
数据分析百科给出准确定义:指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
简而言之就是有目的的收集数据、分析数据,使之成为信息的过程。
数据分析过程1、探索性数据分析
初步获取的数据是杂乱无章的,通过图表形式对数据进行整合,找寻数据之间存在的关系。
2、模型选定分析
通过探索性数据分析,归纳出一类甚至是多类数据模型,通过对模型再次整合,进一步分析出一定的模型。
3、推断分析
通常使用数理统计方法对所定模型或估计的可靠程度和精确程度作出推断。
数据分析流程
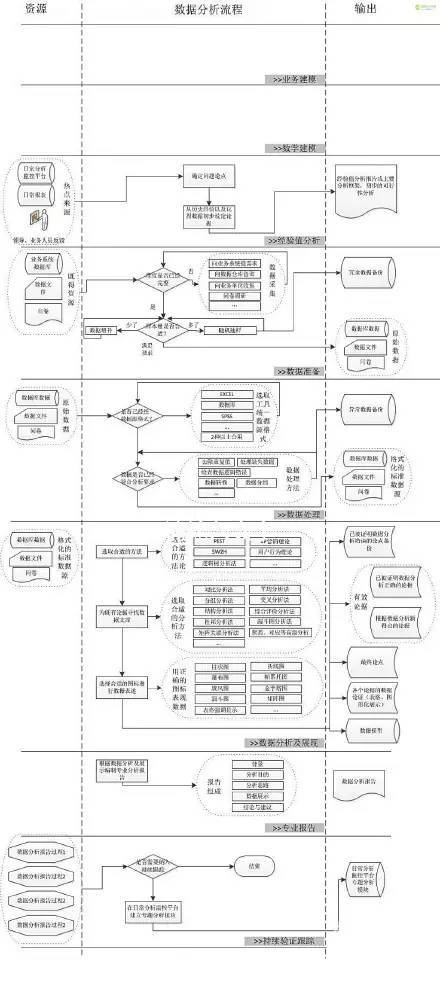
完整数据分析流程图
1. 识别信息需求
识别信息需求是确保数据分析过程有效性的首要条件,可以为收集数据、分析数据提供清晰的目标。
2.数据采集
了解数据采集的意义在于真正了解数据的原始面貌,包括数据产生的时间、条件、格式、内容、长度、限制条件等。帮助数据分析师更有针对性的控制数据生产和采集过程,避免由于违反数据采集规则导致的数据问题;同时对数据采集逻辑的认识增加了数据分析师对数据的理解程度,尤其是数据中的异常变化。
在数据采集阶段,数据分析师需要更多的了解数据生产和采集过程中的异常情况,能很大程度上避免“垃圾数据进导致垃圾数据出”的问题。
2.数据存储
在数据存储阶段,数据分析师需要了解数据存储内部的工作机制和流程,最核心的因素是在原始数据基础上经过哪些加工处理,最后得到了怎样的数据。由于数据在存储阶段是不断动态变化和迭代更新的,其及时性、完整性、有效性、一致性、准确性很多时候由于软硬件、内外部环境问题无法保证,这些都会导致后期数据应用问题。
3.数据提取
数据提取是将数据取出的过程,数据提取的核心环节是从哪取、何时取、如何取。
在数据提取阶段,数据分析师首先需要具备数据提取能力。常用的Select From语句是SQL查询和提取的必备技能,但即使是简单的取数工作也有不同层次。
第一层是从单张数据库中按条件提取数据的能力,where是基本的条件语句;
第二层是掌握跨库表提取数据的能力,不同的join有不同的用法;
第三层是优化SQL语句,通过优化嵌套、筛选的逻辑层次和遍历次数等,减少个人时间浪费和系统资源消耗。
4.数据挖掘
数据挖掘是面对海量数据时进行数据价值提炼的关键,以下是算法选择的基本原则:
没有最好的算法,只有最适合的算法,算法选择的原则是兼具准确性、可操作性、可理解性、可应用性。
没有一种算法能解决所有问题,但精通一门算法可以解决很多问题。
挖掘算法最难的是算法调优,同一种算法在不同场景下的参数设定相同,实践是获得调优经验的重要途径。
在数据挖掘阶段,数据分析师要掌握数据挖掘相关能力:一是数据挖掘、统计学、数学基本原理和常识;二是熟练使用一门数据挖掘工具,Clementine、SAS或R都是可选项,如果是程序出身也可以选择编程实现;三是需要了解常用的数据挖掘算法以及每种算法的应用场景和优劣差异点。
5.数据分析
分析数据是将收集的数据通过加工、整理和分析、使其转化为信息,通常所用的方法有:
老七种工具,即排列图、因果图、分层法、调查表、散步图、直方图、控制图;
新七种工具,即关联图、系统图、矩阵图、KJ法、计划评审技术、PDPC法、矩阵数据图;
数据分析相对于数据挖掘更多的是偏向业务应用和解读,当数据挖掘算法得出结论后,如何解释算法在结果、可信度、显著程度等方面对于业务的实际意义,如何将挖掘结果反馈到业务操作过程中便于业务理解和实施是关键。
6.数据可视化
数据分析界有一句经典名言,字不如表,表不如图。别说平常人,数据分析师自己看数据也头大。这时就得靠数据可视化的神奇魔力了。除掉数据挖掘这类高级分析,不少数据分析师的平常工作之一就是监控数据观察数据。
7.数据应用
数据应用是数据具有落地价值的直接体现,这个过程需要数据分析师具备数据沟通能力、业务推动能力和项目工作能力。
数据沟通能力。深入浅出的数据报告、言简意赅的数据结论更利于业务理解和接受。
业务推动能力。在业务理解数据的基础上,推动业务落地实现数据建议。
项目工作能力。数据项目工作是循序渐进的过程,无论是一个数据分析项目还是数据产品项目,都需要数据分析师具备计划、领导、组织、控制的项目工作能力。
附:数据分析常用方法
1、描述性统计分析
包括样本基本资料的描述,作各变量的次数分配及百分比分析,以了解样本的分布情况。
此外,以平均数和标准差来描述市场导向、竞争优势、组织绩效等各个构面,以了解样本企业的管理人员对这些相关变量的感知,并利用t检验及相关分析对背景变量所造成的影响做检验。
2、Cronbach’a信度系数分析
信度是指测验结果的一致性、稳定性及可靠性,一般多以内部一致性(consistency)来加以表示该测验信度的高低,信度系数愈高即表示该测验的结果愈一致、稳定与可靠。
针对各研究变量的衡量题项进行Cronbach’a信度分析,以了解衡量构面的内部一致性。一般来说,Cronbach’a仅大于0.7为高信度,低于0.35为低信度(Cuieford,1965),0.5为最低可以接受的信度水准(Nunnally,1978)。
3、探索性因素分析(exploratory factor analysis)和验证性因素分析(confirmatory factor analysis)
用以测试各构面衡量题项的聚合效度(convergent validity)与区别效度(discriminant validity),因为仅有信度是不够的,可信度高的测量,可能是完全无效或是某些程度上无效,所以我们必须对效度进行检验。
效度是指工具是否能测出在设计时想测出的结果,收敛效度的检验根据各个项目和所衡量的概念的因素的负荷量来决定,而区别效度的检验是根据检验性因素分析计算理论上相关概念的相关系数,检定相关系数的95%信赖区间是否包含1.0,若不包含1.0,则可确认为具有区别效度(Anderson,1987)。
4、结构方程模型分析(structural equations modeling)
由于结构方程模型结合了因素分析(factor analysis)和路径分析(path analysis),并纳入计量经济学的联立方程式,可同时处理多个因变量,容许自变量和因变量含测量误差,可同时估计因子结构和因子关系,容许更大弹性的测量模型,可估计整个模型的拟合程度(Bollen和Long,1993),因而适用于整体模型的因果关系。
在模型参数的估计上,采用最大似然估计法(Maximum Likelihood,ML);在模型的适合度检验上,以基本的拟合标准(preliminary fit criteria)、整体模型拟合优度(overall model fit)以及模型内在结构拟合优度(fit of internal structure of model)(Bagozzi和Yi,1988)三个方面的各项指标作为判定的标准。
在评价整体模式适配标准方面,本研究采用x2(卡方)/df(自由度)值、拟合优度指数(goodness.of.f:iJt.in.dex,GFI)、平均残差平方根(root—mean.square:residual,RMSR)、近似误差均方根(root-mean—square-error-of-approximation,RMSEA)等指标;模型内在结构拟合优度则参考Bagozzi和Yi(1988)的标准,考察所估计的参数是否都到达显著水平。
更多阅读:
