
“也许我们今天最重要的消息是,数据集-而不是算法-可能是关键限制因素,以人类水平的人工智能的发展,”据亚历山大Wissner-格罗斯在一份书面回应提出的问题边:“你认为什么是最有趣的最新科学消息?“
在人工智能的dield的曙光,它的两个创始人著名的预测,解决机器视觉的问题,将只需要一个夏天。我们现在知道,他们是关闭的半个世纪。Wissner-毛开始思考的问题:“是什么把人工智能革命做久”通过审查的最公开AI的时间在过去30年的进步,他发现的证据表明一个挑衅的解释:也许很多重大的AI突破实际上已经通过高质量的培训数据集的可用性的限制,而不是算法的进步。在这里,我们总结的关键AI里程碑:
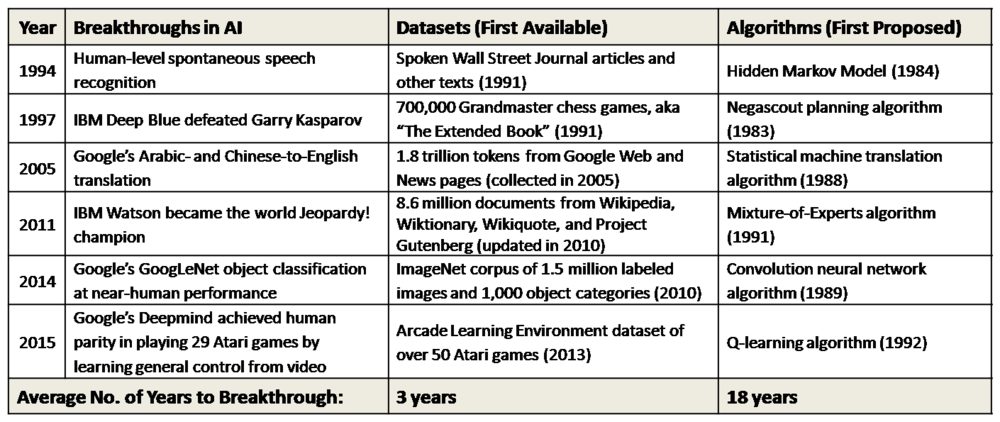
密钥算法的建议和相应的进步之间的平均时间约为18年,而关键数据可用性和相应的进步之间的平均时间不到3年,或约6倍的速度。
如果属实,这个假设对人工智能未来的进展基础性意义。例如,优先考虑高品质的训练数据集的种植可能允许订单数量级的增速在AI突破了纯算法的进步。毕竟,专注于数据,而不是算法是一种潜在的简单的方法。“尽管新的算法得到太多的公共信用于截至最后AI冬天,得出结论:”亚历山大Wissner-格罗斯,“真正的新闻可能是优先的培养他们周围的新数据集和研究团体可能会延长目前AI夏天必不可少的。“
我们想知道的算法交易系统同样可能从栽培新数据集和身边的研究团体。受益可能看起来像什么? 我们如何学会用完美的数据?什么是信任的数据太多的风险?
参考文献:
- Wissner-毛,亚历山大(2016年)。数据集在算法。边缘。:取自https://www.edge.org/response-detail/26587
- 克莱恩,加里(2016年)。通过数据蒙蔽边缘。:取自https://www.edge.org/response-detail/26692
更多阅读:
