
智能设备、语音助手正变得越来越无微不至,合成媒体可以针对我们的口味和喜欢提供个性化服务,我们暴露于多元化、多接口的智能生态中。然而过去一年中大规模的数据泄露、假新闻泛滥,当机器开始复制我们的声音、预测我们的行为时,人类该何去何从?凛冬已至,针对科技公司的监管缩紧,契机与风险并存的信息时代或许已悄然面临拐点。
Future Today Institute(简称FTI)近期发布了《2020年娱乐、媒体和技术趋势报告》,介绍了包括人工智能、合成媒体、区块链等共计16种前沿趋势,以及其中的157项具体革新,腾讯媒体研究院对报告进行了精选摘编,以飨读者。正如Neo在《黑客帝国》的结尾所说:“我并不知道未来是什么样的。我来这儿不是告诉你一切是如何结束的,而是告诉你一切是怎样开启的。”
以下为报告全文,让我们共同触碰技术与传媒业态的未来。

AI已经不再是一种趋势,而是计算机时代的第三纪元。本篇报告从AI的不同方面汇总了娱乐、媒体和技术的趋势。在新闻业中,AI成为了各大新闻机构的宠儿。路透社的Lynx Insight程序可以帮助记者挖掘大数据。《华盛顿邮报》的 Heliograf被用来报道选举和体育赛事。杜克大学记者实验室的ClaimBuster则可以帮助记者进行事实核查。
弗兰肯算法的扩散(Proliferation of Franken-algorithms)
算法只是定义和自动处理数据的规则。它们使用的是计算机可以理解的“如果……那么”逻辑。举个例子:如果网站浏览者的IP地址位于芝加哥,那么算法就允许他们直接进入;如果IP地址位于伦敦,则算法就会按照GDPR的要求先显示隐私和cookie政策。尽管人们可以直接按照自己想法设计某个算法,但是所有算法系统一起工作就有可能会带来问题。开发人员并不总是事先知道算法之间将如何一起工作。有时,几个开发人员团队都在独立地处理不同的算法和数据集,但是只有算法被设计出来以后才能看到如何运行。这也就是最近股市和电商网站出现崩溃的原因。对于像Facebook这样的大型公司而言这是一个艰巨的挑战,因为在任何特定时间,会有数十亿的算法同时工作,根本无法预测其运行结果。
专用、开放和自主开发的AI技术(Proprietary, Open and Homegrown AI Languages)
Python是一种具有许多预构建库和框架的先进的编程语言。麻省理工学院开发了一种名为Julia的开源语言,专注于数值计算,此外还有AI的提出者John McCarthy于1958年创建的Lisp语言。各大公司正在开始构建和发布自己的软件包以及用于AI应用程序的独特编程语言。Uber用Python编写了自己的概率编程语言Pyro。不同于OSX与Android或者早期Mac与PC阵营的对立,这一举动意味着AI生态系统未来将走向分裂。市场会发现在不同的AI框架和语言之间转化代价高昂。
问题数据集 (Problematic Data Sets)
公司自主训练研制的AI并不具备代表性,因此不能被广泛采用。MIT的研究学者发布了一款名为“Norman”的AI用来捕获识别照片。他们做了一组对比实验,一组系统采用的是经过训练的标准数据,另一组则没有经过训练,结果令人大跌眼镜:采用标准数据的系统显示出来是“一个棒球手套的黑白照”,而另一个系统则显示出的是“一个白天在国外被枪杀的男人”。一些为了生成自然语言的新系统于2019年发布。虽然这些系统都事先经过训练,但它们曾经用来学习自然语言的Reddit和亚马逊上的评论却被删除了。原因在于:Reddit和Amazon评论员都偏向白人和男性,因此这些人的话并不能代表所有人。这说明开发人员仍然面临挑战。如今已经变得很难从真人那里获得真实的数据来训练系统了,而且由于新的隐私政策出现,开发人员只能更多地依赖公共数据集和有问题的数据集。

Norman AI与标准化AI的照片捕捉对比
数据的深层链接(Deep Linking)
自智能手机问世以来,深层移动连接就已经使用户在手机所有软件中查找和共享数据。但是现在深层连接却让用户越来越难找到自己想要的信息。2019年,Yelp餐厅在其软件中标明了准确的联系信息,但是当客户点击时,他们就被跳转到Grubhub软件里订餐去了。即使客户关掉了软件并想直接打电话订餐,该软件仍将其转换成Grubhub上的号码,因为这样Grubhub可以将其归类为“营销”活动并向餐馆收取高额的佣金。如今深层链接有三种:传统深层链接,延迟深层链接和语境化深层链接。传统深层链接会从一个软件或网站重新定向您:如果单击某人在Twitter上发布的Baltimore Sun链接,那么理论上只要用户安装了Baltimore Sun软件,它就自动打开Baltimore Sun。延迟深层链接也直接链接到该软件(如果已安装),或直接链接到软件商店让用户先下载该软件。语境化深层链接的服务更强大,可以使用户直接从站点转到软件、从软件到站点或从软件到软件,还可以提供个性化信息,尽管故意向消费者隐瞒了整个过程。
AI云(AI in the Cloud)
过去一年,人工智能生态的领导企业一直在争夺“人工智能云共享”,以期成为值得信赖的AI远程服务提供者。在西方,该领域由亚马逊、微软和谷歌领导,其次是苹果、IBM、Salesforce、SAP和甲骨文。在亚洲,AI云由阿里巴巴等巨头主导。这是一个价值2500亿美元的行业,并且仍在迅速发展。纽约大学斯特恩商学院教授Arun Sundararajan说:“(这场竞争的)收益是成为下一个技术时代的操作系统。”娱乐和媒体公司将在未来几年找到更多使用AI云的方式。
AI芯片组(AI Chipsets)
对我们来说,平常笔记本和手机上搭载的CPU性能已经在不断提升,却满足不了机器学习的要求。它们的问题在于,缺少足够的处理单元,去完成下一个计算机时代所需的连接和计算。这时就需要一组新型处理器,华为、Apple、IBM等企业都在试水新系统的构建和SoCs。简而言之,这意味着芯片已经可以在AI项目中发挥作用,并且有更快的速度和更精确的数据——也不难预料到,几家企业在未来即将开展竞争。特斯拉的新型定制AI芯片虽然不如最初描述得那么引人注目,但已于2019年4月发布。Google的Tensor处理单元(或TPU)是专门为AI的深度学习而构建的,旨在与该公司的TensorFlow系统配合使用。

图表 2 Google Tensor处理单元
无处不在的数字助理(智能语音助理)(Ubiquitous Digital Assistants)
Siri、Alexa和天猫等数字助理使用语义和自然语言处理我们的数据,有时甚至在我们不知道要问什么之前提前预测我们下一步想要或需要做什么。FTI模型在2017年预测,到2020年,将有近一半的美国人拥有并使用数字助理,而FTI模型将继续追踪这个方向的趋势。亚马逊和谷歌主导了智能语音市场,但数字助理是无处不在的。现在,有成千上万的可跟踪响应的数字助理软件和小程序。新闻机构、娱乐公司、营销商、信用卡公司、银行、地方政府机构(警察、公路管理)、政治运动以及许多其他活动也在通过数字助理传达重要信息。
利用短视频生成虚拟环境(Generating Virtual Environments From Short Video)
芯片设计师Nvidia正在教AI用短视频片段构建逼真的3D环境,利用了此前生成对抗网络(GANs)的研究成果。Nvidia系统从开源数据集中生成的图形将用于自动驾驶领域。设计师使用了划分成不同类别(建筑物、天空、车辆、标志、树木、人)的短片段对GAN进行了训练,从而生成这些对象的新版本。自动生成虚拟环境的应用前景无穷:物流(仓库、工厂、运输中心)、城市规划模拟,甚至包括测试游乐园和购物中心内的客流量场景。

实际视频内容与AI生成内容
机器识别(Machines Performing Cognitive Work)
公司不再仅仅依靠AI系统执行繁琐的重复性任务。更先进的系统正在企业帮助优化工作流程并主动生成策略。这意味着人们并没有被机器人完全取代;相反,机器人是按照人类的工作能力而创造出来的。从仓库到审计公司,人工智能系统开始执行认知任务——在此过程中,人类只需要执行基础的操作。
亚马逊的自动化系统帮助提高仓库的效率、指导员工完成工作。沃尔玛使用计算机视觉来查找熟烂的农产品,其AI系统可以对仅从堆中取出坏苹果的人进行检查。在新闻编辑室中,类似的系统可以帮助记者筛选非常庞大的数据集以查找异常或识别人员。
机器进程自动化 (Robotic Process Automation)
机器流程自动化(RPA)使企业能够在办公室内实现任务和流程的自动化,从而使员工可以把更多时间花在更有价值的工作上。
Google的Duplex是RPA的一种,用于向他人进行常规电话通话。亚马逊使用RPA筛选简历,然后再对最优秀的候选人进行排序。在银行业务中,Blue Prism和Automation Anyware可以帮助员工处理重复性工作,提高员工们的生产力水平。这项技术将使媒体和娱乐公司能够在客户服务等许多不同领域中节省成本以做出更好的实时预测。
机器人 (Bots)
基本意义上的机器人是指,为自动完成某一特定任务而设计的软件应用。在媒体领域,机器人可被分为两大类:新闻型机器人(news bots)和生产力型机器人(productivity bots)。前者可以协助集合新闻信息,并自动为读者推送特定新闻事件;而生产力型机器人,则可以帮助新闻组织自动化他们的日常流程。
机器人的下一个重大进步不在技术方面,而是监管。在2018年的竞选中,我们看到了“僵尸网络”的复苏,“僵尸网络”是指发送误导性内容的计算机网络。由于人们对越来越多的机器人诈骗感到担忧,加利福尼亚州制定了一项新法律,该法律于2019年7月1日生效,要求机器人在在与人类的交往中必须清晰、醒目、合理地表明自己不是人类。

腾讯媒体+峰会现场Dreamwriter在写作
实时机器学习(Real-Time Machine Learning)
机器学习指的是一种应用算法来分析数据,从而可以更好地完成各种任务的系统,并且随着时间推移,它会越来越擅长这些任务。但这种系统也面临着效率问题:系统需要停下来解析数据。而最新研究表明,实时机器学习可以随数据获取而实时调整模型。这标志着数据移动方式以及我们检索信息方式的巨大变化。
比如说,即便是在多种语言混杂的情况下这种技术也能自动同声传译;它也可以对内容分发进行随时调整,从而为读者提供更具个性化的内容。比起刻板地使用历史数据(读者XX只喜欢体育类报道),实时偏好则能够将内容纳入推荐机制(读者XX在接下来的几天里对大选新闻的需求可能会更强烈)。
自然语言理解(NLU)(Natural Language Understanding (NLU))
对于Siri和Alexa等对话式AI系统而言,让机器准确了解某人的意思难度较大。这些系统都经过训练后最多可以理解语句中的代词。如果消费者问“狮子王在Cinemark剧院几点钟上映?然后在那附近停车”,系统会自动推断“那”的意思是“Cinemark剧院”。从技术上讲,此过程称为“插槽结转”。它可以使用句法语境来理解代词的意思,除非我们说了带有许多不同代词的复杂句子。事实是,在日常交流中我们的说话都很混乱随意、滥用单词,甚至只用语气词来传达意思。
2019年,亚马逊研究科学家在NLU方面取得了令人瞩目的进步,他们推出了新的架构,能够帮助Alexa在人类不说完整的句子的情况下也能很好地理解人类。

Amazon Alexa首页
机器阅读理解(MRC)
(Machine Reading Comprehension (MRC))
MRC使得系统阅读大数据、推断含义并且立即得出答案的流程成为可能。举个例子,当你搜索时,你是希望系统直接给出一个确切答案,还是提供给你一堆“欲知后事如何请看更多超链”的URL合集?让机器自己找出问题所在,这就是MRC。
在未来,MRC是实现强人工智能的关键性步骤之一,而近期,它则可以协助我们把技术手册、历史地图和医疗记录等各种资料转化为易于搜索的信息集合。
自然语言生成(NLG)(Natural Language Generation (NLG))
自然语言生成技术现今已被不少媒体与营销机构所应用,基于大规模的数据集来进行自动内容生产。NLG可实现的功能包括,集成关键词、提升SEO(Search Engine Optimization,搜索引擎优化,即利用搜索引擎的规则来提升网站的搜索排名)以及为用户批量提供个性化的内容。
Arria NLG、IBM Watson语音转文字技术、Amazon Polly、谷歌云语音转文字技术,叙事科学公司Narrative Science和自动观察公司Automated Insights利用大型数据集构建叙事以帮助非数据科学界人士更好地了解其组织中正在发生的事情。NLG在各个专业领域都有无数的用例,可为律师、政客、医生、顾问、金融分析师、市场营销人员及其他人士提供帮助。
机器学习中的实时语境(Real-Time Context in Machine Learning)
IBM公司研发的Project Debater可以通过消化大量文本,从语境中找出逻辑漏洞、假消息。虽然目前处于测试阶段,但已经能够通过实时学习利用实际环境分辨真伪信息了。
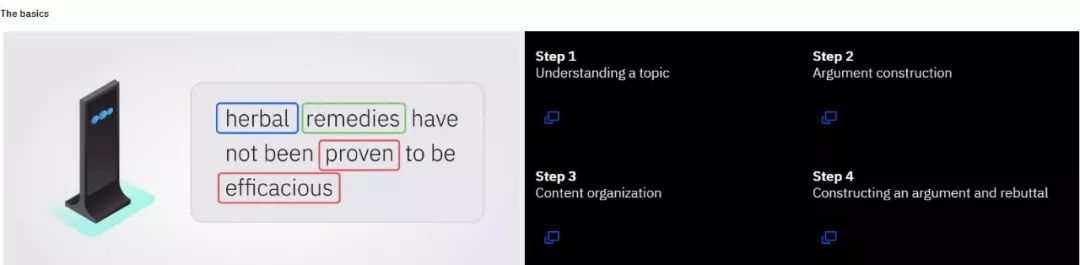
Project Debater的工作原理
多任务强化学习算法(General Reinforcement Learning Algorithms)
AlphaZero的团队开发的新算法可以学习多个任务。比如AlphaZero不仅在围棋上无人可敌,在象棋和日本象棋中也出类拔萃。
更快的深度学习(Much Faster Deep Learning)
深度学习(Deep Learning, DL)是机器学习中相对较新的分支,也会很快无形地融入到各个组织机构当中。设计者会结合包括文本、图像、视频、演讲等类似内容在内的各种数据库使用较为特殊的深度学习算法。
从概念层面上来讲,它不算新,最近更新的是计算处理能力和可用数据的数量。落实到实践上,这就意味着更多的人类事务可以被计算机自动完成,比如设计软件写代码。
DL受计算机网络运行速度的制约:几年前,用ImageNet网站中的数据集来训练图像识别功能,可能要花费一个月或者更长时间;而现在,Facebook可以在一小时内实现相同的效果。随着计算机提速和硬件技术的提升,系统也会以更加“超人”的速度完成任务。
ImageNet官网
强化学习与分层强化学习(Reinforcement Learning and Hierarchical RL)
强化学习(Reinforcement Learning, RL)是处理决策型问题的强力工具,应用于AI系统训练,使之拥有超出常人的能力。在计算机模拟过程中,一个系统尝试、失败、学习、实验,然后再次尝试——这一系列步骤都能飞速完成,且每次试错都会对它的未来尝试有所修正。
我们所熟悉的AlphaGo就是基于RL机制学习如何决定战胜人类棋手。但这项技术也存在问题:当智能体(agents)缺乏足够的监督(supervisor,简单来说监督就是设定输出值/目标,在数据中发现潜藏模式能更容易,而无监督式学习不设定输出值,下文在机器学习相关技术中出现的“监督”也是同一个概念),或是需要运行一项长时间的复杂任务时,可能会遇到困难。
这时,研究者将尝试应用分层强化学习(Hierarchical Reinforcement Learning)——能够发现高水准的行动,有条理地克服学习困难,最终以出乎人类意料的速度掌握新的任务。RL可以提升AI系统的“智能”,来使汽车能在非常规条件下自动驾驶,或者协助军用无人机实现之前尚未实现过的复杂动作。
持续学习(Continuous Learning)
现在,深度学习技术已经可以帮助系统学习,去以更接近人的所作所为的方式来完成复杂任务,但是这些任务仍然很具象,比如在某一项比赛中打败人类。并且它们需要遵循一个严格的程式:收集数据、设定目标、应用某一项算法。这一过程需要人工参与,也会花费不少时间,特别是需要监督式训练(supervised training)的早期阶段。持续性学习(CL)将偏重于构建提升自主学习与增量学习的技能,研究者未来还将持续扩展其能力边界。
多任务学习(Multitask Learning)
电影《龙威小子(The Karate Kid)》里,园丁宫地先生承诺教男孩Daniel空手道,但Daniel很快厌倦了日复一日的训练。对于Daniel来说,漆栅栏、汽车、无休止的“打蜡、封蜡”……这些事情看起来都毫无用处,肯定不能帮他学会空手道。当然,最后所有的杂务都被证明与空手道有关,这样的训练也帮他成为一名空手道冠军。提起这部电影,是因为研究者最近就在训练智能系统像Daniel这样学习。
当开发者使用机器学习时,他们要尝试用这种方式解决单个特定的问题。他们会监督智能系统微调,且不断修正,直到系统的表现符合预期。但是仅仅聚焦于单个任务,经常会指向无效结果——也许有比研究者发现的机制更好的解决方案呢?于是,新的研究领域,也就是多任务学习就产生了,让系统像Daniel这样,在各种各样的相关任务中寻求联系,探寻如何更好地解决问题。
生成式对抗网络(Generative Adversarial Networks (GANs))
换脸技术在2019一直热度不断。基于生成式对抗网络(或GANs)的换脸技术很容易实现。我们可以把GAN理解为无需任何人员参与的图灵测试。GAN是无监督的深度学习系统,由两个在相同数据(例如人的图像)上训练的相互对抗的神经网络组成。比如说,第一个AI创建看上去很真实的女人的照片,第二个AI将生成的照片与真实女人的照片进行比较。第一个AI根据第二个AI的判断重新对其生成过程进行一次又一次的调整,直到自动生成看起来完全真实的女人图像为止。
thispersondoesnotexist.com网站正是利用该技术不断生成逼真的照片,而实际上这些照片并不存在。GANs也被用来实现旧照片或画作的动态化。今年,斯科尔科沃科技学院和三星AI中心的研究人员利用该技术让蒙娜丽莎摇了摇头、让拉斯普丁演唱了碧昂丝的《Halo》。

ThisPersonDoesNotExist.com生成的人像
自动化机器学习(Automated Machine Learning (AutoML))
自动化机器学习(AutoML)是一种新的机器学习方法,它可以将原始数据和模型匹配在一起以显示最相关信息,从而帮助一些机构摆脱目前耗时且困难的传统的机器学习方法。现在,谷歌、亚马逊和微软都提供了许多AutoML产品和服务。
定制化机器学习(Customized Machine Learning)
Google的Cloud AutoML可以帮助用户可以上传自己的数据建构模型,就算非专业人士也可以训练机器学习。
AI的持续偏见(Ongoing Bias In AI)
AI有严重的偏见已不是秘密。这个问题是多方面的。举个例子,用于训练AI的数据集通常来自Reddit或亚马逊的评论以及Wikipedia等本身就充满偏见的地方。建立模型的人往往不知道自己存在偏见。随着我们的计算机系统越来越多地用于决策,我们可能会发现自己被算法分到一个组别中,虽然对我们而言可能没什么影响,但实际上可能产生巨大隐患。
AI偏见导致内乱(AI Bias Causes Civil Unrest)
实际上每天你都在主动地或被动地创建不计其数的数据(比如在Facebook上上传和标记照片、开车去上班等)。这些数据通常是在你没有发现的情况下被算法挖掘和使用的,并用于制作广告、帮助潜在广告主预测我们的行为、确定我们的抵押贷款利率,甚至帮助执法部门预测我们是否可能犯罪。
包括马里兰大学、哥伦比亚大学、卡内基·梅隆大学、麻省理工学院、普林斯顿大学、加州大学伯克利分校、国际计算机科学研究所等在内的许多大学的研究人员正在研究自动决策的副作用。你或者你认识的某个人可能会陷入算法错误的一面,比如说你会由于一些不透明或不易理解的原因不符合贷款资格,不能拿到特定药物或不能了解房租价格。并且越来越多的数据在不知情的情况下被收集并出售给第三方。
新闻报道可以使用计算来挖掘原本不会被发现的故事。CS技术可以通过两种主要方式帮助新闻业:使用计算方式的新闻业和进行有关计算的新闻业。2019年7月,《华盛顿邮报》成立了一个专攻大选的团队,该团队建立了一个计算政治新闻研究与开发实验室,并开展了实验以支持2020年大选之前邮报的数据工作。斯坦福大学的计算新闻实验室一直在为公共新闻开发新的计算方法。

The California Civic Data Coalition是一个由几家媒体联合成立的用于跟踪政治资金的数据开源档案库
计算图像的生成
(Computational Image Completion and Generation)
现在,每个拥有智能手机的人都可以使用计算摄影工具。他们可以在合影中把闭上的眼镜睁开、在运动画面中寻找最佳帧并清除我们自拍照中的瑕疵。所有这些都是实时的,而无需启动其他照片编辑软件。现在,我们可以在场景中无缝添加或删除对象、更改阴影等等。
显然,这里对记者有伦理要求——在什么情况下对照片允许什么程度的编辑?同样,记者在将其用于报道或故事之前,应该开发一项技术可以自动显示该照片已被编辑。
自动生成文章(Automated Versioning)
总部位于瑞士的Tamedia的记者在本国2018年大选期间尝试采用了生成技术。Tamedia用一个名为“ Tobi”的决策树算法自动生成了文章,详细描述了由私人媒体组织的30家报纸所涵盖的每个城市的投票结果,并同时生成了多种语言、总计39,996个不同版本的选举报道,每篇平均250字,并将其发布到Tamedia的在线平台上。每篇报道都标记出了该报道是由算法编写的。随着更多的尝试,新闻和娱乐媒体公司能够开发相同内容的多个版本,从而覆盖更广泛的受众或大规模生产内容。
Tobi的Twitter账户
生成自然语言以调节阅读水平(Natural Language Generation to Modulate Reading Level)
自然语言生成(NLG)是一项能够生成人类指定使用语言的处理任务。NLG可用于重写各种不同阅读层次的内容,为书籍出版商和新闻媒体机构都提供了巨大的可能。随着图书出版商和新闻机构在寻找新的收入来源,NLG不仅将用于撰写报道,而且还将为具有不同阅读水平的读者创建不同的版本。这是因为基本语料库(构成故事的数据)不会改变,但是可以调整词汇量和细节。
例如,关于伯克希尔·哈撒韦公司(Berkshire Hathaway)季度收入的报道可以用许多不同的方式来表达,分别面向金融专业人士、高中经济学课程、以英语作为第二语言的学习者以及非英语国家。同样,NLG可用于自动创建书摘和摘要等工作量大的任务。使用NLG自定义编写不同版本的报道可以帮助媒体机构拓展全球业务规模而无需雇用其他人员。但是,NLG同样可被用于造假,这意味着未来将要进行监管。
数据挖掘群体行为(Datamining Crowds)
计算新闻技术使记者能够查询我们的被动数据(比如我们的在线活动、健康记录、位置等),从而学习或了解新事物。我们的数据不仅会跟踪我们的行为,而且任何人都可以用它进行搜索、收集和分析。我们预计,更多的新闻机构以及营销商、政治活动家和其他团体将开始创造性地利用数据。因为我们的思维影响行动(例如搜索“欧盟是什么?”),我们的行动产生数据,而这些数据可用于了解有关我们的信息。
算法事实核查(Algorithmic Fact Checking)
误导性的虚假信息污染了互联网和我们的社交媒体环境,每天的消费者都不得不与虚假信息做抗争。尽管我们在全球范围内进行了大量的事实核查工作,但事实证明,用于传播假新闻的算法比人类事实核查者的速度更快。
德克萨斯大学阿灵顿分校和谷歌的研究人员一直在研究使用框架语义的自动化技术。框架是描述了特定类型事件、情况、对象或关系及其参与者的示意图。研究人员扩展了一个名为FrameNet的系统用来专门为包括自动事实核查在内的功能构建新框架。
在屏事实核查(On-Screen Fact Checking)
杜克大学和得克萨斯大学阿灵顿分校的研究人员发明了ClaimBuster,它可以对任何句子中的事实评分。该系统使用来自直播活动的音频或视频并将其转换为文本,用过滤器识别其中有关事实的语句,然后将这些语句与数据库进行匹配。
ClaimBuster官网
合成数据(Synthetic Data)
研究人员并非总能获得完整的健康、医疗、运输和人口数据。因此,一些人正在开发和试验合成数据集,用来在AI中执行有意义的分析和训练模型。但是合成数据集通常会漏掉重要信息或出现偏差。
MIT信息与决策系统实验室的Data to AI Lab的研究人员正在开发一种机器学习系统,用以自动创建合成数据,然后将其用于开发和测试数据科学算法和模型。他们提出了合成数据库Synthetic Data Vault (SDV),该数据库能够学习和开发用于多种目的的多元模型。记者需要了解何时使用合成数据,新闻机构应制定有关何时使用合成数据以及如何告知消费者报道使用了合成数据的道德准则。
合成并生成内容核查(Synthetic and Generated Content Authentication)
AI可以用来发现哪些文本是算法写的而不是人类写的。哈佛大学和MIT-IBM Watson AI Lab的研究人员开发了一种用于识别算法何时生成文本的工具。
Giant Language model Test Room(简称GLTR)使用AI来确定文本中的常用词,并可以判断句子是否看起来太有预测性以至于不像真人所写。该工具预期可以被用来识别虚假或误导性新闻、机器人生成的内容及伪造品。
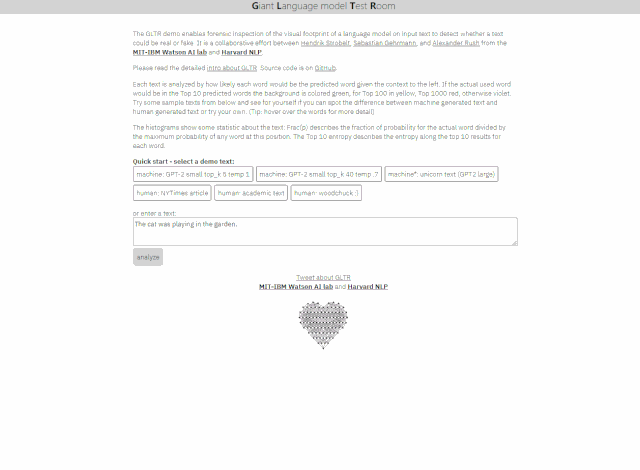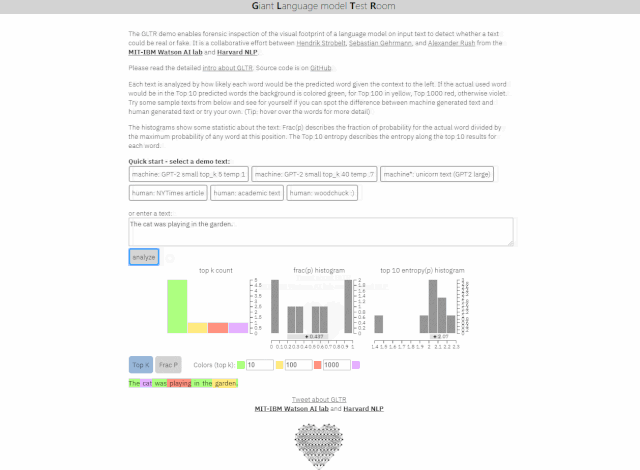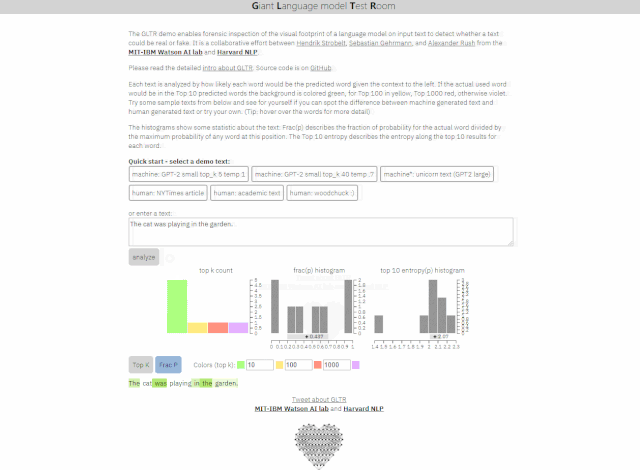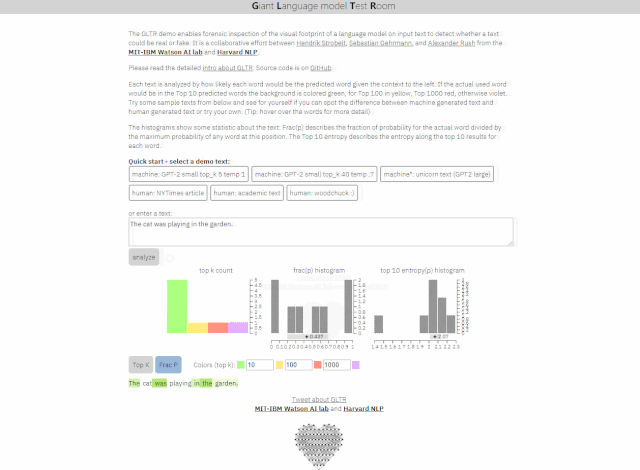
Giant Language model Test Room文本识别(动图)
声音识别技术(Voiceprints)
声纹是一个人声音的独特特征。现在新的机器学习技术与语音录制的庞大数据集相连接可以帮助研究人员能够通过人们说话时产生的声纹进行识别。
卡内基·梅隆大学(Carnegie Mellon University)的研究人员开发出了一种可以使用声纹就可以构建3D面部的生成技术。执法机构正在应用该系统识别恶作剧呼叫者以及欺骗当地派遣特警就为了报复他人的人。
个性识别(Personality Recognition)
新兴的预测分析工具会记录用户的数据、行为和偏好,这些数据可以反映出用户的个性并预测用户在任何情况下的反应。2018年,Cambridge Analytica就使用算法分析帮助Donald Trump赢得了大选。政治候选人、律师事务所、营销商、客户服务代表和其他人员都在使用新型系统,这种系统可以查看用户手机网上活动、电子邮件和对话,实时评估用户的性格。最终目的就是判断用户的特定需求。
ElectronicArts正在开发一种可以评估多人视频游戏玩家性格的系统,从而根据他们的游戏风格、对话风格和花钱意愿更好地匹配玩家。
在现实世界中,保险承销商正试图通过用户订阅的杂志和网站、发布到社交媒体上的照片等等来评估用户的个性,以便确定其投保风险。一些贷款方已经开始使用个性算法来预测用户未来的商业交易了。(数据显示,如果两个具有相同专业和个人情况的人同时借款,那么拥有较高大学文凭的人更可能还清债务。)
情绪识别(Emotional Recognition)
2018年,亚马逊申请了一项新系统的专利,该系统可以根据用户过去及现在的互动来检测用户的身心健康状况。如果亚马逊检测到该用户生病了,就会建议用户一小时内服用止咳药。
汽车制造商Kia于2019年在CES上首次亮相了它的实时情感识别系统(R.E.A.D.)。该系统可以通过传感器监控乘客面部表情、心率和皮肤电活动来调节车内环境以乘客的情绪状态。

Kia的R.E.A.D.系统
情感计算(Affective Computing)
情感计算属于跨学科领域,涵盖计算机科学、心理学和认知科学。麻省理工学院的研究人员正在研究一种机器学习算法,可以通过从我们的可穿戴设备(智能手表、健身追踪器)收集的皮肤电活动了解我们的情绪并作出响应。但是其他来源的数据也可能派上用场,比如我们的皮肤、脸部和与他人的对话。分析师推测,到2023年情感计算将成为一个价值250亿美元的产业。
合成媒体已经比比皆是了,比如虚拟的日本流行歌星初音未来(于2007年首次亮相)、由艺术家Jamie Hewlett和音乐家Damon Albarn合作创造的英国虚拟乐队Gorrilaz(于1998年发行了第一首单曲)。它们都是通过算法创建或改动的媒体。

初音未来全息演唱会
语音合成(Speech Synthesis)
语音合成也被称为“合成语音”或“文本转成语音技术”,它模仿了真实的人类语音并将其应用到各种界面中。通过借助足够的数据和培训,语音合成系统可以了解任何人的频谱频率并产生某个人的数字声纹。
Synthesia是一家使用此技术通过自动重制面部动画来配音的公司,适用于国际广泛发行的电影。演员的面部表情和嘴巴可以重制以匹配配音。
调节定制语音 (Modulating Custom Voice)
生成算法可以创建听起来像原始声音的合成声音,并且可以将这些声音按所需的音高和音调调制。
总部位于蒙特利尔的AI公司Lyrebird构建了一种语音模仿算法,能够生成难以察觉出来的合成语音。它使用的语音样本数据库既可以在公共存储库(YouTube、Vimeo、Soundcloud)中找到,也可以由用户上传。
随着时间的推移,人工智能不仅学会了识别语调,而且可以识别情绪节奏。只要有足够公开可用的音频文件来构建数据集,就可以伪造自己和最喜欢的明星之间的对话。它很快就可以匹配并快速生成针对每个消费者的个性化合成语音。
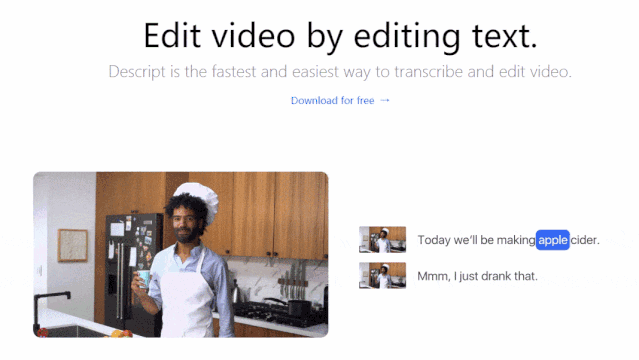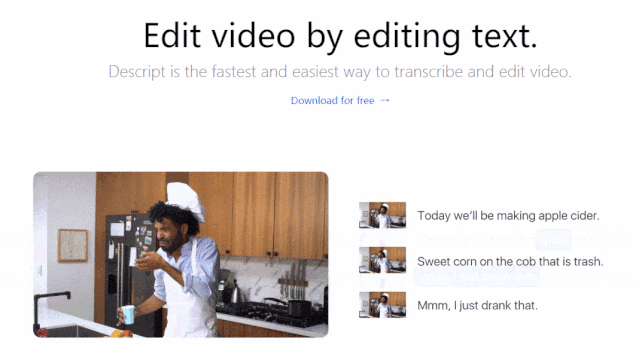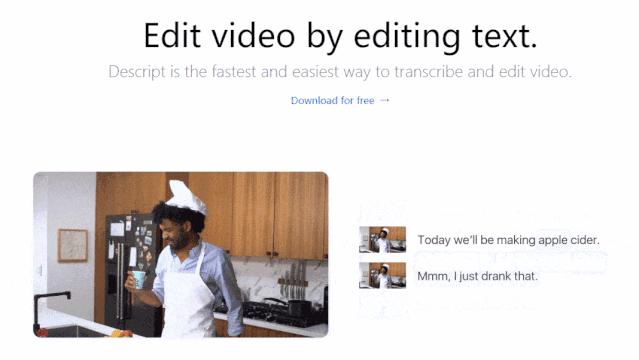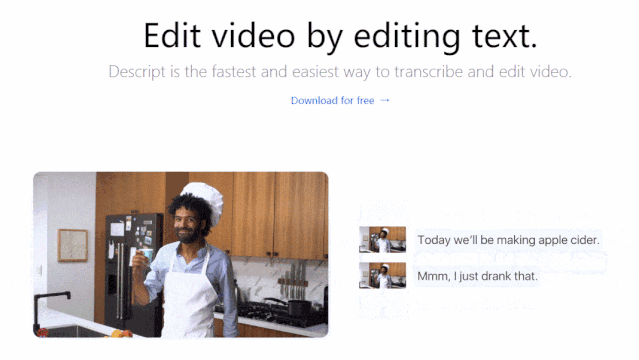
Lyrebird视频编辑
语音欺诈(Voice Fraud)
合成媒体一直以来都存在一个问题:不怀好意的人可以用它来误导人们,欺骗语音认证系统以及伪造音频记录。呼叫中心软件制造商Pindrop的一项研究显示,仅去年一年,语音欺诈就给拥有呼叫中心的美国企业造成了140亿美元的损失。作为ASVspoof 2019 Challenge的一部分,Google一直致力于合成语音数据集,这是一项开放源代码,旨在帮助制定对抗欺骗性语音的对策。
机器生成图像(Machine Image Completion)
如果计算机系统可以访问足够多的图像,那么它就可以填补照片中的漏洞。对于专业摄影师以及每个想要拍出更好自拍照的人来说这是十分实用的应用。如果拍出来山的前景不清晰或者皮肤有瑕疵,都可以换用另一个版本以生成完美的图像。
但是我们如何在现实与改善后的场景之间划清界限?在没有标签或披露信息的情况下,应该修改照片到什么程度?网上交友者、记者、营销者和制定政策的人都应该思考这些问题。图像生成对于执法人员和军事情报人员来说也是有用的工具——计算机现在可以帮助他们识别视频帧里的人或物。
考虑到机器学习算法和数据集上的偏见,图像生成可能会成为有关隐私和设备的讨论的一部分。斯科尔科沃科学技术研究院和三星AI中心的AI研究人员使用机器图像生成技术使旧照片和著名画作(如《蒙娜丽莎》)动了起来。

动起来的蒙娜丽莎
深层行为学习与预测(Deep Behaviors and Predictive Machine Vision)
麻省理工学院CSAIL的研究人员不仅在训练计算机识别视频中的内容,还让计算机可以预测人类接下来会做什么。如今计算机可以通过观看YouTube上的视频和电视节目预测两个人是否可能拥抱、亲吻、握手或击掌。
这项研究将使机器人能够更轻松地进行导航,并通过学习我们的肢体语言来与人类互动。它也可以用于销售、操作机器或许学习。
语音、声音和视频的算法生成(Generative Algorithms For Voice, Sound and Video)
芯片制造商Nvidia的研究人员于2018年开发了一种新的生成算法,该算法使用生成式对抗网络创建了逼真的人脸。该算法还可以在其系统中调整各种元素,例如年龄和雀斑密度。
加州大学伯克利分校的一个团队开发了一种软件,该软件可以将一个视频中的人的动作自动传输给另一个视频中的某个人。我们一直在训练计算机观看视频并判断真实世界中相应的声音,比如一个木槌敲打沙发时会发出什么声音。
这项研究的重点是帮助系统了解对象在真实世界中如何相互作用。但该技术也具有欺骗性:2017年,华盛顿大学的研究人员开发了一种模型,模型中奥巴马在发表一段现实生活中从未发表过的演讲,但足以以假乱真。合成视频与旨在提供真实内容的AI混在一起的现象将使问题变得更加棘手。
语音搜索优化(Optimizing For Voice Search)
对话网络无处不在。通过语音控制我们可以立即从智能扬声器、汽车仪表板、电视遥控器和智能手机的数字助理那儿获取信息和其他内容。随着语音搜索的普及,发行商等组织有了新的战略思考:是否可以针对语音搜索对内容进行优化?Audioburstis公司的技术可以从广播等来源中提取并分析音频,将其语境化并可以进行搜索,帮助AI动力汽车提供聆听服务。
下一代原生视频和音频故事形式(Next-Gen Native Video and Audio Story Formats)
通过具有响应性视觉、触觉和音频界面的消费类技术的发展,人们正在开发非新的叙事方式来吸引观众。新闻媒体和娱乐组织已开始探索这些新颖的、个性化、交互性和具有沉浸感的叙事模式。虽然这无疑将为消费者带来更好的体验,但新闻和娱乐媒体公司必须提前做好规划,以便在未来可以通过口述进行汇总和传递内容摘要。

《黑镜:潘达斯奈基》剧情就采用了“互动视频”概念
人与机器的接口(Human-Machine Interfaces)
诸如Siri、Alexa和Google Assistant之类的语音接口正在变得越来越复杂,但是研究人员们已经开始展望未来了:将人类和哺乳动物直接与计算机相连。人们可以通过人机交互界面用思想进行交流,为中风和瘫痪患者提供了新的选择。
混合现实,也称为扩展现实,可以数字生成、增强或者操控环境,包括虚拟现实和增强现实。MR通常通过头戴式显示器(HMD)或移动设备进行体验。在过去的十年中,MR已经吸引了越来越多的注意。到2020年,我们将看到MR继续在各个行业和新的市场上逐渐普及。许多人希望在未来十年中,随着作为MR催化剂的5G的普及,该技术将成为我们日常生活的一部分。
全息图像(Holograms)
全息图像是指看起来像是在三维空间的投影图像。到2024年,全息图像市场预计将超过50亿美元,其中广告占比较重。在消费品方面,专业相机品牌Red宣布推出其全息图像生成的Hydrogen 2手机,华为和三星也在开发具有全息图像功能的移动设备,包括全息通信。
在娱乐领域,像洛杉矶的BASE Hologram这样的公司继续推出以去世的艺术家的全息投影为特色的“现场”音乐会,惠特尼·休斯顿将于2020年巡回演出,但他们尚未掌握在全息影像中多角度渲染3D全息图所必需的体积投影,因此门票销售有限。为了避免引起人们对动物权利问题的争议,德国马戏团Roncalli推出了一种可以展示动物表演的全息眼镜,既经济高效,又不残忍。

BASE Hologram还原了过世歌手Buddy Holly的演唱现场
360度全向视频(360-degree Video)
360度视频使用专门的摄像机拍摄,旨在捕获全向素材。渲染视频后,观看者可以使用鼠标、触摸屏或运动控制手势来旋转视角、浏览录制的场景。
YouTube,Facebook和Vimeo都提供360度视频,ABC、Fox和CNN等主要网络媒体也都拥有专用的数字频道,用于播放涵盖新闻、体育和娱乐在内的沉浸式内容,并且有越来越多的媒体紧随其后。GoPro、Insta360、Ricoh和小米的便携式360度摄像头很快就会增加用户拍摄和社交共享的360度视频的数量。

YouTube上的恐龙360度全景视频
增强现实(AR)(Augmented Reality)
AR并不像VR那样要模拟整个新环境,而只是在你的自然视野里放置几个数字元素。AR可使用头戴式显示器或智能眼镜体验,谷歌和微软等领先品牌以及Magic Leapand、Vuzix和Meta的产品都在开发中或已经投放市场。
在各大公司争相研发AR头戴式耳机时,移动设备为普通消费者提供了最方便的AR体验。一些电影院和NBA场所引入了可在移动设备上播放的AR游戏,Quartz的移动应用将AR功能整合到了某些新闻报道中,而谷歌用AR完成了外国语的实时翻译。
强化图文功能的AR(AR as a Tool to Enhance Print)
AR将有效助力印刷业发展,媒体公司正在用AR印刷品来进一步吸引消费者。AR可以整合内容和广告两个不同的渠道。诸如blippar等服务可以添加只能使用智能手机解锁的动画、模型或图像。
像Max Factor和Net-A-Porter之类的公司已经允许用户用AR扫描自己喜欢的商品并直接通过手机购买。AR驱动的广告活动的成功意味着媒体公司和广告商的双赢,由于价格较低,品牌将继续使用AR印刷广告。
虚拟现实(VR)(Virtual Reality)
虚拟现实是一种计算机模拟环境。佩戴VR眼镜或者将手机嵌入特定设备,即可获得身临其境的体验。近年来VR在娱乐内容领域有了重要发展,新的艾美奖项如交互式媒体等层出不穷,好莱坞导演达伦·阿罗诺夫斯基和罗伯特·罗德里格斯等也在使用VR设备拍摄。谷歌、索尼、三星和HTC都在出售VR头戴设备。
2019年,Facebook旗下的Oculus推出了Quest头戴设备,是Oculus Rift设备的独立替代品,只能在与PC捆绑时使用。任天堂最近也进入了沉浸式市场,为其流行的Switch游戏设备推出了VR套件。也可以通过将手机滑入专用面罩中来构造耳机。“站立式” VR是从相对固定的角度观看的,与“房间规模” VR不同,后者允许观看者在物理空间中更自由地行走,其数字环境反映了他们的真实生活。

Oculus Quest设备
流媒体(Streamers)
2017年的第四季度见证了50万名消费者抛弃了他们的有线和卫星电视服务。而用户持续为电视付费的两大原因在于,电视能够观看直播,和价格优惠的互联网与有线服务套餐。——显然这两个理由都不大像传统有线电视能持续的优势。网飞和亚马逊是世界上两大流媒体。到2020年,所有人的目光都将集中在拥有Marvel和Star Wars的新Disney+服务上,更何况它还包括了Hulu和ESPN +在内。
未来预期我们会看到Amazon Fire Stick、Google Chromecast和Roku等更多流媒体设备的份额增长,和有线卫星电视订阅的稳定消退。而流媒体服务则会侵蚀本地广播新闻市场,也会使较长时长的电视新闻节目陷入劣势。
OTT流媒体服务饱和
(Saturation of OTT Streaming Services)
可能是因为HBO Now的成功,2019年各大网络媒体都在推出其顶级流媒体服务。Disney+正在启动自己的OTT服务,预计AT&T/DirecTV、Viacom和Discovery也将提供新的服务或更新已有服务。OTT流媒体服务市场已足够拥挤,在不久的将来它将更加饱和。
联网电视(Connected TVs)
从2019年5月开始,所有与三星联网电视都置备了针对Apple设备的集成屏幕镜像和内容投射功能,并可以访问本机Apple TV和iTunes应用。它实际上绕过了单独的Apple TV设备,但其他大多数电视都必须通过这个设备购买Apple内容。这就使三星吸引了大部分Apple用户。
联网电视预计在普通家庭的普及率会更高,这可能与流行的流媒体服务或聚合设备,例如Amazon Prime Video、Roku、Hulu、YouTube、Showtime Anytime、iPlayer(仅限英国)、All 4(仅限英国)、 Playstation Now、HBO Now、DirecTV Now、iTunes和Netflix。
媒体机构可以利用联网电视和独家集成作为竞争策略来提供更丰富的内容来留住并扩张受众。

三星联网电视
电竞(e-Sports)
电子竞技是一个快速发展的对抗性数字游戏产业,能够专业地制作游戏并通过流媒体直播或面对面等方式面向受众。尽管这种组织化对抗性的游戏已经发展了数十年,但近年来,游戏技术和流媒体功能的发展导致其受欢迎程度和合法性出现了巨幅增长。例如Fortnite(堡垒之夜)是去年最火的游戏之一,仅2018年就收入24亿,收获用户超过2.5亿。
混合现实体验馆(Mixed Reality Arcades)
就像上个世纪80年代的电子游戏一样,游戏形式日渐流行,但大多数人并不能负担设备费用,所以如同当年的游戏厅,混合现实体验馆应运而生。
Nomadic是MR街机的初创者,在佛罗里达州奥兰多市和加利福尼亚州圣拉斐尔市都开设了线下MR游戏体验店,玩家可以在店内带着VR头盔和背包在房间里探索。
混合现实体验馆无处不在,使每个人都可以参与到很多游戏中来,但这次却不需要等待很久了。Virtual World Arcad公司提供了无限虚拟现实时间的会员套餐。在东京,混合现实体验馆提供的不仅仅是基础游戏,还包括摇摆式安全带、飞行平台和模拟蹦极跳、飞行,甚至可以从摩天大楼上摔下来。

Virtual World Arcad混合现实体验馆
被迫做出选择的平台(Platforms forced to pick sides)
由于假新闻、仇恨言论等滋生,在线平台和社交媒体将越来越多地投资于平台管理:可以使用人工审阅,也可以使用能检测到仇恨或问题语音的算法。
Amnesty International在Twitter发布了名为“Troll Patrol”的项目,该项目发现将近1000名女性政客和记者收到的推文中,每30秒就会有一条是“侮辱性”言论。此外,政策明确至关重要。但是,真正的问题在于将是选择哪些利益相关者参与定义这些规则,因为任何决策都可能被政治化。
限制批量消息(Restrictions on Bulk Messaging)
新闻机构目前依靠第三方平台来吸引消费者。而限制批量消息将导致新闻媒体与受众的互动变得更加困难。自2019年12月起,WhatsApp将不再允许自动或批量推送消息。
在当今媒体平台比电子邮件更受欢迎的时代,Facebook拥有的WhatsApp一直是新闻机构每日发送新闻消息的重要工具。该公司宣布,它将在12月7日新限制生效后对在平台上批量发送消息的任何个人或公司采取法律行动。
这些限制在很大程度上与未来平台限制法规有关。WhatsApp在印度拥有超过4亿的用户,虚假信息和谣言传播引发了一系列暴民动乱。
美国本地新闻机构的新增长点(New Interest in America’s Local News Outlets)
Pew研究中心的数据显示,2008年至2017年间美国报纸新闻编辑室的雇员下降了45%,创下了美国本地报纸合并和关闭数量的纪录。目前新闻机构正在为重建本地新闻业做着大量努力。
2019年,谷歌的“新闻计划”与美联社合作,为新闻编辑室构建了一个可以直接共享内容及其报道计划的工具。该公司还与McClatchy合作,建立了覆盖当地的数字新闻站点——第一个站点将设在俄亥俄州的扬斯敦,那里的日报《Vindicator》最近刚刚关门。2018年,Facebook和Lenfest新闻学院资助启动了本地新闻订阅加速器。据Facebook说,加速器项目在14个参与该计划的都市报上吸引了成千上万的数字订阅和电子邮件订阅读者。

Lenfest Institute for Journalism官网
订阅经济成熟(The Subscription Economy Matures)
无论你是订阅、冲会员还是捐赠,我们都生活在受众经济时代。对于媒体公司(尤其是新闻媒体)而言,这意味着商业动机需要与消费者的需求保持一致。但是,风险在于订阅内容的传播会淹没观众的支付意愿(或能力)。如果发生这种情况,发布商将需要继续寻找新的收入来源。
订阅产品已经变得随处可见:Conde Nast在1月份宣布将在年底以前将其所有杂志网站(以前以广告收入为主)变成付费订阅。全国各地的报纸都在推出新的订阅产品或完善现有的服务。迪士尼正在迅速发展订阅视频服务,该服务将于11月在美国推出,涵盖了迪士尼、ESPN和Hulu的视频。
但即使目前普遍认为数字出版将是未来的发展出路,纸质订阅仍然对小型本地出版商有重要意义。阿肯色州《生活》杂志在1月份成功启动了纸质订阅活动后,又延续了一年的出版时间。该杂志计划削减出版,将更多业务转移到网上,但仍需要纸质订户获得收入。
线下连接(Offline Connections)
随着用户转向移动设备,开发者们也应当确保自家APP能够离线使用。Netflix、Youtube和Amazon Prime现在都在打造离线浏览功能,允许用户缓存视频,稍后观看。
新闻内容聚合应用,如Google、Smartnews和Apple,同样想要尽可能地利用用户时间,哪怕在wifi信号很弱的时候。《华盛顿邮报》的渐进式网络应用(Progressive Web App,可以理解为类似微信小程序,但它是基于Web浏览器运行)就将移动网页的加载时间从4秒缩短到了80毫秒,使用户在离线状态下也能阅读新闻。
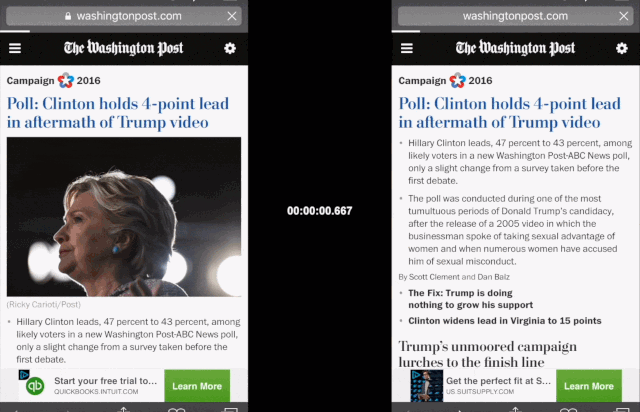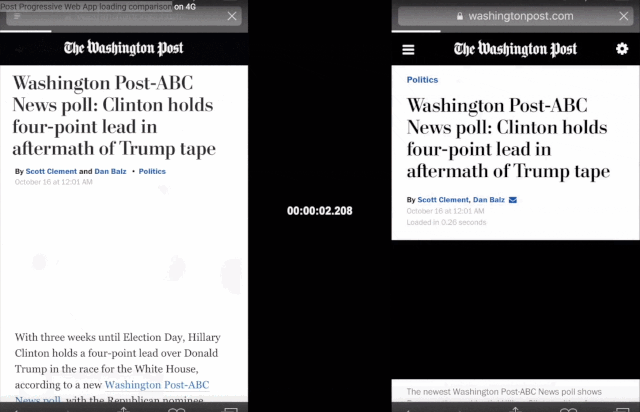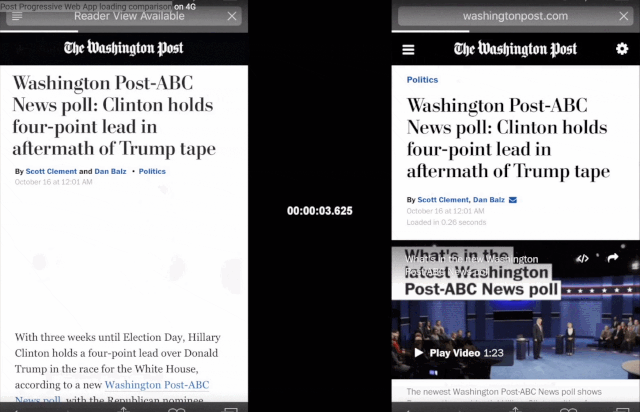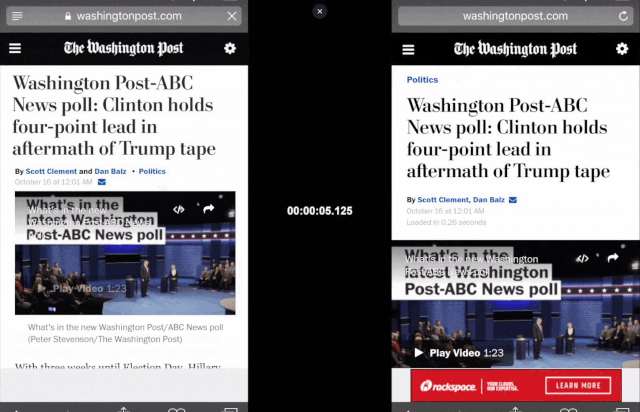
Progressive Web App比正常浏览器打开网页要快得多
作为服务的新闻业
(Journalism as a Service)
在传统新闻产品之外,新闻组织现在也在提供新闻服务。这种转向使得媒体能充分实现其内容价值。新闻服务主要面向从事知识领域工作的群体,包括大学、法律初创公司、数据科学公司、商业、医院甚至科技巨头等。媒体积累的内容实际上是能够被结构化、清洗,从而被多种组织运用的数据资源。
作为服务的新闻包含多个部分:新闻报道、API、编辑部和付费第三方均可使用的数据库;与新闻事件结合的日历插件;使用媒体组织积累的内容和数据库来自动生成报告的系统等。服务可以脱离社交媒体平台而提供,减少新闻组织对外的利润分成,使其提供的服务可以充分变现。
弹出式新闻编辑室与限量新闻产品(Pop-Up Newsrooms and Limited-Edition News Products)
新闻机构正在使用弹出式新闻编辑室和限量产品来吸引受众。集成协作的新闻编辑室可以专注于单个主题或项目,从而扩大影响范围并发现更深的故事。限量播客、新闻和活动可识别出对此感兴趣的读者并测试其新想法。
2019年3月,BuzzFeed在纽约发行了单日出版印刷品,在网上吸引了广泛的注意,这种限量产品可能是发展新受众的机会。
媒体整合(Media Consolidation)
在美国,数字用户日渐增加,传统媒体公司利润持续下降,基于广告的收入模式很难维持,尤其是对于本地媒体来说,形势更加艰难。美国联邦通信委员会(FCC)的去管制化政策也为大型媒体集团的收购合并与垂直整合铺平了道路。
2019年出现了一批巨额并购:迪士尼和福克斯在三月份完成了合并,其中包括转移了对Hulu的控制权;法院于2月份对AT&T收购Warner Media一案作出了最终批准,驳回了法官关于该交易是反竞争行为的观点。
基于聊天模式盈利的新闻业(Monetizing Chat-Based Journalism)
信息交流平台已经成为社交行为的新中心,这其中就包括信息分发和经济交易行为,且二者可以合二为一。这种渠道的中心化创造了到达读者的新机会,且读者拥有小额数字支付的功能。
腾讯微信是率先将小额支付系统纳入其信息交流平台的软件之一。以前的记者、电影评论家和行业专家等关键意见领袖现在可以通过微信公众号打赏获得收入。一些专栏作家每篇文章的收入最高为4,500美元。其他主要平台包括Facebook等也在增加相似功能。
微信公众号的赞赏功能
注意力指标的终结(The End of Attention Metrics)
衡量注意力经济的指标不再易于测量,流量造假屡禁不止。2018年11月,美国司法部起诉8人大规模广告欺诈,造假广告收入共计3600万美元。他们巧妙地使用漫游器来伪造点击行为甚至鼠标移动来模仿人类消费者。对于依赖广告收入的发行商和需要满足客户指标的广告商而言,这都是一个严重的问题。
web3.0
去中心化与合作加速了第三代互联网的发展。Web 1.0是互联网时代的开始,它引入了静态网页、电子商务和电子邮件。Web 2.0通过引入社交网络、共享经济、云计算和动态的自我维持内容存储库(如Wikipedia和Github)实现了分散式协作。分布式分类推动了大规模协作,并带来了Web 3.0。
在Web 3.0时代,合作和分散创作都能够加速发展的原因有二:基于数据挖掘、自然语言生成(NLP)和文本解析等技术,收集、挖掘与理解非结构化数据都变得更容易;通过AI和机器学习,机器能够直接彼此合作。最终,机器将能够互相训练。已经有类似的项目在进行中。
在媒体领域,Otoy通过创立一个合作者组成的去中心化分布式网络,共享空闲的处理资源,降低视觉设计效果的生产成本。另外,在Web3.0时代,媒体也能够建立微型支付系统,或者使用户能对自己的隐私和数据拥有更多的控制力。
媒介整合(Media Consolidation)
空间计算将来自真实世界的数据与个人数据、数字内容混合在一起。增强现实将数字内容投影叠加到真实环境中,利用空间计算导入环境并进行快速计算。数字形态的墙壁、地板和沙发就这样产生了,而且它们仍然遵循物理定律。Magic Leap是一家著名的空间计算公司,它的护目镜可以将真实环境变成可计算环境。在未来的10到15年中,Magic Leap希望发展城市规模大小的空间计算环境,让人们每天可以同时与真实世界和数字世界进行交互。
Magic Leap官网
数字复制品(Digital Twins)
数字复制品指的是在虚拟世界复制出一个真实世界存在的物品,并使其可以按照指令行动。视觉体积 (Volumetric Fields of Vision) 空间计算不像传统只捕捉2D维度,同时还捕捉深度、体积等多维数据。
动态光场(Dynamic Light fields)
光场可以测量在各个方向上流动的光。对于传统的计算机图形,一般可以通过拍摄高清照片或根据数据构建模型来生成光场。在空间计算中,光场必须是动态的。研究人员正在研究动态光场,该光场可以收集光数据,然后以模仿人类视线角度将数字对象投射出来。
云空间计算(Spatial Computing Clouds)
目前,空间计算系统仍然需要使用硬件。但是研究人员希望在云中构建更多功能。在云中的多个用户和设备之间存储环境数据、过往实验和其他程序将有助于发展空间计算系统。
智能电子产品包括智能手表、智能镜子、智能门铃等,可以在人们获取新闻和进行娱乐等方面发挥重要作用。截至目前,几乎所有可穿戴设备都需要智能手机或计算机来查看和报告数据、调整设置并存档信息。但这将随着智能手机逐渐淡出视野而改变。
智能摄像头新闻网络(Smart Camera News Networks)
亚马逊的Ring智能门铃系统包含一个名为Neighbors的软件,该软件使用户可以发布他们录制的视频,并鼓励他们发布社区内可疑活动、犯罪和其他问题的视频和照片。
截至2019年8月,美国各地共有225个警察部门可以向Ring Doorbell的用户索取视频录像。即便不是Ring的用户也可以免费下载该应用并查看发布的视频。该应用程序允许上传者剪辑并给视频注释,新闻媒体就可以用这些有关盗窃、火灾和其他事件的视频来补充新闻。但是该应用也会导致一些问题。例如种族歧视,故意给他人的照片贴错标签,报告“可疑”活动而没有任何真实证据。
Neighbors App
智能ER眼镜
(Smart ER Glasses)
2019年7月,Magic Leap从其独立创作者计划中挑选并发行了第一款包含世界上最知名的风景的3D拼图游戏。空间计算系统和ER眼镜可以将光线直接投射到用户的眼睛中,使数字对象看起来像存在于现实世界中。虽然Magic Leap的眼镜尚未面向大众出售,但其开发者平台和企业合作伙伴生态系统都在快速发展。
微软最近展示了一款令人印象深刻的实时应用程序。本来以英语演讲的女人被重新制作成逼真的全息图像,用日语表述了同样的演讲。
入耳式电子设备(Hearables / Earables)
入耳式电子设备充当了我们的私人助理,并在播放音乐的同事为我们实时翻译对话。Apple的第二代AirPods可以与Siri兼容,而三星的Galaxy Buds可以通过其Bixby助手提供语音帮助。
Jabra的Elite Sport耳塞可提供实时健身指导、心率感应和VO2 Max测试,并且兼具防汗和防水功能。Soul Electronics的Run Free Bio Pro耳塞可捕获大量跑步节奏、步态对称性和心率等数据。
智能手表、戒指和手镯(Smart Watches, Rings and Bracelets)
Motiv戒指是一种健身跟踪器,可以监视步数、心率和其他活动,也可以响应手势。用户可以对其进行编程,使其自动登录Amazon、Google和Facebook帐户,无需讲话即可控制Alexa。Oura戒指可以收集生物数据为使用者提供优化睡眠和注意力的建议。PayPal的戒指只需在NFC终端上挥手即可付款。
2018年12月,FCC批准了对雷达跟踪微动芯片的测试。Soli芯片等可以嵌入到眼镜、戒指、手镯中随时监控用户数据。
Motiv Ring 官网
神经技术(Neurotechnologies)
诸如Siri、Alexa和Google Assistant之类的语音接口正在变得越来越复杂,但是研究人员已经开始设想将人类和哺乳动物直接与计算机相连。人们可以通过这些人机界面用思想进行交流,为中风和瘫痪患者提供了新的选择。
明尼苏达大学和卡内基梅隆大学的生物医学科学家研究出了一种传感器界面,该界面允许患者使用头上的脑波传感器在屏幕上移动光标并控制机械臂。
数字成瘾(Digital Addiction)
对于数字产品而言,培养人们使用数字产品的习惯至关重要。越来越多的研究发现这些习惯可能会对心理健康产生负面影响。
人们通过33种关于人们阅读方式的研究发现,与屏幕阅读相比,从纸上阅读时阅读者表现更加高效。一些新产品旨在找到一种解决数字成瘾的技术解决方案,但目前如何长期缓解这种症状尚未明晰。
区块链(Blockchain Technologies)
一种在分布式分类账上储存和共享信息的新技术,上面所有的交易以及身份信息都受到保护。
加密货币(Cryptocurrencies)
区块链技术在2017年来到拐点。它除了从边缘化的数字货币发展到了比特币之外,还逐渐成为公众焦点,是一种共享和存储信息的新方式。尽管该技术仍在发展,但其广泛的应用可能会影响一系列行业。
Facebook在2019年夏季发布了Libra——一个由28个成员组织组成的财团支持使用的区块链数字货币,涵盖支付,电信,金融科技和风险投资行业等。目前为止区块链技术尚未进入主流,随着2020年技术成熟,区块链技术将受到持续关注。

Facebook发布了加密货币Libra
自我主权身份(Self-Sovereign Identity)
身份管理系统已经从政府颁发身份证逐渐发展到电子邮件账户和社交媒体帐户。每个人平均拥有27至130个在线帐户。像Google、Yahoo和Facebook这样的公司已经建立了代表用户管理大量数据的业务模型。但在2019年就发生了15起特大数据泄露事件,影响了政府、医疗保健、金融和技术领域的20亿个账户,涉及Facebook、CapitalOne、新加坡卫生部和保加利亚税务局等组织。
区块链和分布式分类账技术引入了新的身份管理方法:自我主权身份。自主权身份具有跨应用、设备和平台的互相操作性和可移植性。自主权身份具有两个主要优点:安全性和控制力。
对于媒体公司而言,自我主权身份将涉及付费、身份验证、版税以及数字广告等领域。
智能版权和自由职业者的收入(Tokens For Smart Royalties and Freelancers)
以太坊等区块链网络通过使用智能合约提供了跟踪内容所有权和许可的新方法。智能合约是一种自我执行的协议,协议的条款直接写入代码中。例如每次播放歌曲时,款项会自动从听众处扣除并流向艺术家们。使用区块链技术可以更好维护版权。
去中心化内容平台(centralized Content Platforms)
未来将会出现为创作者提供最大所有权和奖励的平台。在这个平台中,创作者将获得大部分收入,而不是将大部分收入提供给分发平台。同时,创作者还将保留更多的所有权并与观众进行直接互动。
区块链和分布式分类帐正在改变内容管理和消费方式的激励结构,用投票的方式支持内容以换取报酬。这将影响许多行业,从在线游戏到时尚到零售,从旅游业到汽车制造商,甚至包括2020年从事政治运动的行业。

区块链去中心化与版权保护
可溯源与永久存档(Content Provenance and Permanent Archiving)
区块链技术可以创建共享的永久性分类帐,其中任何内容都无法删除。因此,将原始内容或索引添加到区块链是记者永久保存其内容并且可进行追溯的一种方式。
娱乐、媒体和技术公司将在整个2020年继续面临新的安全和隐私挑战。现在比以往任何时候都更重要的是,每个组织都必须采取积极措施来保护用户和公司数据,定期执行渗透测试以识别漏洞,定期更新密码。每个组织都应该为最坏的情况做好危机计划。
窃听(Right To Eavesdrop/ Be Eavesdropped On)
随着越来越多的手机、移动设备、智能软件连接到物联网,这些设备之间以及与制造它们的公司之间的互动将不断扩展。我们的设备不再只是互相沟通,而是试图了解我们并谈论我们。
新闻和娱乐公司需要确定在交换消费者数据时,这些设备是否违反了道德准则。智能设备之间交流数据的时候我们无法确保它们是否在一定程度上超越道德底线、私自获取我们的信息。
智能语音助手被曝出“窃听”用户
加密消息网络(Encrypted Messaging Networks)
在过去的一年中,记者使用的是诸如Keybase和Signal之类的封闭式加密消息网络。但是,许多新闻机构仍然没有关于如何使用这些网络的准则。为了对有关全球范围内社交媒体黑客入侵和政府资助的监视程序做出回应,专用网络将在2020年继续流行。
网络霸凌者(Media Trolls)
指网络空间特有的垃圾邮件、仇恨言论、荡妇羞辱等行为。Twitter、Facebook和Instagram都更新了社区标准以限制仇恨言论。Reddit禁止r / Incels之类的团体违反该网站的社区标准(尽管在该网站的其余部分上仍有大量可怕的内容)。
真实性(Authenticity)
网络空间何为真实已经很难鉴定。Facebook已与Poynter Institute国际事实检查网合作,以打击其平台上的虚假新闻。但是,这种合作关系本身很难监控,也进一步说明了Facebook对数字媒体的主导影响力。媒体的真实性已从假新闻从扩展到假视频。Deepfake是一种计算机生成的面部互换视频,最早起源于Redditin,在关闭之前积累了超过80,000的订户。

Deepfake制作的假视频
信息主权(Data Ownership)
信息主权不只包括IP和版权,在智能设备风行的今天,还包括了个人行为、健康数据和网络活动等。比如上传到Facebook的照片和在YouTube上投稿的视频。
我们或许会感觉到技术更新迭代的速度放慢,但无可否认的是,我们正逐渐跨入一个以人工智能为主流的技术新时代。在这个新时代里,我们仍然面临着严峻的考验:验证新闻真伪仍然棘手,而各类造假应用却变得更加隐蔽了;在合成媒体的新世界中机器写作虽然解放了人力,却带来了更严重的算法规范问题;数字订阅失灵,受众流失困扰着所有传统媒体和新媒体。如何在这拥挤的市场里夺取受众有限的注意力将在未来几年里依然萦绕在每一个媒体人的心上。
然而,面对这不确定的未来,所有人都没有放弃。欧盟通过的《通用数据保护条例》得到了全世界的认可,各个国家也都在推进与网络和数据安全相关的立法规定;算法写作曾被认为会取代记者,如今则帮助媒体挖掘出更多更深的故事;区块链技术曾遭遇发展低谷,却依旧是保护媒体版权和可溯源永久保存数据的首要选择。
技术向前发展是无法逆转的趋势。然而无论这个世界如何变化莫测,利用技术改善人类生活的初心从未曾改变。
来自:2020年媒体技术趋势报告:13大领域、89项变革全输出
更多阅读:
