
人类已经证明,大脑中的神经系统拥有为不断适应外界环境的变化而改变自身结构的能力。大脑内部的突触、神经元之间的连接可以由于学习和经验的影响建立新的连接。
相应的,感官替代(sensory substitution)这一天赋也存在人类技能树之中,例如有些天生失明的人能够通过将图像转换成声音学会感知人体轮廓形状的能力。
如果让 AI 拥有这种能力,它也能像蝙蝠和海豚一样,能够利用其耳朵通过声音和回声来‘看’周围的世界一样。
近日,来自谷歌大脑的一篇题为“The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning” 的论文证明了强化学习拥有这种 “感官替代” 的能力。

具体而言,作者在论文中设计了一系列强化学习系统,其能够将来自环境的每种感觉输入(sensory inputs)到不相同,却具有一定联系的神经网络中,值得一提的是,这些神经网络之间没有固定的关系。研究表明,这些感觉网络可以通过训练来整合本地收到的信息,并且通过注意机制的交流,可以集体达成一个全局一致的方案。
此外,即使在一个事件中,输入顺序被随机地排列多次,该系统仍然可以执行其任务。
1、证明过程
现代深度学习系统通常无法适应感觉输入的随机重新排序,除非对模型进行重新训练或者用户为模型纠正输入的顺序。然而,meta-learning 这项技术,可以帮助模型适应这种变化。例如 adaptive weights、Hebbian-learning 和 model-based 等方法。
在论文中,作者研究的 agents 都有一个共同的特点:在执行任务时被用来处理感觉输入,并将输入突然随机重新进行排序。受到与细胞自动机相关的自组织神经网络的最新发展的启发,作者在实验中将每个感觉输入(可以是连续控制环境中的单个状态,或者是视觉环境中的一块像素)输入一个单独的神经网络模块,该模块在一段时间内只整合来自这个特定感觉输入通道的信息。
在本地接收信息的同时,这些单独的感觉神经网络模块也不断地广播输出信息。参考 Set Transformer 架构,一个注意力机制将这些信息结合起来,形成一个全局的潜代码(global latent code),然后将其转换为 agent 的行动空间。注意力机制可以被看作是神经网络适应性加权的一种形式,在这种情况下,允许任意数量的感觉输入以任何随机顺序被处理。
实验中,作者发现每个单独的感觉神经网络模块,虽然只能接收到局部信息,但仍能共同产生一个全局一致的策略,而且这样的系统可以被训练来执行几个流行的强化学习(RL)环境中的任务。此外,作者设计的系统能够以任何随机排列的顺序利用不同数量的感觉输入通道,即使在一个 episode 中顺序再次被重新排列。

如上图 pong agent,即使在给它一个小的屏幕子集(30%),以一个重新排列的顺序,也能继续工作。
另一方面,鼓励系统学习的置换不变的观测空间的连贯性表示,会使 policies 更加稳健,泛化性更强。研究表明,在没有额外训练的情况下,即使加入含有噪声或冗余信息的其它输入通道,系统也能继续运作。在视觉环境中,即使只给它一小部分从屏幕上随机选择的区块,而在测试时,如果给它更多的区块,系统可以利用额外的信息来表现得更好。
作者还证明,尽管在单一的固定背景上进行训练,系统还是能够推广到具有不同背景图像的视觉环境。最后,为了使训练更加实用,作者提出了一个行为克隆(behavioral cloning)方案,将用现有方法训练的策略转换成具有理想特性的置换不变的策略。

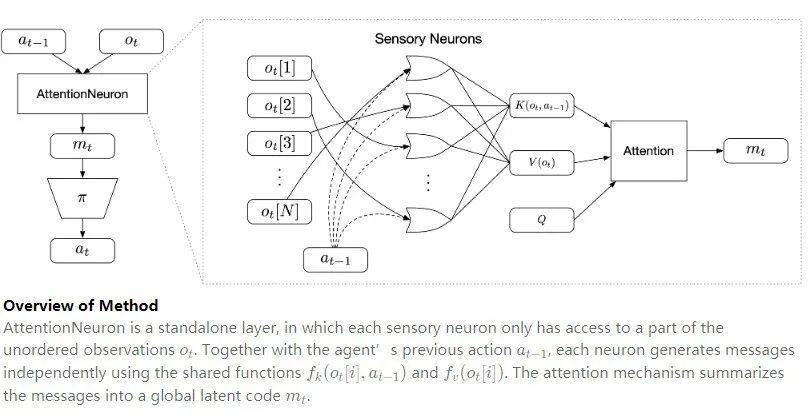
图注:方法概述
上图的 AttentionNeuron 是一个独立的层,其中每个感觉神经元只能访问 “无序观察(unordered observations)” 的一部分。结合 agent 的前一步动作,每个神经元使用共享函数,然后独立生成信息。
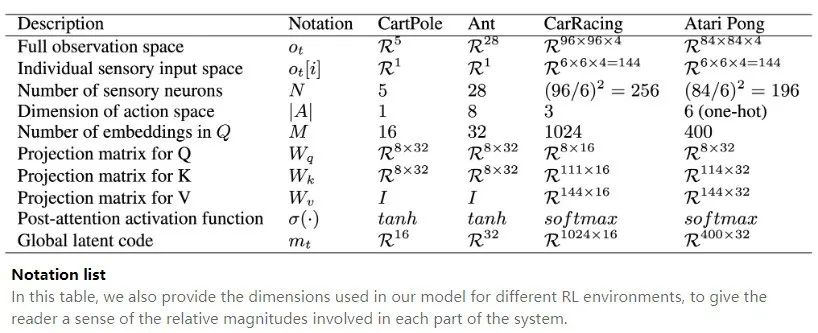
图注:符号列表
在上述表格中,作者还提供了我们的模型中用于不同强化学习环境的维度,以使读者了解系统中每一部分。

图注:CartPoleSwingUpHarder 中的置换不变 agent
在上述演示中,用户可以随时重新排列 5 个输入的顺序,并观察 agent 如何适应输入的新顺序。
演示地址:https://attentionneuron.github.io/

图注:车杆测试
作者报告了每个实验的 1000 个测试事件的平均得分和标准偏差。agent 只在有 5 个感觉输入的环境中进行训练。
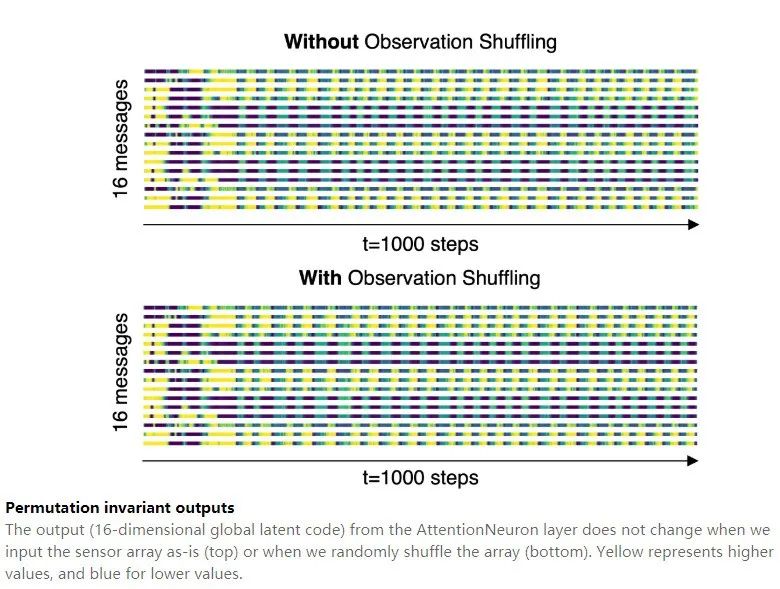
图注:置换不变的输出
当作者按原样输入传感器阵列(顶部)或随机重新排列阵列(底部)时,Attention Neuron 层的输出(16 维全局潜代码)不会改变。黄色代表较高的数值,而蓝色代表较低的数值。

图注:处理未指定数量的额外噪声通道
在没有额外训练的情况下,agent 接收 15 个按重新排列后顺序排列的输入信号,其中 10 个是纯高斯噪声(σ=0.1),另外 5 个是来自环境的实际观察结果。像先前的演示一样,用户可以对 15 个输入的顺序进行重新排列,并观察 agent 如何适应新的输入顺序。
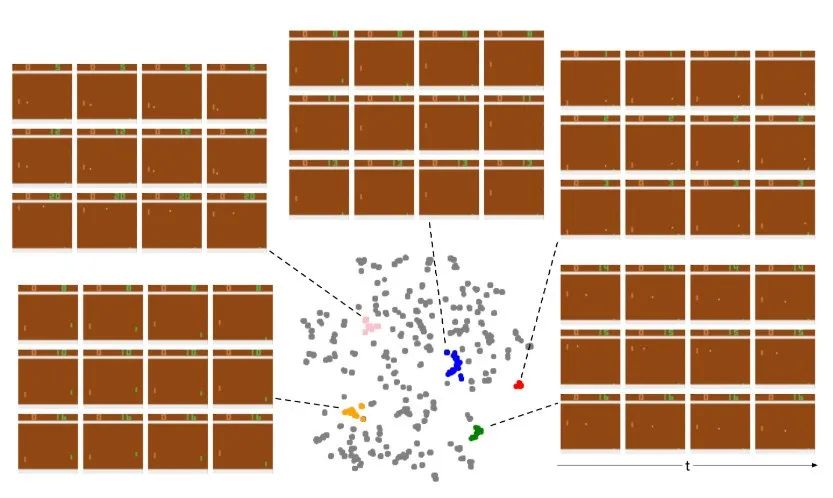
图注:注意力神经元层的输出在测试情节中的二维嵌入
作者在图中突出了几个有代表性的组,并展示了它们的抽样输入。每个组我们显示 3 个相应的输入(行),并对每个输入进行解堆以显示时间维度(列)。

CarRacing 的基本任务(左),修改后的洗屏任务(右)。
作者的 agent 只在这个环境中训练。如上图所示,右边的屏幕是 agent 观察到的,左边的是人类的视觉观察到的。人类会发现用重新排列观察的方式驾驶是非常困难的,因为人类没有经常接触到这样的任务,就像前面提到的 “倒骑自行车” 的例子。




2、讨论以及未来
在这项工作中,作者研究了深度学习 agents 的特性,这些 agents 可以把它们的观察作为一个任意排序的、可变长度的感觉输入列表。通过独立地处理每个输入流,并使用注意力整合处理后的信息。即使观测的顺序在一个 episode 中被随机地改变了多次,而且没有进行训练,agents 仍然可以执行任务。我们在下表中报告了每个环境的性能对比结果。
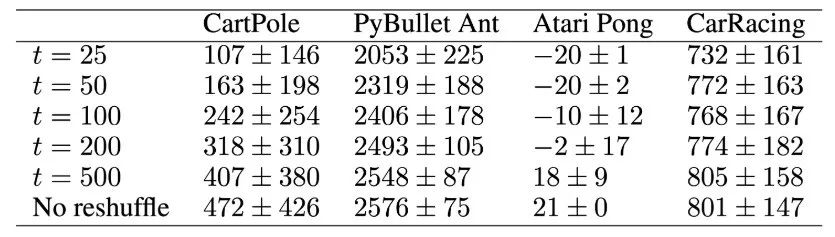
在展开的工作中重新梳理观测结果
在每个 episode 中,作者每隔 t step 重新打乱顺序观察。CartPole 任务差异较大,因此对它测试了 1000 次。其他任务,报告了 100 次测试的平均值和标准偏差。除了 Atari Pong,所有环境都有每集 1000 step 的硬性限制。在 Atari Pong 中,虽然不存在一集的最大长度,但观察到,每个 episode 通常持续 2500 step 左右。
通过打乱 agent 排序,甚至是不完整的观测信息,可以驱动它解释每个局部感觉输入的意义以及它们与全局的关系,这在目前的许多应用中都有实际用途。例如,当被应用于机器人时,可以避免由于交叉布线或复杂的动态输入 – 输出映射而产生的错误。类似于 CartPole 实验的设置,加上额外的噪声通道,可以使一个收到成千上万的噪声输入通道的系统识别出具有相关信息的小的通道子集。
局限性在于,对于视觉环境,patch size 的选择会影响性能和计算的复杂性。作者发现 6×6 像素的 patch size 在任务中很有效,4×4 像素的 patch size 在某种程度上也可发挥效用,但单个像素的观察却不能发挥作用。小的 patch size 也会产生一个大的注意力矩阵,除非使用近似值,否则计算成本可能会过高。
另一个限制是,排列组合不变的特性只适用于输入,而不适用于输出。虽然观测结果的排序可以以再次打乱,但行动的排序却不能。为了使置换不变的输出发挥作用,每个环节都需要来自环境的反馈以便学习自身和环境之间的关系,包括奖励信息。
一个颇为有趣的未来研究方向是使行动层也具有相同的属性,并将每个运动神经元建模为一个使用注意力连接的模块。有了作者的方法,就有可能训练一个具有任意数量的 agent,或者用一个单一的被提供了一个奖励信号作为反馈的 policy 控制具有不同形态的机器人。此外,在这项工作中,作者设计的方法接受以前的行动作为反馈信号。然而,反馈信号并不局限于行动。作者表示,其期待看到未来的工作包括环境奖励等信号,不仅能适应观察到的环境变化,还能适应自身的变化,以训练置换不变的 meta-learning agents。
更多阅读:
