
自从大数据这个词出来以后,数据已经成为一个非常明确的科学领域。在这当中很少有人详细地探讨数据科学的结构和它面临的问题,包括我们行业面临的问题。
数据科学有三个非常重要的层次:数据的获取、数据的描述和数据的分析,这三件事是不同的,不要把它混淆了。
1.数据的获取
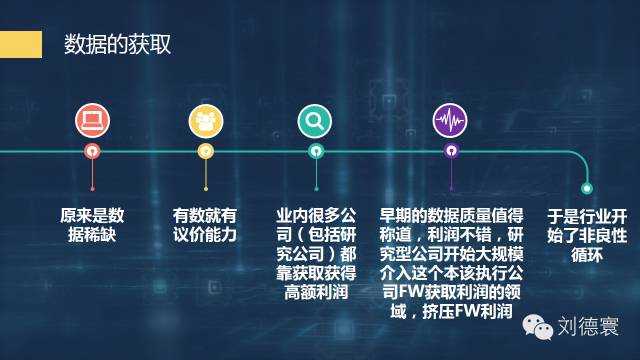
以前数据的稀缺导致行业内出现非常大的非良性循环。
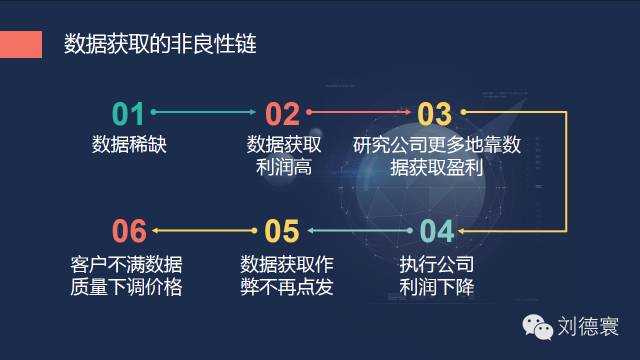
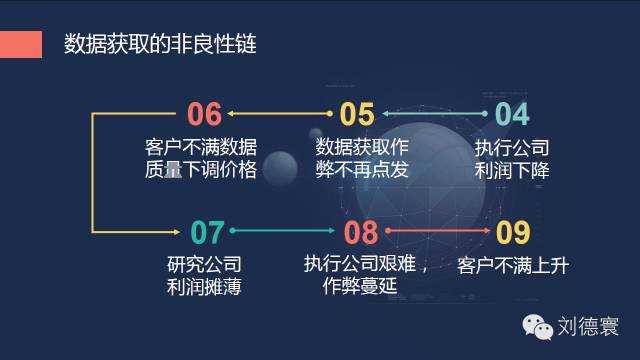
在这个过程当中,又正好赶上了一个新的时代——机器化数据横空出世,突然之间,甚至一夜之间数据不再稀缺了。单靠获得数据,你能拿到高额利润的可能性微乎其微,这样就必然导致执行公司如果要继续作弊必死无疑,未来五年内我们可以清楚的看到,研究公司不好好做研究,也照样是必死无疑,无论你是国际的,还是国内的,因为时代变了。所以数据获取这一块,要有非常清醒的认识。
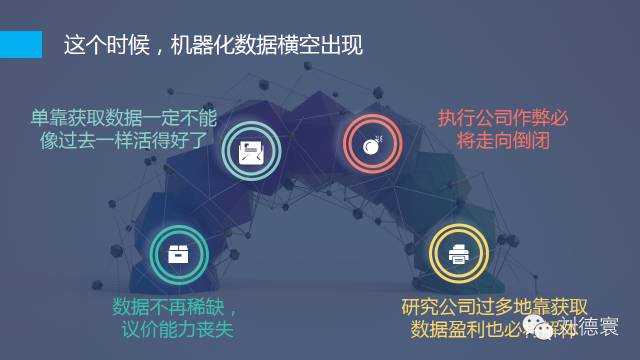
在这个时候大数据,正常的讲叫机器化数据已经被神话,而市场研究公司被积压在这里,市场研究数据的结构化,它必须满足两个条件,一是真的,二是价格是低的,这两件事造成的后果是什么,我相信业内的所有公司都会有体会。

2.数据的描述
再看数据的描述,由于整个社会大环境巨大的变化,在描述环节上出现了非常大的问题,这个问题中你会发现形成了新的、不同的非良性循环。为什么?数据不稀缺了。而在这个时候,机器化数据出来的东西做点频率表,做点交互表很简单。如果数据描述能够替代数据分析,这个世界一定会毁掉,因为数据想骗人太容易了。

接下来的过程当中,机器化数据由于资料收集简单,整理数据的过程非常容易。所以直接面向销售,这个面向销售就出现了充满荆棘的历程。

再看研究公司的结构化数据,大型公司由于没有应对,我在行业这么多年,一直在这些时期,有机会就在呼吁洞察这个词。实际上我们的研究员正在日益变成填数工具,而不是洞察。数据不再稀缺,你在机器化数据面前,你填数的过程当中,数据的真假还在存疑,这时候你不败谁败,必然败。而且别忘了机器化数据的成本趋近于零,所以大中型研究公司的解体、兼并、重组在不远的将来一定会频现,这是没有办法的趋势。

现在数据科学有七大危险趋势:





::__IHACKLOG_REMOTE_IMAGE_AUTODOWN_BLOCK__::13

3.数据的分析
以上七个危险趋势将直接导致数据分析中的危险,什么是数据分析?我先从最简单的案例说起。
案例一:简单表格的危险
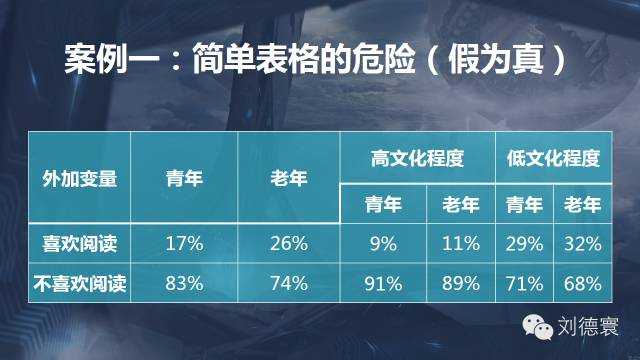
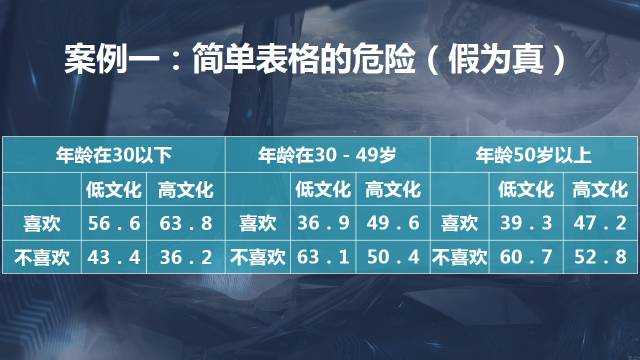
这个数据的结果,意味着什么?老年人比年轻人更喜欢这个东西。实际的结果呢?老年人和年轻人没有任何差异。高低文化之间有差别吗?所有的结果都显示高文化程度的比低文化程度的人更喜欢,总体上它就是相同的。
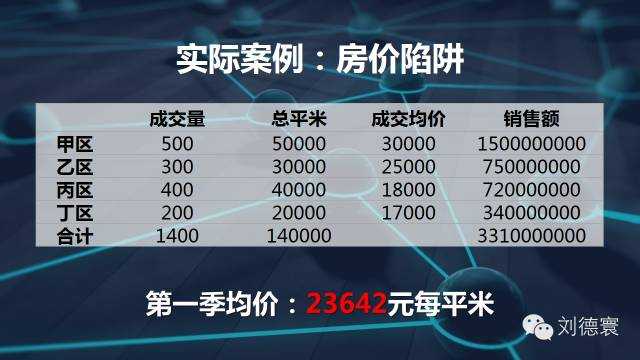
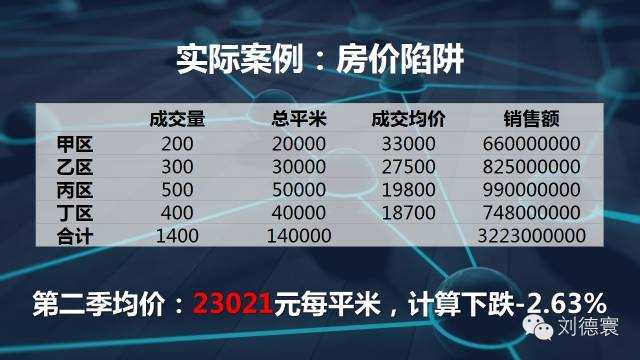
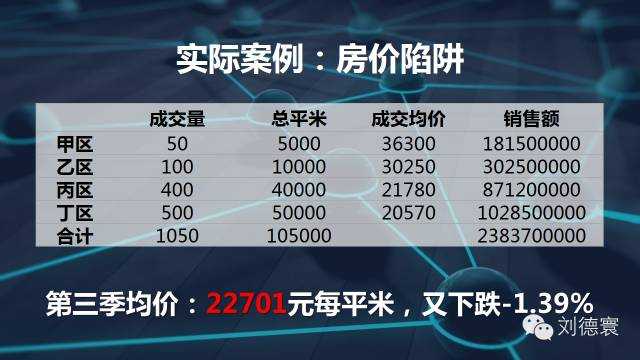
再看一个更加实际的案例。我们知道房价是怎么算的,房价是加权算术平均数。现在看一看房价,房子的均价跟房子的成交价格没有关系,跟销售结构有关系。所以在这个时候,房价的均价大约是这样的,我告诉大家房价在下一个季度全面上涨10%,但是销售结构略微有一点变化。房价下跌2.63%,大看清楚定价了吗?任何一个地方都上涨了10%,接下来销售结构一定会再变,房价又涨了10%,房价又下跌了,但是统计数字会告诉你下跌4%。
案例二:无关转相关系列
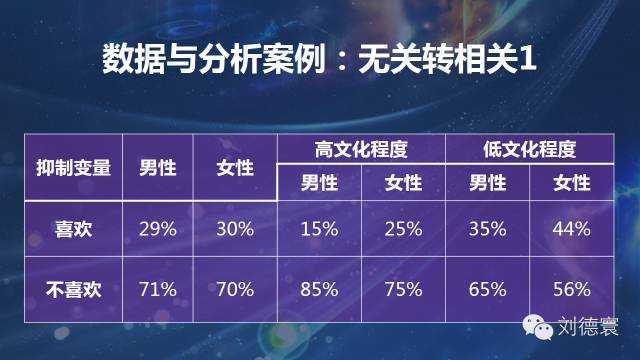
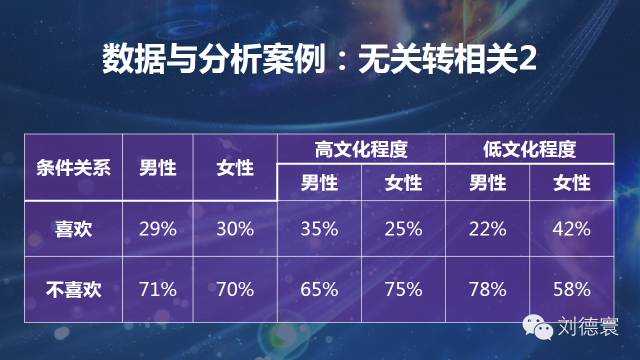
这是我1998年获宝洁论文奖的时候得到的模型,表面上一大堆无差别、无差异的情况,导致了什么情况呢?看起来没有差异,一个是男的比女的喜欢,一个是女的比男的喜欢,整体上没有差异。但是差别大吗?规律性强吗?
案例三:建模预测

我们在2011年用的词叫苹果熟透了,苹果在一个领域发展。2012年我在互联网大会上,在我们这个会场上我都说过华为将崛起。2013年我说过三星必然下滑,去年2014年也是一样的,这两个大会我都说过小米将面临问题,我不是神,但是模型能。2015年什么情况?我不想对任何一个品牌现在来说,大家关注我们要发布的手机人报告,那个时候我再开会,会详细地把这个结果告诉大家。
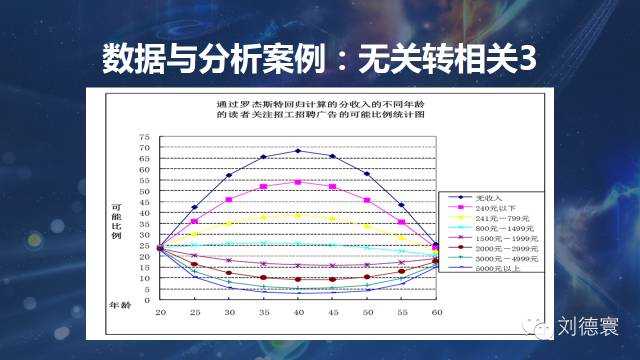
我让大家看一个结果,模型的基点预测点是这张图:
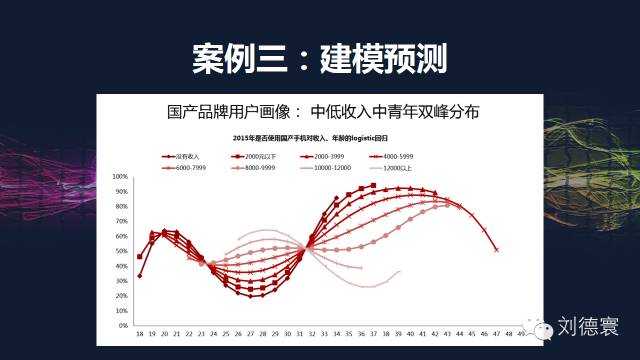
这个模型你能不能做出来?我一直在说,中国调查业从来不缺数据,从来不缺所谓的描述,只缺分析。如果被这些互联网公司,被码农牵着走,那不是笑话吗?他们能代表中国的分析能力吗?中国的分析能力不是他们,而一定是我们。
4.小结




更多阅读:
