
我们是怎么选用交互方式的?
我们为什么要使用语音交互?我们为什么在开车时用语音导航?我们为什么喜欢调戏Siri?
为什么我们不用语音交互?为什么我们不用语音办公?
在这篇文章里,作者将简单为你介绍语音交互的利与弊~
一、语音交互怎么出现的?
交互方式是怎么出现的呢?原始的交互方式,是人和人用语言、动作、眼神交互,人与物用动作交互,比如说我们的祖先要用石头去砸开水果。
当机器出现后,我们开始研究如何更好地操作机器。从人机交互历史来看,刚开始的时候并没有人机交互的理念,机器非常难操作,是需要人来适应机器。比如说我们用的“QWERTY”键盘,之所以会流传开来是因为这种非人的设计可以降低打字速度,避免打字机的自杆键在快速输入时容易碰撞。
现在已经很少有这样的设计了,机器适应人类,提高人的效率的理念得到发展,我们喜欢的是自然和人性化的交互方式。在计算机领域,从命令行界面进入到图形用户界面是一大突破,图形界面的学习成本较低。随后发展到目前的主流操作方式触控,使用手指在屏幕上滑动点按。语音交互界面(Voice User Interface,VUI)、手势、动作、表情交互,甚至脑机接口,都属于自然用户界面(NUI),就更自然简单了。
人类最早的交互方式就是语言和动作,在自然交互方式的趋势下,我们走了一圈,又回到了语言交互了。
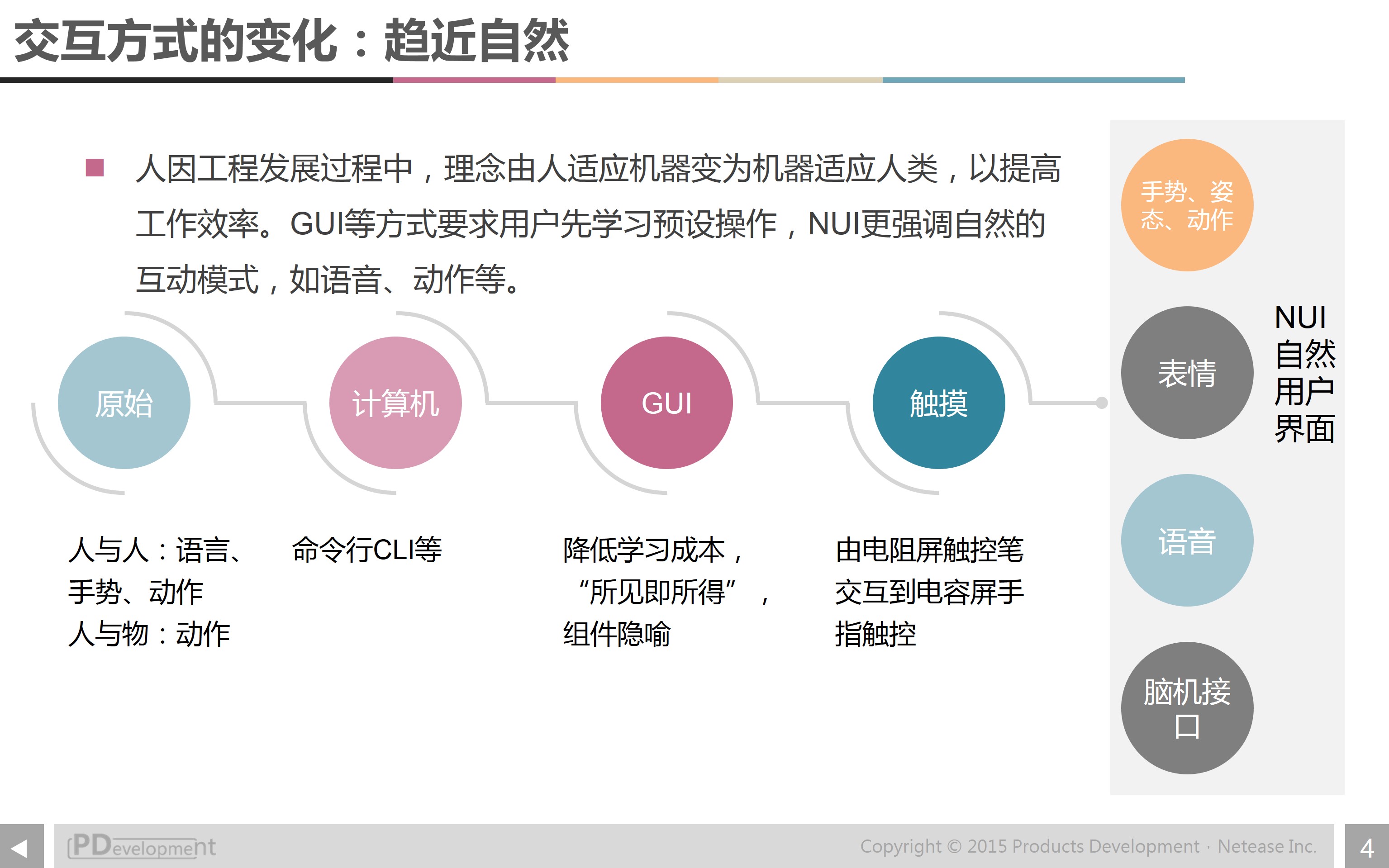
交互方式的变化
从载体上分,语音交互以手机或电脑为载体,或以其他硬件为载体。

语音交互的载体
问题一:GUI和VUI谁效率高?
什么是好的交互方式?
在笔者看来,高效的交互方式就是好的交互方式。任何交互方式,我看重的都是让我能够又快、又好、又不累地完成目标,提高我的使用表现。
我们把评价的维度拆解一下,从速度、准确性、注意负荷三个维度衡量语音交互,是否能让用户完成任务的速度更快、更准确,并且占用最少的注意负荷。
我们来看几种情况,比较一下GUI和VUI的效率。
输入文本:
语音交互的效率极高,因为人说话的速度比打字快,且用语音来输入文本的时候不需要分心看屏幕,比打字输入更省事,接近人和人聊天。
缺点是准确性,考虑到打字输入也有错误,语音交互在输入文本表现不错,因此很多产品都会在文本输入处加上语音入口。
布置任务:
如果我们想用手机叫个车回家,用Siri,还是用手指操控更快?语音交互理论上更快,唤醒Siri并说句话,就不需要打开APP再点选。
那为什么我们不用Siri打车呢?问题在于在现有状况下,语言是很模糊的,人可以听懂模糊语言,但机器的理解力很差,如果命令语言出现偏差,就会导致任务失败,语音助手听不懂你的意思。如果输出错误就更不用说了。怎么用Siri打车?说“我要打车回家?”还是“打开滴滴并打车回家?”还是“我要去某某小区”?如果语音助手三次都听不懂命令,我还会继续尝试吗?相比之下图形界面太精准友好了,我只要打开app,找到熟悉的入口点下单就可以了。
输出信息:
噩梦。
相比图形界面,语音是一种不太合格的输出方式。
天生的缺陷是语音不能输出视觉信息,Siri如何用她的声音告诉你一张图片是啥样的呢?而我们大部分的信息来自于视觉。
最重要的是,它过于缓慢和效率低下了。听一段话和读一段文字哪个比较快?语音客服系统就是这种浪费时间的方式。听觉是线性的,我们只能听完一句话再听下一句,不能像视觉一样瞬间完成图片加工,也不能像读文字那样可以跳过,看最重要的信息就好了。而且听语音会消耗大量注意和记忆资源,假想我们现在在打自动客服电话,没有听清,只能重听按0,这时候是非常让人崩溃的。
问题二:语音交互适合在哪里使用?
看情况,双手被占用的场合是非常合适的,比如驾驶、烹饪、玩游戏。一开始我们提出的问题是是,为啥我们开车要用语音导航?因为开车时眼睛需要看路,双手握着方向盘,但这是不妨碍说话和听声音的。很多人使用FM类产品是早上化妆、或者走路的时候,这个时候双手不方便,但是语音通道是打开的。
在输出层面上,语音输出适用于紧急和重要的通知。比如说突然着火了,是用大喇叭通知效果好,还是显示在屏幕上的效果好?我们用支付宝转账的反馈也是用语音播报的。
问题三:语音交互的好处都有啥?
语言是最自然的交互方式,人人都会说话,门槛极低,开口就能用,小孩子可以和音箱玩耍,尤其对于输出困难人群,例如视力障碍人群等。
另一方面,习惯没有那么容易改变,习惯触控的人群不一定就接受语音了,有些老人即使不能熟练操作手机,也不愿意尝试语音这种“新”技术。
问题四:为什么我不想和机器聊天?
因为怪怪的,不习惯。
据统计在公共场合使用Siri的只有3%。我们默认语言是人和人交流的方式,或是小猫小狗这种我们认为有人性的小动物,我会和小猫说话,但我不会对着微波炉说话,我们默认和物体是用动作来交互的。和手机说话的感觉挺奇怪的,因为手机不是人。在这一点上,东方人比较内敛,心理障碍可能更大。
恐怖谷理论认为,对于和人越来越像的东西,我们的好感会上升,但我们厌恶很像人而不是人的东西,例如僵尸。恐怖谷暗示着,有一天语音交互到达某个阶段后,我们可能会害怕语音助手。(百度图片里输入siri,会蹦出“Siri杀死人类照片”的联想搜索,人类是有多怕Siri)
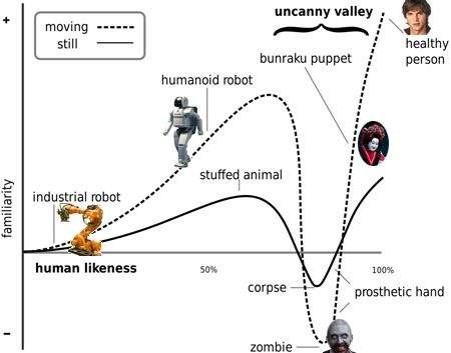
恐怖谷(来源:网络)
虽然和机器说话挺奇怪的,好处在于语音有声调和节奏,特别能传递感情。为了减少用户的压力,很多智能语音助手会给自己做个人设,例如Siri高冷又痴情,微软小冰可爱又贫嘴。我们能从他们的回应中感受到感情。
这也是为什么比起用Siri做点正事,我们更喜欢调戏她。告诉Siri,我不爱你了,乐于听到她说,“那我走了……我又回来了。没有你,我能去哪儿呢?”,并从中感受到爱的安慰。
还有一个有趣的议题,为什么语音助手都是女性声音?一种观点认为女性的声音听起来更加乐于助人,万一系统发生错误,如果是男性声音告知用户,出错了,用户可能会有被责备的感觉。
问题五:为什么没人在公共场合使用语音交互?
首先是为了安静……在图书馆和办公室怎么能发出声音呢?而且公共场合噪音大,声音容易听不到。
身份识别问题更加严重。设想在公开场合,有多台设备和一个用户,发出了命令,那么设备应该如何响应?如果有一台设备和多个用户,如何响应?
举个极端的例子,假如有一天,大家都用语音办公了!当我结束了一天的工作,我坚定地对着我的电脑说,“关机”,因为声音太大,一排的电脑都关机了,被波及到的同事毫不生气,立即对电脑说“开机”,于是我的电脑又开机了。
这一点早已有人发现,并且被做成了广告。汉堡王有一个得过奖的广告,前面都很正常,结尾的时候广告小哥凑近屏幕,说了句“Ok google. What’s the whoppers?”Ok google是安卓手机和Google Home的唤醒词,这句话前半部分是启动设备的,后半部分是一个搜索的问题。观看广告的人会发现自己啥都没干,自己的手机或者音箱就启动了,还自动搜索了皇堡,简直是手机被入侵了一样。视频广告结束了,但手机继续帮着播了广告。
这个漏洞被迅速修复了。这个案例揭示了语音交互系统的没有身份识别的风险。为此有的产品推出声纹识别系统,以保障支付安全问题,至于声纹验证的可靠性是另个问题。

汉堡王的视频广告(来源:网络)
还有隐私问题,在公共场合用语音交互是会被听到的,类似于打电话,而且是输入和输出都会被听到,敏感的金融、医疗和私人信息风险更大。如果是用图形交互界面,小心一点不要被偷看就比较安全了。(有个听来的故事是说,某个在线做题app用语音消息做反馈,某个学生在上课时,在app上发了一个单,手机立即发出声音,“恭喜你,王同学!你求助的题目已经有老师接单啦,快来查看吧!”,这个app就卒了)
语音交互至少需要满足噪音低和私密两条要求,如果加上前文提到的“双手被占用”那就更加符合了。在众多的场景中,车内和家里是满足要求的,加上手机上的移动场景,共3大场景。Mary Meeker在2016年的报告中指出,美国语音使用的主要场景是家里(43%),车上(30%),路上(19%),工作仅占3%
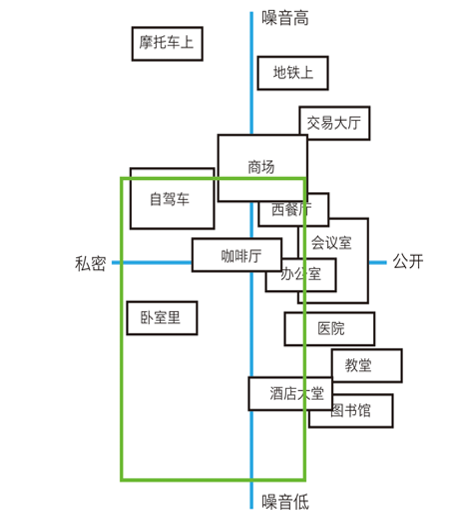
语音交互的场景(来源:网络)
三、语音交互发展遇到的问题都有啥?
语音交互系统发展的历史并不短,早在1952年,贝尔实验室就开发了能够识别阿拉伯数字的系统Audrey。IBM在1962年发明了第一台可以用语音进行简单数学计算的机器Shoebox。

IBM的Shoebox系统(来源:IBM)
在发展了半多个世纪后,语音交互仍不能说是成熟应用,遇到的困难贯穿开发到使用流程。
一套完整的语音交互系统有典型的三个模块,语音识别(Automatic Speech Recognition,ASR)将声音转化成文字,第二步经过自然语言处理(Natural Language Processing,NLP),将文字的含义解读出来,处理并给出反馈,最后是语音合成(Text to Speech,TTS),将输出信息转化成声音。
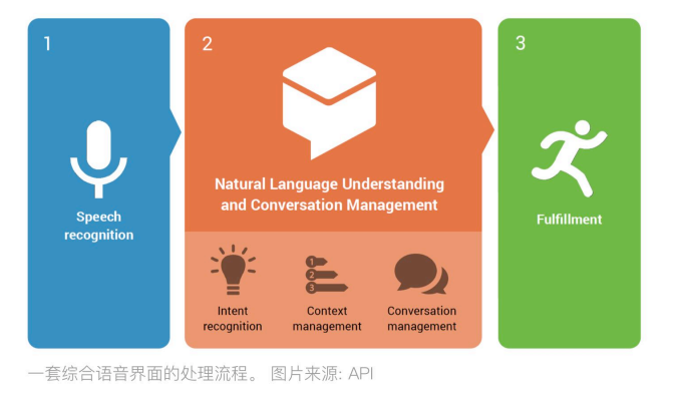
典型的语音交互系统模块(来源:网络)
问题一:远场识别好难
第一个问题是语音收集层面的。语音质量高,语音识别结果才好。
常听到某公司宣称自己的语音识别率达到了95%甚至99%,他们没说测试的环境是声源距离很近、环境特别安静、说话人的普通话特别标准的情况,到了真实使用情况就呵呵了。
语音识别根据距离分两种情况,近场识别和远场识别,二者不一样,后者难度更大。
手机上的语音交互是典型的近场,距离声源近,语音信号的质量较高。另一方面,采集语音的交互相对简单,有触摸屏辅助,用户通过点击开始和结束进行信号采集,保证可以录到用户说的话。
远场语音交互以智能音箱为代表,声源远,不知道声源具体位置,环境中存在噪声、混响和反射。单麦克风无法满足要求,需要麦克风阵列支持。用户可能站在任意方位,被语音唤醒后,需要定位到声源位置,向该方向定向拾音,增强语音并降低其他区域和环境的噪声。
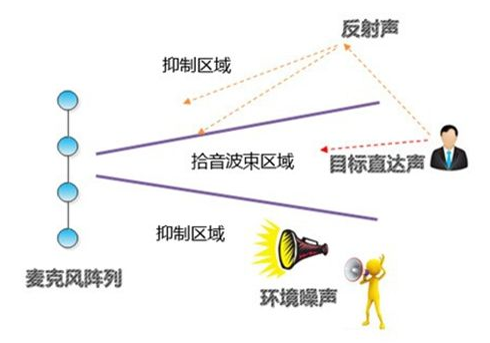
远场识别示意图(来源:雷锋网)
问题二:语音识别正确率
实际工作中,常用的指标是识别词错误率(Word Error Rate),过去四十年里语音识别已取得了很大进展。微软语音和对话研究团队负责人黄学东最近宣布微软语音识别系统错误率由5.9%进一步降低到5.1%,可与专业速记员比肩。进步来自于两方面,一是技术,包括隐马尔可夫模型、机器学习和各种信号处理方法,另一方面是庞大的计算资源和训练数据,由于互联网存在,现在可以获得大量日常语音,包含各种材料和环境。
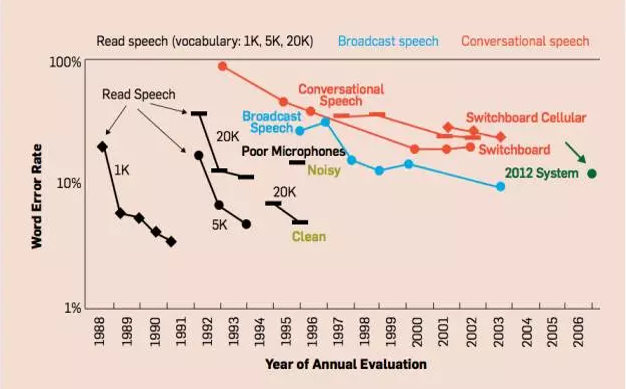
任务难度增加情况下,错误率不断下降(来源:机器之心)
问题三:语义识别好难

中文房间(来源:hku)
从这个实验看,这本小册子就是计算机程序,房间就是计算机。计算机给出的回答是按照程序的指示进行的,它不可能理解中文。现在很多语义理解是固定模式识别,可以理解的最简单的小册子,根据用户话中特定的词做出特定的反应。训练机器来理解语义就类似于这个过程。通过训练我们让机器的反应接近于能够理解,但如何期待机器能理解?
来说说具体的问题。语义理解的问题至少有分词、歧义和未知语言处理问题等。中文不像英文单词有空格分开的,要分词。而且歧义性高,例如“佟大为妻子生下一女“是什么意思?你和Siri说“打开饱了么外卖”,而他没有学过“饱了么”这个单词,它如何处理?
问题四:用多轮对话为难机器
人类对话看似简单,我们一和机器对话就会发现不自然。人类的对话其实很巧妙,对话内容会根据背景信息调整,对话时会预设对方知道哪些事情。而且我们有多轮对话,上下文之间有呼应关系,对话可能很散,但是人有话题的概念。
比如这个简单的对话
“明天下雨吗?“
”不下“
”后天呢?“
”也没有”
我们觉得语音助手很蠢,有时是因为违反了人对话的原则。很多产品对话缺少关联性,不理解背景,只能进行单轮对话,看似能多轮对话,实际是多个单轮对话。“愚蠢”带来的一是不自然,二是给语音交互增加任务难度,相当于我们要用另一套“机器语言”和机器对话。
比如
我问语音助手,“明天的天气是什么?”
“明天是雨天“
“后天呢?”
“我不明白你的意思”
它不明白后天指的是后天的天气,我只能再完整地问一次“后天的天气是什么?”
在下面这个对话里,小冰一会说阴阳师是游戏,一会是电影,并没有对话的记忆。
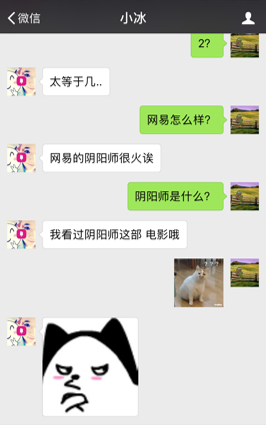
小冰没有记忆
问题五:语音交互设计怎么做
由于语言尤其是口语的形式不固定,变化很大。VUI的交互设计和GUI截然不同,更加细致繁琐。笔者对此了解不多,有兴趣可以参考更多资料。比如亚马逊已经给开发者提供了成熟的交互设计规范。
语音交互设计至少可分为几步,现在的交互设计基本都是以功能的形式来建立的。设计的第一步是建立功能目的,想好功能目的。然后是撰写脚本,也就是用户和系统是如何对话的。第三步是制定流程,用户使用路径。还需要定义技能的结构,包括完成一个功能需要哪些参数,例如要完成打车功能,需要时间、起点、目的地等参数,以及用语有哪些变化,对于同一个功能,用户可以说“天气怎么样?”也可以问“外面下雨吗?”。
问题六:远场语音交互产品的冷启动周期
远场语音交互产品,比如音箱,是很不好做的,有一个冷启动周期。如果用户多,数据就多,就可以用于打磨技术和提升产品体验,带来更好的商业销售效果,然后进一步促进产品发展。反过来产品没销量也就没有数据,体验更加不好。
另一方面,如果想让语音交互硬件成为平台,千万量级是个基本门槛。比如Echo在今年的销量可以达到预计的两千万台,基本上有了足够数据,同时有希望成为平台。国内一些模仿者也在使用这种节日促销的模式,例如双十一天猫精灵99元的售价,卖了300万台,用简单粗暴的方式直接启动起来。
问题七:缺乏持续使用动力和核心场景
新鲜劲过去后,很多人都会对语音交互失去新的兴趣,触控仍然是主要的交互方式。Creative Strategies的数据发现,97%的人在两周的时间内,就会对Alexa的新功能失去兴趣。Voice Lab的数据发现,62%的安卓用户很少或者偶尔使用语音助手,这一比例在iOS用户上是70%。而目前语音交互缺乏只有其才能实现的核心功能,例如Echo最多的用途仍然是听听歌。
四、问题讨论
1 语音交互是否会成为主流交互方式?
这个问题争论得很厉害。
笔者的意见是,没有必要去争论什么会是主流的交互方式,交互界面本来就是多模态的,语音交互将丰富现有的交互形式。就像触控没有取代鼠标键盘,语音交互不太可能成为主流的交互方式。
一切取决于具体情况,如前文所述,语音交互不能解决所有问题,但是在特定的场景可以发挥效率。伴随语音的多交互通道已经被证明是不错的选择,例如语音和触控结合可以提高准确度,语音输入+视觉反馈更加直观等等。
2 是否需要追求语音交互的纯洁性?
Echo团队认为,语音是最自然的交互方式,因此坚持设计语音交互。但语音输入和视觉输出的模型已被证明很成功,我们在手机上使用的语音交互模型就是如此。新品Echo Show也装上了屏幕,可以显示视觉信息了。所以是否有必要坚持纯粹的语音交互模型?答案似乎已经很明显。
新问题是,如果Echo加上了屏幕,它是音箱还是平板?

加上屏幕的Echo Show(来源:网络)

天猫精灵:用手机伪装屏幕(来源:天猫精灵)
3 语音交互的定位
本质上,语音交互允许人通过语音的方式完成任务,能通过语音完成的,触控也可以,Siri可以做到的,Echo也可以做到,做不到的大家都做不到。
所以语音交互能够完成什么独有的任务以体现它的价值呢?
4 VUI vs CUI
语音设计师Cheryl Platz反复提及一个问题,我们要VUI还是Conversational UI?
语音交互的模式是简单的“下命令——完成任务”,看起来是对话,然而距离真正自然的对话还远着呢。我们和机器人没有真正的对话,我们只是对他下命令,说句话之前还要想想如何下命令。
如果我们的目标是CUI,那还必须更加智能和流畅,允许我们通过真正的对话完成任务,像和真人说话一样。
5 隐私问题
如果语音助手要好用更智能,就需要不断收集用户信息。所以我们是否要小心对语音助手说的话,免得透露太多隐私?
如果语音助手目的就是商业的,我们要不要让他更了解我的喜好?(他知道你喜欢什么,就会给你推送更多。类似于手机上的搜索记录)
语音交互仍需要发展,技术成熟需要时间。但它的出现意味着,我们离理想的交互界面更近了一步。本文对语音交互做了简单的总结,有疏漏和想法不成熟之处,欢迎交流指正。
参考资料:
1. Cathy Pearl. Designing Voice User Interfaces. O’Reilly Media, 2016
2. Clifford Nass, Scott Brave . Wired for Speech. MIT Press
3. Cheryl Platz. The Narrowing Rift: Voice UI and Conversational UI. Medium: Microsoft Design
4. Amazon Alexa:Voice Design Guideline. Amazon
5. 极限元,一文读懂智能语音前端处理中的关键问题,雷锋网
作者介绍
汪梅子,产品发展部,目前对接网易智能硬件的用户研究工作。喜欢有趣的、自己不知道的事情,在用户研究的路上继续成长着。
更多阅读:
