

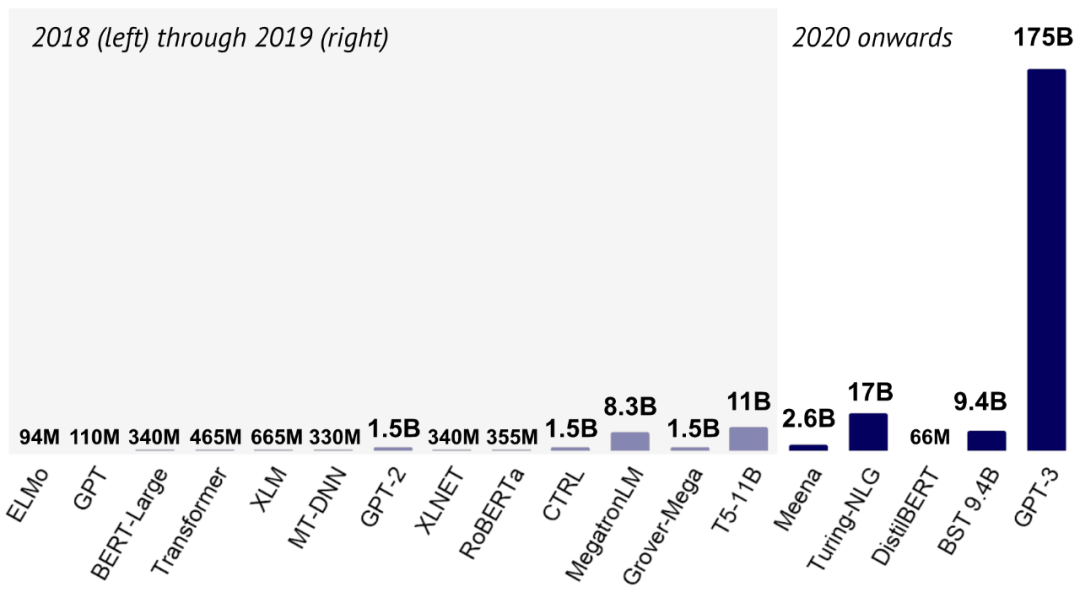
(图片来自 State of AI Report 2020)
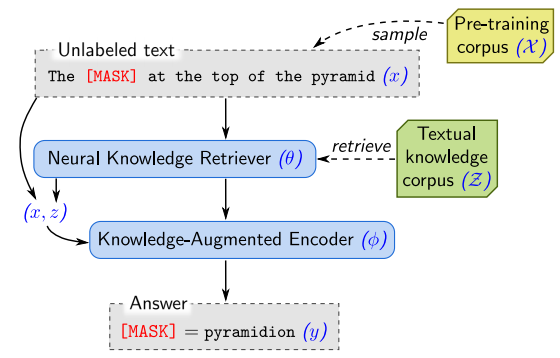
检索器和编码器经过了联合预训练。

(Gao et al., 2020)
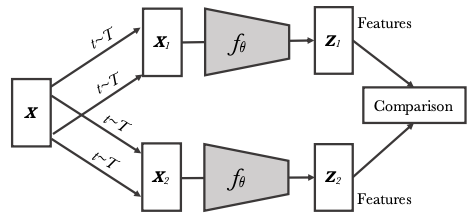
(Caron et al., 2020)

(Ribeiro et al., 2020)
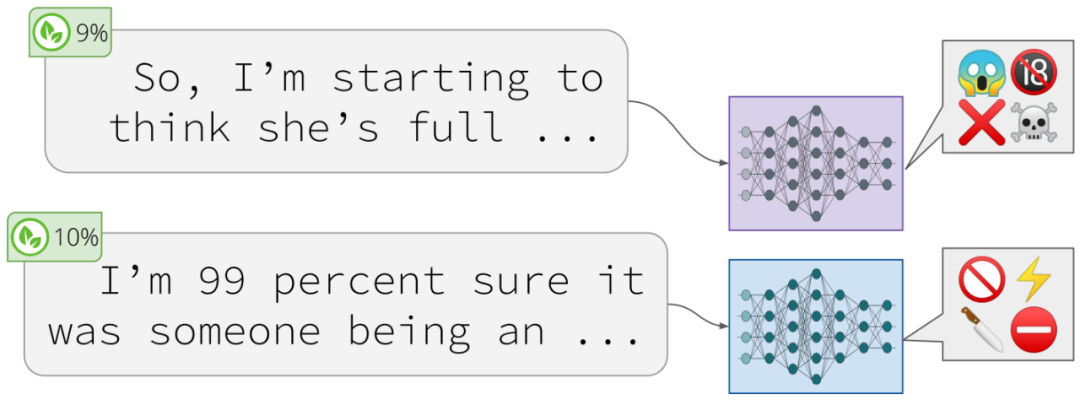
(Gehman et al., 2020)
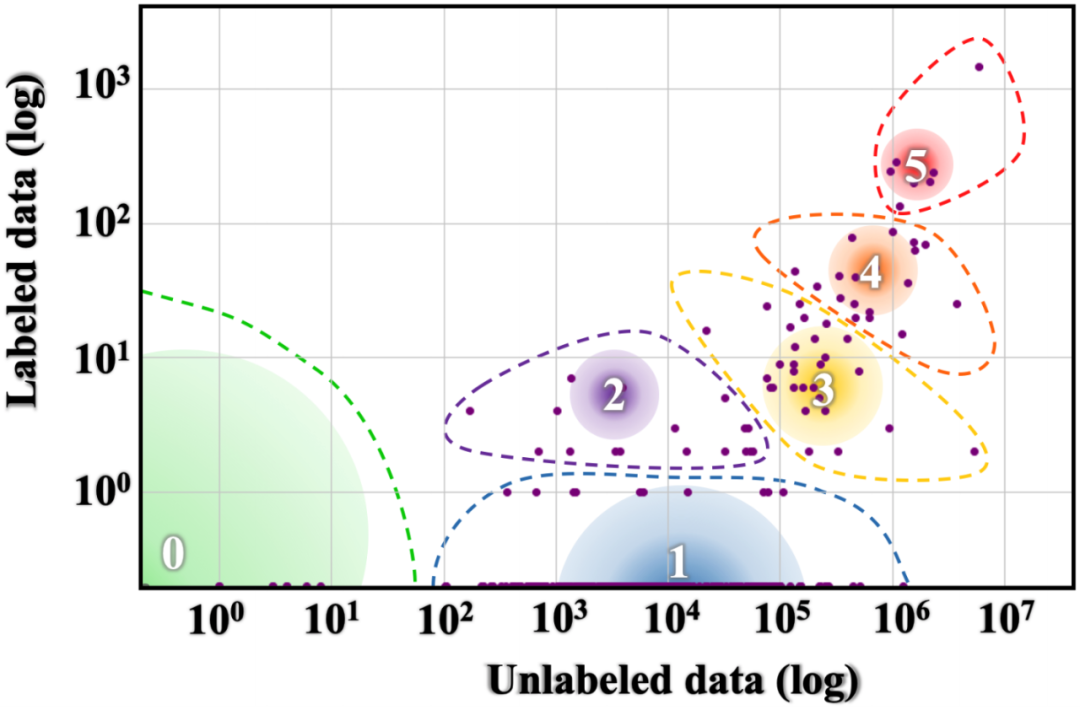
(Joshi et al., 2020)
- SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d’Hoffschmidt et al., 2020);
- Natural Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020);
- MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020);
- the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020);
- the CNN/Daily Mail dataset: MLSUM (Scialom et al., 2020)。
编译:机器之心
转自:机器之心
原文链接:https://ruder.io/research-highlights-2020/
图片来源于Pexels
更多阅读:
