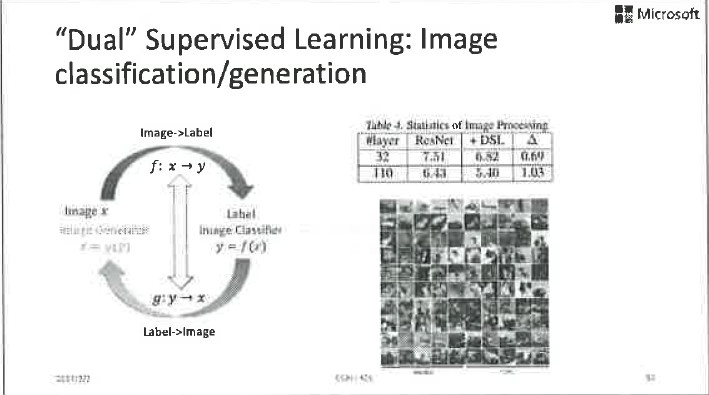
同样,加入这个正则项,在图像分类、图像生成、情感分类、情感生成等方面都取得了很好的效果。我们举个例子,传统技术在做情感生成的时候,出来的语句是似然比较大的句子,通常是训练数据里最多出现的词语和句式。而引入了情感分类的对偶正则项,生成的句子就会更多地包含那些明显携带感情色彩的词语。这样生成的句子就会既有内容、又有情感,效果更好。

第三,或许有人还可能会问:如果我无法改变模型训练的过程,别人已经帮我训练好了两个模型,对偶性还能帮我改善推断的过程吗?答案还是肯定的。假设我们之前已经独立地训练了两个模型,一个叫f,一个叫g(比如f是做语音识别的,g是做语音合成的),现在要用他们来做inference。这个时候,其实前面说的概率约束还在。我们可以通过贝叶斯公式,把两个对偶任务的模型联系起来,实现共同的推断。具体细节如图所示。我们做了大量实验,效果非常好。比如在机器翻译方面,联合推断又会带来几个点的BLEU score的提升。
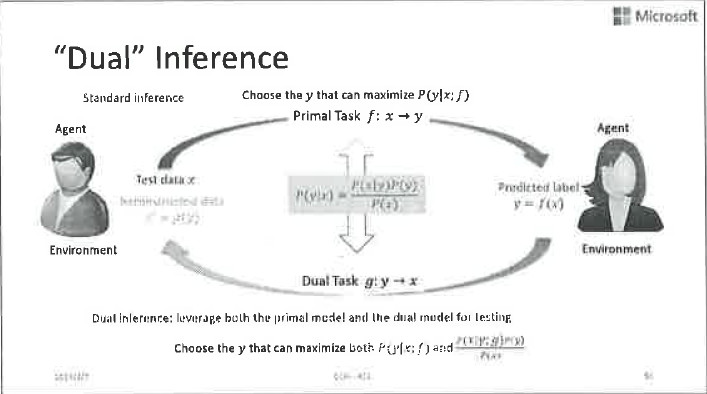

总结一下,我们认为对偶学习是一个新的学习范式,它和co-training、Transfer learning等既有联系又有区别。它开启了看待人工智能任务的新视角,应用价值远远不止前面的具体介绍,如果大家有兴趣可以跟我们一起挖掘。
轻量级算法LightRNN
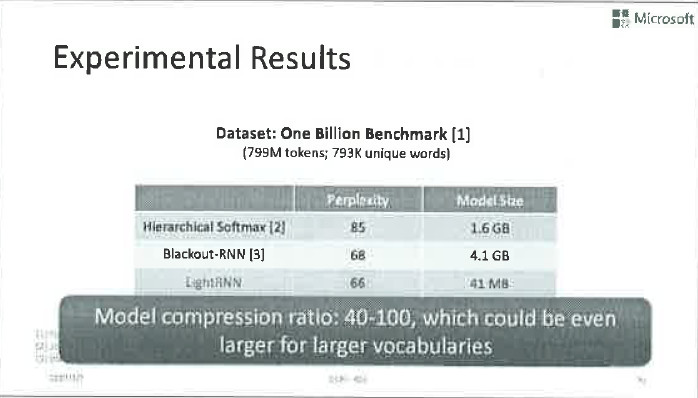
接下来,我们来讨论一下如何处理大模型的挑战。举个例子,假设我们要利用clueweb这样的互联网数据集来训练语言模型。这种大数据集通常有千万量级的词表,其中包含很多生僻的人名、地名、公司名,新词、衍生词、甚至是用户输入的错词。如果使用前面提到的循环神经网络来训练语言模型,经过非常简单的运算就可以得出,其模型规模大约80G,也就是说你需要有80G的内存才能放下这个RNN模型,这对于CPU不是什么问题,但是对GPU而言就是非常大的挑战了,主流的GPU只有十几二十G的内存,根本放不下这么大的模型。 就算真的可以,以目前主流GPU的运算速度,也要将近200年才能完成训练。

那这个问题怎么解决呢?接下来我们要介绍的LightRNN算法是一种解决的办法,我相信还有很多别的方法,但是这个方法很有启发意义。它的具体思路是什么呢?首先,让我们来看看为什么模型会那么大,其主要原因是我们假设每个词都是相互独立的,因而如果有1千万个词,就会训练出1千万个向量参数来。显然这种假设是不正确的,怎么可能这1千万个词之间没有关系呢?如果我们打破这个假设,试图在学习过程中发现词汇之间的相关性,就可能极大地压缩模型规模。特别地,我们用2个向量来表达每个词汇,但是强制某些词共享其中的一个分量,这样虽然还是有那么多词汇,我们却不需要那么多的向量来进行表达,因此可以缩小模型尺寸。

具体而言,我们建立了一张映射表,在这张表里面每一个词对应两个参数向量(x和y),表里所有同一行的词共享x,所有同一列的词共享y。相应地,我们需要把RNN的结构做一些调整,如下图所示。
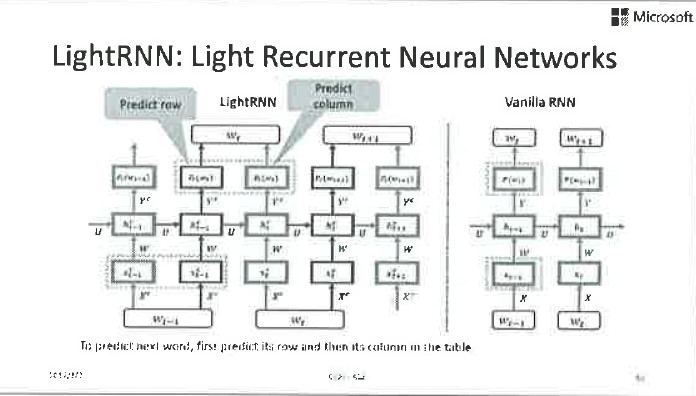
这样我们就可以把一个80G的模型,压缩到只有50M那么大。这么小的模型,不仅训练起来很快,还可以随便塞到移动终端里,实现高效的inference。
那么有人会问了,前面的LightRNN算法严重依赖于这个二维映射表,可是怎么才能构建出一个合理的表格,使得有联系的词共享参数,没有联系的词就不共享参数呢?其实这是一个经典的问题。假设我给每个词都已经有一个参数表达,x、y已经有了,就可以通过求解一个最优二分图匹配的问题实现二维映射表的构造。而一旦有了映射表,我们又可以通过RNN的训练更新参数表达。这是一个循环往复的过程,最终收敛的时候,我们不但有了好的映射表,也有了好的参数模型。

我们在标准数据集上测试了LightRNN算法。神奇的是,虽然模型变小了,语言模型的Perplexity竟然变好了。这个效果其实有点出乎我们的预期,但是却也在情理之中。因为LightRNN打破了传统RNN关于每个词都是独立的假设,主动挖掘了词汇之间的语义相似性,因此会学到更加有意义的模型参数。这对inference是很有帮助的。
其实LightRNN的思想远远超过语音模型本身,机器翻译里、文本分类里难道就没有这个问题吗?这个技术可以推广到几乎所有文本上的应用问题。甚至,除了文本以外,它还可以用来解决大规模图像分类的问题。只要模型的输出层特别大,而且这些输出类别存在某些内在的联系,都可以采用LightRNN的技术对模型进行简化,对训练过程进行加速。


除此之外,模型变小了,对分布式训练也很有意义。分布式运算的时候,各个worker machine之间通常要传递模型或者模型梯度。当模型比较小的时候,这种传输的通信代价就比较小,分布式训练就 比较容易取得较高的加速比。
Delay-Compensated ASGD

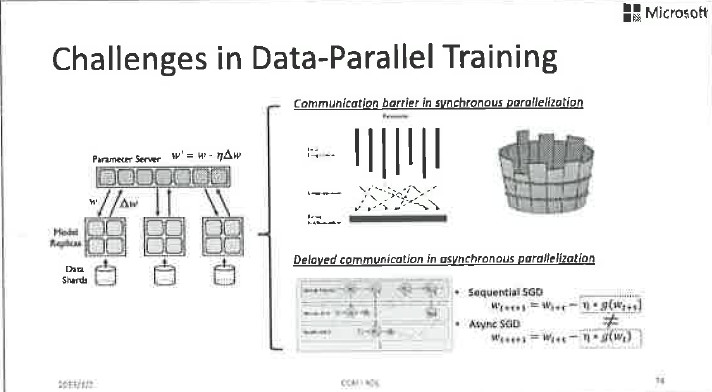
说到分布式训练,我们顺便就讲讲第三个挑战。我们这里讨论的主要是数据并行,也就是数据太多了,一台机器或者放不下、或者训练速度太慢。假设我们把这些数据分成N份,每份放在一台机器上,然后各自在本地计算,一段时间以后把本地的运算结果和参数服务器同步一下,然后再继续本地的运算,这就是最基本的数据并行的模式。
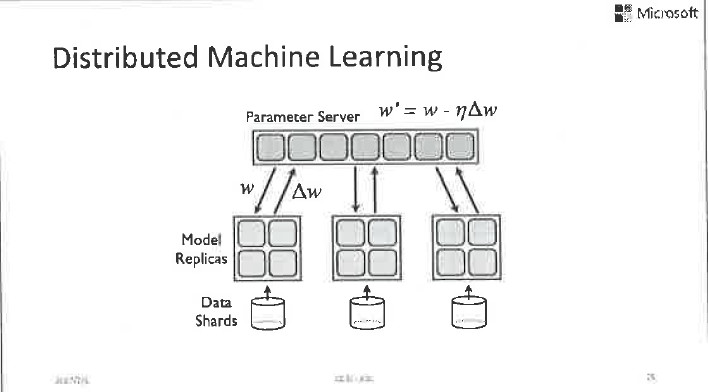
数据并行模式有两个常用的做法:
一是同步;
二是异步。
同步并行指的是本地将模型更新后发给参数服务器,然后进入等待状态。直到所有模型更新都发到参数服务器以后,参数服务器将模型进行平均和回传,大家再各自以平均模型为起点,进行下一轮的本地训练。这个过程是完全可控的,而且在数学上是可以清晰描述的。但是,它的问题是由于互相等待,整个系统的速度会被最慢的机器拖垮。虽然使用了很多机器一起进行并行运算,但通常无法达到很高的加速比。为了解决这个问题,异步并行被大量使用。
所谓异步并行指的是,本地机器各自进行自己的训练工作,一段时间以后将模型更新推送到参数服务器上,然后并不等待其他机器,而是把当前参数服务器上的全局模型拿下来,以此为起点马上进行下一轮的本地训练。这个过程的好处就是快,因为各个机器之间不需要互相等待,但是训练过程在数学上的描述是不清晰的,因为包含很多乱序更新,它和单机串行训练的过程相去甚远,所以训练的结果没有很好的理论保证,会受到各个机器之间速度差的影响。我们用延迟来描述这种速度差。具体来说,假设我们一共有10台机器参与运算,对于其中的一台机器,当我从参数服务器上取得一个模型,并且根据本地数据求出模型梯度以后,在我打算将这个梯度回传给参数服务器之前,可能其他的机器已经把他们的模型梯度推送给了参数服务器,也就是说参数服务器上的全局模型可能已经发生了多次版本变化。那么我推送上去的模型梯度就不再适用了,因为它对应于一个旧模型,我们称之为延迟的梯度。当延迟的梯度被加到全局模型以后,可能毁掉全局模型,因为它已经违背了梯度下降的基本数学定义,因此收敛性没法得到很好的保障。

为了解决这个问题,人们使用了很多手段,包括SSP、AdaDelay等等。他们或者强制要求跑的快的机器停下来等待比较慢的机器,或者给延迟的梯度一个较小的学习率。


也有人证明其实这个延迟和Momentum有某种关系,只需要调整momentum的系数就可以平衡这个延迟。这些工作都很有意义,但是他们并没有非常正面地分析延迟的来源,并且针对性地解决延迟的问题。

我们研究组对这么问题进行了正面的回答。其实这个事说起来也很简单。

大家想想,我们本来应该加上这个梯度才是标准的梯度下降法,可是因为延迟的存在,我们加却把t时刻的梯度加到了t+τ时刻的模型上去。正确梯度和延迟梯度的关系可以用泰勒展开来进行刻画:它们之间的差别就是这些一阶、二阶、和高阶项。如果我们能把这些项有效地利用起来,就可以把延迟补偿掉。这事看起来好像简单,做起来却不容易。
首先,泰勒展开在什么时候有意义呢?Wt和Wt+τ距离不能太远,如果相差太远,那些高阶项就不是小量,有限泰勒展开就不准了。这决定了在训练的哪个阶段使用这项技术:在训练的后半程,当模型快要收敛,学习率较小的时候,可以保证每次模型变化不太大,从而安全地使用泰勒展开。
其次,即便是多加上一个一阶项,运算量也是很大的。因为梯度函数的一阶导数对应于原目标函数的二阶导数,也就是对应于海森阵。我们知道海森阵计算和存储的复杂度都很高,在模型很大的时候,实操性不强。
那么怎么解决这个挑战呢?我们证明了一个定理,在特定情况下,Hessen阵可以几乎0代价地计算出来,而且近似损失非常之小。具体而言,我们证明了对于一些特定的损失函数(负对数似然的形式),二阶导可以被一阶导的外积进行无偏估计。无偏估计虽然均值相同,方差可能仍然很大,为了进一步提升近似效果,我们通过最小化MSE来控制方差。做完之后我们就得到了一个新的公式,这个公式除了以前的异步的梯度下降以外还多引入一项,其中包含一个神奇的Φ函数和λ因子,只要通过调节他们就可以有效的补偿延迟。
在此基础上,我们进一步证明,使用延迟补偿的异步并行算法可以取得更好的收敛性质,其对延迟的敏感性大大降低。

这一点被我们所做的大量实验验证。实验表明,我们不仅可以取得线性加速比,还能达到几乎和单机串行算法一样的精度。

到这儿为止我们针对大数据、大模型、大计算的挑战,分别讨论了相应的技术解决方案。

如果大家对这些研究工作感兴趣,可以看一下我们的论文,也欢迎大家使用微软的开源工具包CNTK和DMTK,其中已经包含了我们很多的研究工作。


在报告的最后,和大家聊点开脑洞的话题。这几张PPT是中文的,其实是我之前在一次报告中和大家分享的关于AI的观点时使用的。其中前三个观点已经在今天的讲座中提到了。我们再来看看后面几条:
首先是关于深度学习的调参问题。现在深度学习技术非常依赖于调参黑科技。即便是公开的算法,甚至开源的代码,也很难实现完美复现,因为其背后的调参方法通常不会公开。那么,是否可以用更牛的黑科技来解决这个调参黑科技的问题呢?这几年炒的很火的Learning to Learn技术,正是为了实现这个目的。大家可以关注一下这个方向。

其次,深度学习是个黑箱方法。很多人都在吐槽,虽然效果很好,就是不知道为什么,这使得很多敏感行业不敢用,比如医疗、军工等等。怎样才能让这个黑盒子变灰甚至变白呢?我们组目前在从事一项研究,试图把符号逻辑和深度学习进行深度集成,为此开发了一个新系统叫graph machine,今年晚些时候可能会开源,到时候大家就可以进一步了解我们的具体做法。

最后,我来吐槽一下整个深度学习领域吧 :).
我觉得现在所谓的AI其实不配叫做 Artificial Intelligence,更像是animal Intelligence。因为它不够智能,它解决的绝大部分问题都是动物智能做的事情。关键原因是,它没有抓到人和动物的关键差别。人和动物的差别是脑容量的大小吗?是大数据、大计算、大模型能解决的吗?我个人并不这样认为。我觉得人和动物主要的差别是在于人是社会动物,人有一套非常有效的机制,使人变得越来越聪明。
我给大家举个简单的例子,虽然动物也会通过强化学习适应世界,学得一身本事。但是,一旦成年动物死掉,他们积累的技能就随之消失,幼崽需要从头再来,他们的智能进化就被复位了。而人则完全不同,我们人会总结知识,通过文字记录知识、传承知识;人有学校,有教育体系(teaching system),可以在短短十几年的时间里教会自己的孩子上下五千年人类积累的知识。所以说,我们的智能进化过程从未复位,而是站在前人的肩膀上继续增长。这一点秒杀一切动物,并且使得人类的智能越来越强大,从而成为了万物之灵。
可是现在的人工智能研究并没有对这些关键的机制进行分析和模拟。我们有deep learning,但是没有人研究deep teaching。所以我才说现在的人工智能技术是南辕北辙,做来做去还是动物智能,只有意识到人和动物的差别才能有所突破。或许,Deep Teaching才是人工智能的下一个春天。
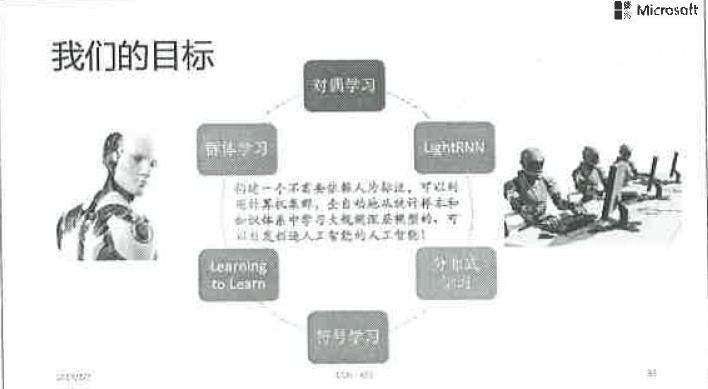
前面这些思考引导我在微软亚洲研究院组织研究项目的时候进行合理的布局,比如我们正在从事着对偶学习,Light machine learning,符号学习,分布式学习、群体学习等研究工作。我们拒绝跟风,而是追随内心对人工智能的认识不断前行。今天的讲座目的不仅是教会大家了解什么是深度学习,更重要的是启发大家一起努力,把人工智能这个领域、深度学习这个领域推向新的高度,为人工智能的发展做出我们中国人独特的贡献!
【 摘自:AI科技评论
更多阅读:
