

到现在你可能听说过种种奇闻轶事,比如机器学习算法通过利用大数据能够预测某位慈善家是否会捐款给基金会啦,预测一个在新生儿重症病房的婴儿是否会罹患败血症啦,或者预测一位消费者是否会点击一个广告啦,等等。甚至于,机器学习算法还能驾驶汽车,以及预测大选结果!… 呃,等等。它真的能吗?我相信它肯定可以,但是,这些高调的论断应该在数据工作者(无论这些数据是否是『大』数据)以及机器学习工作者心里留下些非常困难的问题:我能否理解我的数据?我能否理解机器学习算法给予我的模型和结果?以及,我是否信任这些结果?不幸的是,模型的高复杂度赐予了机器学习算法无与伦比的预测能力,然而也让算法结果难以理解,甚至还可能难以采信。
尽管,我们可能能够强制自变量-因变量关系函数是满足单调性约束的(译者注:单调性的意思是,递增地改变自变量,只会导致因变量要么一直递增,要么一直递减),机器学习算法一直有倾向产生非线性、非单调、非多项式形式、甚至非连续的函数,来拟合数据集中自变量和因变量之间的关系。(这种关系也可以描述为,基于自变量的不同取值,因变量条件分布的变化)。这些函数可以根据新的数据点,对因变量进行预测——比如某位慈善家是否会捐款给基金会,一个在新生儿重症病房的婴儿是否会罹患败血症,一位消费者是否会点击一个广告,诸如此类。相反地,传统线性模型倾向于给出线性、单调、连续的函数用于估计这些关系。尽管它们不总是最准确的预测模型,线性模型的优雅、简单使得他们预测的结果易于解释。
如果说,好的(数据)科学对能够理解、信任模型以及结果是一个一般性要求的话,那么在诸如银行、保险以及其他受监管的垂直行业中,模型的可解释性则是重要的法律规范。商业分析师、医生以及行业研究员必须理解以及信任他们自己的模型,以及模型给出的结果。基于这个原因,线性模型几十年来都是应用预测模型中最易于上手的工具,哪怕是放弃几个百分点的精度。今天,大量机构和个人开始在预测模型任务中拥抱机器学习算法,但是『不易解释』仍然给机器学习算法的广泛应用带来了一些阻碍。
在这篇文章中,为了进行数据可视化和机器学习模型/结果解释,我在最常用的一些准确性度量、评估图表以外,提供了额外的几种方法。我诚挚建议用户根据自己的需要,对这些技巧进行一些混搭。只要有可能,在这篇文章中出现的每一个技巧里,『可解释性』都被解构为几个更基本的方面:模型复杂程度,特征尺度,理解,信任 —— 接下来我首先就来简单对这几点做个介绍。
待解释的响应函数(译者注:因变量关于自变量的函数)的复杂程度
线性单调函数:由线性回归算法创建的函数可能是最容易解释的一类模型了。这些模型被称为『线性的、单调的』,这意味着任何给定的自变量的变化(有时也可能是自变量的组合,或者自变量的函数的变化),因变量都会以常数速率向同一个方向变动,变动的强度可以根据已知的系数表达出来。单调性也使得关于预测的直觉性推理甚至是自动化推理成为可能。举例来说,如果一个贷款的借方拒绝了你的信用卡申请,他们能够告诉你,根据他们的『贷款违约概率模型』推断,你的信用分数、账户余额以及信用历史与你对信用卡账单的还款能力呈现单调相关。当这些解释条文被自动化生成的时候,它们往往被称作『原因代码』。当然,线性单调的响应函数也能够提供变量重要性指标的计算。线性单调函数在机器学习的可解释性中有几种应用,在更下面的第一部分和第二部分讨论中,我们讨论了利用线性、单调函数让机器学习变得更为可解释的很多种办法。
非线性单调函数:尽管大部分机器学习学到的响应函数都是非线性的,其中的一部分可以被约束为:对于任意给定的自变量,都能呈现单调性关系。我们无法给出一个单一的系数来表征某个特定自变量的改变对响应函数带来的影响程度,不过非线性单调函数实际上能够做到『只朝着一个方向前进』(译者注:前进的速度有快有慢)。一般来说,非线性单调的响应函数允许同时生成『原因代码』以及自变量的『相对重要性指标』。非线性单调的响应函数在监管类的应用中,是具备高度可解释性的。
(当然,机器学习能够凭借多元自适应回归样条方法,建立『线性非单调』的响应曲线。在此我们不强调这些函数的原因,是因为一方面,它们的预测精度低于非线性非单调的预测模型,另一方面,它们跟线性单调的模型比起来又缺乏解释性。)
非线性非单调函数:大部分机器学习算法建立了非线性、非单调的响应函数。给定任意一个自变量,响应函数可能以任何速率、向任何方向发生变动,因此这类函数最难以解释。一般来说,唯一可以标准化的解释性指标就是变量的『相对重要性指标』。你可能需要组织一些本文将要展示的技术作为额外手段,来解释这些极端复杂的模型。
可解释性的特征尺度
全局可解释性:某些下文展示的技巧,无论是对机器学习算法,算法得到的预测结果,还是算法学习到的自变量-因变量关系而言,都能够提供全局的可解释性(比如条件概率模型)。全局可解释性可以根据训练出来的响应函数,帮助我们理解所有的条件分布,不过全局可解释性一般都是『近似』的或者是『基于平均值』的。
局部可解释性:局部可解释性提高了对于小区域内条件分布的理解,比如输入值的聚类,聚类类别对应的预测值和分位点,以及聚类类别对应的输入值记录。因为小局部内的条件分布更有可能是线性的、单调的,或者数据分布形式较好,因此局部可解释性要比全局可解释性更准确。
理解与信任
机器学习算法以及他们在训练过程中得到的响应函数错综复杂,缺少透明度。想要使用这些模型的人,具有最基本的情感需求:理解它们,信任它们——因为我们要依赖它们帮忙做出重要决策。对于某些用户来说,在教科书、论文中的技术性描述,已经为完全理解这些机器学习模型提供了足够的洞见。对他们而言,交叉验证、错误率指标以及评估图表已经提供了足以采信一个模型的信息。不幸的是,对于很多应用实践者来说,这些常见的定义与评估,并不足以提供对机器学习模型与结论的全然理解和信任。在此,我们提到的技巧在标准化实践的基础上更进一步,以产生更大的理解和信任感。这些技巧要么提高了对算法原理,以及响应函数的洞察,要么对模型产生的结果给出了更详尽的信息。 对于机器学习算法,算法学习到的响应函数,以及模型预测值的稳定性/相关性,使用以下的技巧可以让用户通过观测它们、确认它们来增强使用它们的信心。
这些技巧被组织成为三部分:第一部分涵盖了在训练和解释机器学习算法中,观察和理解数据的方法;第二部分介绍了在模型可解释性极端重要的场合下,整合线性模型和机器学习模型的技巧;第三部分描述了一些理解和验证那些极端复杂的预测模型的方法。
第一部分:观察你的数据
大部分真实的数据集都难以观察,因为它们有很多列变量,以及很多行数据。就像大多数的『视觉型』人类一样,在理解信息这方面我大量依赖我的『视觉』感觉。对于我来说,查看数据基本等价于了解数据。然而,我基本上只能理解视觉上的二维或者三维数据——最好是二维。此外,在人类看到不同页面、屏幕上的信息时,一种被称作『变化盲视』的效应往往会干扰人类做出正确的推理分析。因此,如果一份数据集有大于两三个变量,或者超过一页/一屏幕数据行时,如果没有更先进的技巧而是只漫无止境的翻页的话,我们确实难以知道数据中发生了什么。
当然,我们有大量的方法对数据集进行可视化。接下来的强调的大部分技巧,是用于在二维空间中描述所有的数据,不仅仅是数据集中的一两列(也就是仅同时描述一两个变量)。这在机器学习中很重要,因为大部分机器学习算法自动提取变量之间的高阶交互作用(意味着超过两三种变量在一起形成的效果)。传统单变量和双变量图表依然很重要,你还是需要使用它们,但他们往往和传统线性模型的语境更相关;当众多变量之间存在任意高阶交互作用时,仅靠使用传统图表就想理解这类非线性模型,帮助就不大了。
图形符号

图1. 使用图形符号代表操作系统和网页浏览器类型。感谢Ivy Wang和H2O.ai团队友情提供图片
图形符号(Glyph)是一种用来表征数据的视觉符号。图形符号的颜色、材质以及排列形式,可以用来表达数据不同属性(译者注:即变量)的值。在图1中,彩色的圆圈被定义为表达不同种类的操作系统以及网络浏览器。使用特定方式对图形符号进行排列后,它们就可以表征数据集中的一行行数据了。
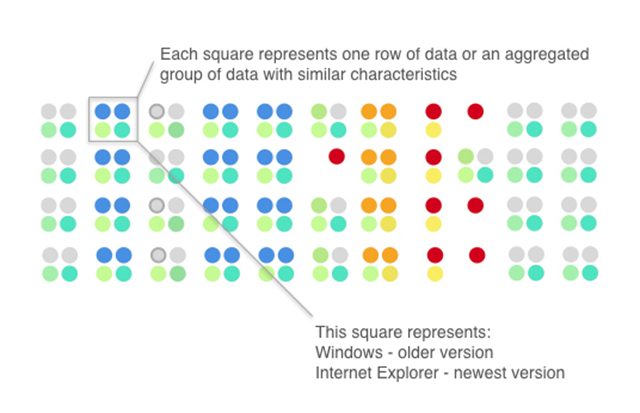
图2. 将图形符号进行组织,表达数据集中的多行。感谢Ivy Wang以及H2O.ai团队友情提供图片
关于如何使用图形符号表示一行行数据,图2在这里给出了一个例子。每4个符号形成的小组既可以表示特定数据集中的某一行数据,也可以表示其中的很多行的汇总数据。图形中被突出的『Windows+IE浏览器』这种组合在数据集中十分常见(用蓝色,茶叶色,以及绿色表示),同理『OS X+Safari浏览器』这种组合也不少(上面是两个灰色点)。在数据集中,这两种组合分别构成了两大类数据。同时我们可以观察到,一般来说,操作系统版本有比浏览器版本更旧的倾向,以及,使用Windows的用户更倾向用新版的操作系统,使用Safari的用户更倾向于用新版的浏览器,而Linux用户以及网络爬虫机器人则倾向于使用旧版的操作系统和旧版的浏览器。代表机器人的红点在视觉上很有冲击力(除非您是红绿色盲)。为那些数据离群点(Outlier)选择鲜明的颜色和独特的排列,在图形符号表达法中,是标注重要数据或异常数据值的好办法。
相关图
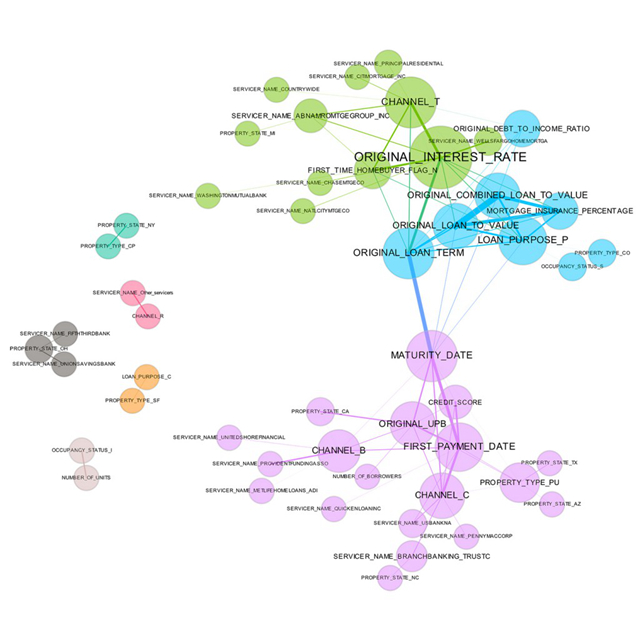
图3. 来自一家大型金融公司,用于表征贷款业务的相关图。感谢Patrick Hall和H2O.ai团队友情提供图形
相关图是体现数据集中数据关系(相关性)的二维表达方法。尽管在图3中,过多的细节实际上是可有可无的,这张图还有一定改进空间,然而就相关图本身而言,这一方法仍然是观察、理解各变量相关性的有力工具。利用这种技巧,哪怕是上千个变量的数据集,也能画在一张二维图形上。
在图3中,图的结点(node)表示某个贷款数据集中的变量,图中的连边(edge)的权重,也就是线条的粗细,是由两两之间皮尔逊相关系数的绝对值来定义的。为了简单起见,低于特定某个阈值的绝对值没有画出来。结点的大小,由结点向外连接的数目(即结点的度,degree)决定。结点的颜色是图的社群聚类算法给出的。结点所在的位置是通过力导向图生成的。相关图使我们能够观察到相关变量形成的大组,识别出孤立的非相关变量,发现或者确认重要的相关性信息以引入机器学习模型。以上这一切,二维图形足以搞定。
在如图3所展示的数据集中,若要建立以其中某个变量为目标的有监督模型,我们希望使用变量选择的技巧,从浅绿、蓝色、紫色的大组里挑选一到两个变量出来;我们能够预计到,跟目标变量连线较粗的变量在模型中会较为重要,以及『CHANNEL_R』这种无连线的变量在模型中重要性较低。在图3中也体现出了一些常识性的重要关系,比如『FIRST_TIME_HOMEBUYER_FLAG_N』(是否为首次购房者)以及『ORIGINAL_INTEREST_RATE』(原始基准利率),这种关系应该在一个可靠的模型中有所体现。
2D投影

图4. 基于著名的784维的MNIST手写数据集制作的二维投影图。左图使用了主成分分析,右图使用了堆叠式消噪自编码机。感谢Patrick Hall和H2O.ai团队友情提供图片
把来自数据集中原始高维空间的行向量映射到更容易观察的低维空间(理想情况是2到3维),此类方法可谓多种多样。流行的技巧包括:
- 主成分分析(Principal Component Analysis,PCA)
- 多维缩放(Multidimensional Scaling,MDS)
- t分布随机近邻嵌入(t-distributed Stochastic Neighbor Embedding,t-SNE)
- 自编码机神经网络(Autoencoder Networks)
每一种方法都有它的优点和弱势,但他们有一个共同的主旨,就是把数据的行转化到有意义的低维空间上。这些数据集包括图像、文本,甚至商业数据,它们往往具有很多难以画在一张图上的变量。但这些通过找到把高维数据有效映射到低维表达的投影方法,让古老而可靠的散点图迎来了第二春。一个散点图所体现的高质量映射,应该反映出数据集中各方面的重要结构,比如数据点形成的聚类,层次结构,稀疏性,以及离群点等。
在图4中,著名的MNIST数据集(数字的手写数据集)被两种算法从原始的784维映射到了2维上:一种是主成分分析,另一种是自编码机神经网络。糙快猛的主成分分析能够把标注为0和1的这两类数据区分的很好,这两种数字对应的手写图像被投影在两类较为密集的点簇中,但是其他数字对应的类普遍地发生了覆盖。在更精巧(然而计算上也更费时)的自编码机映射中,每个类自成一簇,同时长的像的数字在降维后的二维空间上也比较接近。这种自编码机投影抓住了预期中的聚簇结构以及聚簇之间的相对远近关系。有意思的是,这两张图都能识别出一些离群点。
投影法在用于复查机器学习建模结果时,能提供一定程度上的额外『可信性』。比如说,如果在2维投影中能够观测到训练集/验证集里存在类别、层级信息和聚簇形态的信息,我们也许可以确认一个机器学习算法是否正确的把它们识别出来。其次,相似的点会投影到相近的位置,不相似的点会投影到较远的位置,这些都是可以加以确认的。我们考察一下用于做市场细分的分类或者聚类的模型:我们预计机器学习模型会把老年有钱客户和年轻且不那么富裕的客户放在不同的组里,并且它们在经过映射后,分别属于完全分离的两大组稠密的点簇。哪怕训练集、验证集中存在一些扰动,这种结果也应该是稳定的,而且对有扰动/无扰动两组样本分别进行映射,可以考察模型的稳定性,或者考察模型是否表现出潜在的随时间变化的模式。
偏相关图
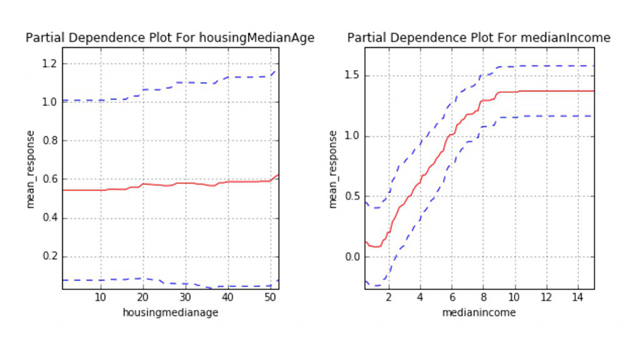
图5. 在著名的加州房产数据集上建立GBDT集成模型后得到的一维偏相关图。感谢Patrick Hall和H2O.ai团队友情提供图片
当我们只关心一两个自变量取值发生变化,而其他自变量都处于平均水准对机器学习模型响应函数所造成的影响时,偏相关图可以为我们展现这种关系。在我们感兴趣的自变量存在较为复杂的交互作用时,用双自变量偏相关图进行可视化显得尤为有效。当存在单调性约束时,偏相关图可以用于确认响应函数对于自变量的单调性;在极端复杂的模型里,它也可以用于观察非线性性、非单调性、二阶交叉效应。如果它显示的二元变量关系与领域知识相符,或者它随时间迁移呈现出可预计的变化模式或者稳定性,或者它对输入数据的轻微扰动呈现不敏感,此时我们对模型的信心都会有所提高。
偏相关图对于数据集的不同数据行而言,是全局性的;但对数据的不同列,也就是不同自变量而言,是局部性的。仅当我们需要考察1-2个自变量和因变量的关系时我们才能使用这种图。一种较新,不太为人所知的偏相关图的改进版本,称为『个体条件期望图』(Individual conditional expectation,ICE),它使用类似偏相关图的思想,能够给出对数据更局部性的解释。在多个自变量存在较强的相关关系时,ICE图显得尤其好用。
残差分析
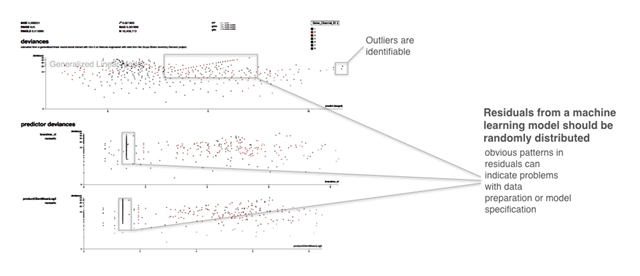
图6. 一个来自残差分析应用的截图。感谢Micah Stubbs和H2O.ai团队友情提供的截图
『残差』,是指数据集每一行中,因变量的测量值和预测值之差。一般来说,在拟合得不错的模型中,残差应该呈现出随机分布,因为一个好的模型,会描述数据集中除了随机误差以外的绝大部分重要现象。绘制『残差-预测值』这种评估手段,是一种用二维图形检查模型结果的好办法,饱经时间考验。如果在残差图中观测到了很强的相关性模式,这不啻为一种死亡讯息:要么你的数据有问题,要么你的模型有问题——要么两者都有问题!反之,如果模型产生了随机分布的残差,那这就是一种强烈的信号:你的模型拟合较好,可靠,可信;如果其他拟合指标的值也合理(比如,R^2,AUC等指标),那就更加如此了。
在图6中,方框指出了残差中具有很强线性模式的部分。这里不仅有传统的『预测值-残差图』,也有特定自变量跟残差形成的二维散点图。把残差跟不同自变量画在一起,可以提供更细粒度的信息,以便于推理出到底什么原因导致了非随机模式的产生。残差图对识别离群点也有帮助,图6就指出了离群点。很多机器学习算法都使徒最小化误差平方和,这些高残差的点对大部分模型都会带来较强的影响,通过人工分析判断这些离群点的真实性可以较大的提高模型精度。
现在我们已经展现了几种数据可视化的技巧,我们通过提几个简单问题,来回顾以下几个大概念:尺度,复杂性,对数据的理解,以及模型的可信性。我们也会对后面的章节中出现的技术提出相同的问题。
数据可视化提供的可解释性,是局部性的还是全局性的?
都有。大部分数据可视化技术,要么用于对整个数据集进行粗糙的观测,要么用于对局部数据提供细粒度检查。理想情况家,高级可视化工具箱能够让用户容易地缩放图形或者向下钻取数据。如若不然,用户还可以自己用不同尺度对数据集的多个局部进行可视化。
数据可视化能够帮助我们理解什么复杂级别的响应函数?
数据可视化可以帮我们解释各种复杂程度的函数。
数据可视化如何帮我们提高对数据的理解?
对大部分人而言,数据结构(聚簇,层级结构,稀疏性,离群点)以及数据关系(相关性)的可视化表达比单纯浏览一行行数据并观察变量的取值要容易理解。
数据可视化如何提高模型的可信程度?
对数据集中呈现的结构和相关性进行观察,会让它们易于理解。一个准确的机器学习模型给出的预测,应当能够反映出数据集中所体现的结构和相关性。要明确一个模型给出的预测是否可信,对这些结构和相关性进行理解是首当其冲的。
在特定情况下,数据可视化能展现敏感性分析的结果,这种分析是另一种提高机器学习结果可信度的方法。一般来说,为了检查你的线上应用能否通过稳定性测试或者极端情况测试,会通过使用数据可视化技术,展现数据和模型随时间的变化,或者展现故意篡改数据后的结果。有时这一技术本身即被认为是一种敏感性分析。
第二部分:在受监管的行业使用机器学习
对于在受监管行业中工作的分析师和数据科学家来说,尽管机器学习可能会带来『能极大提高预测精度』这一好处,然而它可能不足以弥补内部文档需求以及外部监管责任所带来的成本。对于实践者而言,传统线性模型技术可能是预测模型中的唯一选择。然而,创新和竞争的驱动力并不因为你在一个受监管的模式下工作就会止息。在银行,保险以及类似受监管垂直领域里,数据科学家和分析师正面对着这样一个独一无二的难题:他们必须要找到使预测越来越精准的方案,但前提是,保证这些模型和建模过程仍然还是透明、可解释的。
在这一节中所展现的技巧,有些使用了新型的线性模型,有些则是对传统线性模型做出改进所得到的方法。对于线性模型进行解释的技巧是高度精妙的,往往是有一个模型就有一种解释,而且线性模型进行统计推断的特性和威力是其他类型的模型难以企及的。对于那些对机器学习算法的可解释性心存疑虑而不能使用它们的实践者,本节中的技巧正适合他们。这些模型产生了线性、单调的响应函数(至少也是单调的!),和传统线性模型一样能保证结果是全局可解释的,但通过机器学习算法获得了预测精度的提高。
普通最小二乘(Ordinary Least Square,OLS)回归的替代品
受惩罚的回归(Penalized Regression)
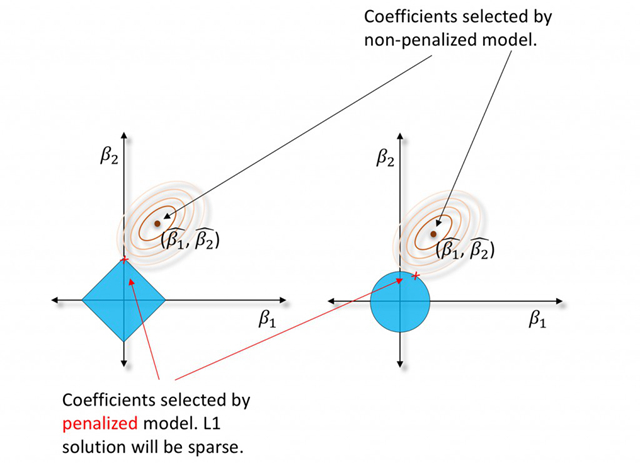
图7. 左图:经过L1/LASSO惩罚的回归系数处于缩小可行域中。右图:经过L2/岭回归惩罚的回归系数。感谢Patrick Hall, Tomas Nykodym以及H2O.ai团队友情提供图片
普通最小二乘法(Ordinary least squares,OLS)回归有着200年的历史。也许我们是时候该向前发展一点了?作为一个替代品,带惩罚项的回归技术也许是通往机器学习之路上轻松的一课。现在,带惩罚项的回归技术常常混合使用两种混合:为了做变量选择所使用的L1/LASSO惩罚,以及为了保证模型稳健性的Tikhonov/L2/ridge(岭回归)惩罚。这种混合被称为elastic net。相比OLS回归,它们对于数据所作出的假设更少。不同于传统模型直接解方程,或者使用假设检验来做变量选择,带惩罚项的回归通过最小化带约束的目标函数,来找到给定数据集中的一组最优回归系数。一般而言,这就是一组表征线性关系的参数,但是针对『给共线性或者无意义自变量以较大的回归系数』这一点,模型可以加以一定的惩罚。你可以在统计学习基础(Elements of Statistical Learning, ESL)一书中学到关于带惩罚项回归的方方面面,但是在此,我们的目的只是要强调一下,你很可能需要尝试一下『带惩罚项的回归』这一模型。
带惩罚项的回归被广泛地应用于不少研究领域,但是对于具有很多列,列数大于行数,列中存在大量多重共线性的商业业务数据集,它们仍然适用。L1/LASSO惩罚把无足轻重的回归系数拉回到0,能够选取一小部分有代表性的变量进行回归系数估计,供线性模型使用,从而规避了那些靠前向、后向、逐步变量选择法(forward, backward, stepwise variable selection)所带来的多模型比较困难的问题。Tikholov/L2/岭回归(ridge) 惩罚可以增加模型参数的稳定性,甚至在变量数目过多、多重共线性较强、重要的预测变量与其他变量存在相关性时也能保持稳定。我们需要知道的重点是:惩罚项回归并非总能为回归系数给出置信区间,t-检验值或者p-value(译者注:t-检验值和p-value都是检查模型显著有效性的统计量)。这些统计量往往只能通过额外花时间进行迭代计算,或者自助采样法(bootstrapping)才能得到。
广义加性模型(Generalized Additive Models, GAMs)
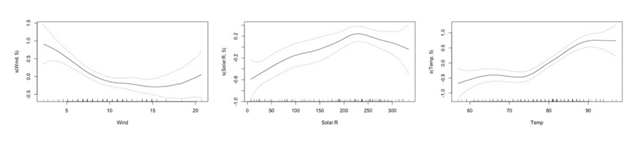
图8. 使用广义加性模型对多个自变量建立样条函数。感谢Patrick Hall以及H2O.ai团队友情提供图表
广义加性模型能够通过对一部分变量进行标准线性回归,对另一部分变量进行非线性样条函数的拟合的方式,手动调整模型,让你在递增的模型精度和递减的模型可解释性之间找到一个权衡。同时,大部分GAM能够方便地为拟合好的样条函数生成图形。根据你所承受的外部监管或者内部文档要求的不同,你也许可以在模型中直接使用这些样条函数来让模型预测的更准确。如果不能直接使用的话,你可以用肉眼观测出拟合出的样条函数,然后用更具可解释性的多项式函数、对数函数、三角函数或者其他简单的函数应用于预测变量之上,这样也能让预测精度提高。同时,你也可以靠查阅《统计学习基础》(Elements of Statistical Learning)加深对GAM的理解。
分位数回归
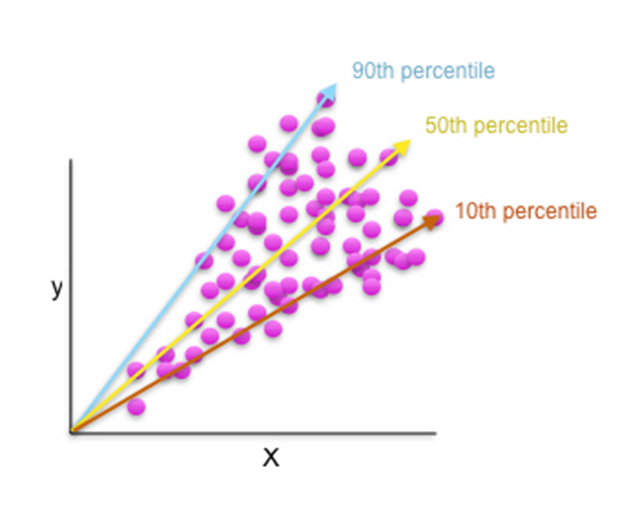
图9. 将分位数回归绘制为二维图表。感谢Patrick Hall以及H2O.ai团队友情提供图表
分位数回归让你能够使用传统可解释的线性模型对训练数据的分位点进行回归。这种回归允许你对不同的消费者市场细分或者不同账户投资组合行为细分,建立不同的模型,你可以使用不同的预测变量,也可以在模型中给予预测变量不同的回归系数。对低价值客户和高价值客户使用完全不同的两套预测变量和回归系数听上去还算合理,分位数回归对这种做法提供了一套理论框架。
回归的这些替代品提供的是全局性的还是局部性的可解释性?
回归的替代品往往能够提供全局可解释的函数,这些函数是线性的、单调的,根据其回归系数的大小以及其他传统回归的评估量、统计量,具备可解释性。
作为回归的替代品,这些回归函数的复杂程度如何?
这些回归函数一般来说是线性的、单调的函数。不过,使用GAM可能导致相当复杂的非线性响应函数。
这些技术如何帮我们提高对模型的理解?
比较少的模型假设意味着比较少的负担,可以不使用可能带来麻烦的多元统计显著性检验而进行变量选择,可以处理存在多重共线性的重要变量,可以拟合非线性的数据模式,以及可以拟合数据条件分布的不同分位点(这可不止是拟合条件分布),这些特性都可能让我们更准确的理解模型所表征的现象。
回归函数的这些替代品如何提高模型的可信度?
基本上,这些技巧都是值得信任的线性模型,只是使用它们的方式比较新奇。如果在你的线上应用中这些技巧带来了更精确的预测结果,那么我们就可以更加信任它们。
为机器学习模型建立基准测试模型
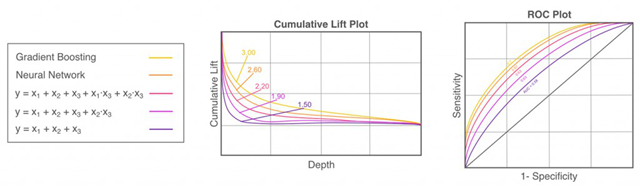
图10. 考虑交叉效应的线性模型与机器学习模型比较,并绘制评估图。感谢Patrick Hall以及H2O.ai团队提供图表
机器学习算法和传统线性模型的两个主要区别,一个是机器学习算法在预测时引入了很多变量的高阶交叉作用,并不直观,另一个是机器学习算法会产生非线性、非多项式、非单调甚至非连续的响应函数。
如果一个机器学习算法的预测表现碾压了传统线性模型,我们可以对自变量和目标变量建立一磕决策树。在决策树相邻层的分叉所使用的变量,一般来说会有强交叉效应。我们可以试着把这些变量的交叉效应加入到线性模型中,甚至树的连续几层所涉及到变量的高阶交叉效应也可以加入进来。如果一个机器学习算法较大地超越了传统线性模型,我们可以考虑把数据建模为分段线性的模型。为了要观察机器学习学到的响应函数如何受到一个变量各种取值的影响,或者要获得一些如何使用分段线性模型的洞见,可以使用GAM以及偏相关图。『多变量自适应回归样条法』,是一种可以自动发现条件分布中存在的复杂非线性部分,并对其不同区域分别进行拟合的统计手段。你可以尝试着直接使用多变量自适应回归样条法,对分段模型进行拟合。
面向机器学习模型的基准测试模型能提供全局性还是局部性的可解释性?
如果线性性和单调性能够得以保留,建模过程就会产生全局可解释的线性单调响应函数。如果使用分段函数,对机器学习模型建立基准测试可以放弃全局解释性,转而寻求局部可解释性。
面向机器学习模型的基准测试模型能够生成什么复杂度的响应函数?
如果谨慎、克制的建立面向机器学习模型的基准测试模型,并加以验证,对机器学习模型建立的基准模型可以维持像传统线性模型那样的线性性和单调性。然而,如果加入了太多的交叉效应,或者是在分段函数中加入了太多小段,将会导致响应函数依然极端复杂。
面向机器学习模型的基准测试模型如何提升我们对模型的理解?
这种流程把传统、可信的模型用出了新花样。如果使用类似GAM,偏相关图,多元自适应回归样条法这些技巧进行更进一步的数据探索,对机器学习模型建立相似的基准测试模型,可以让模型的可理解性大大提高,对数据集中出现的交叉效应以及非线性模式的理解也会加深。
面向机器学习模型的基准测试模型如何提高模型的可信度?
这种流程把传统、可信的模型用出了新花样。如果使用类似GAM,偏相关图,多元自适应回归样条法这些技巧进行更进一步的数据探索,通过建立面向机器学习模型的基准测试模型,能够让这些模型更准确地表达出数据集中我们感兴趣的那部分模式,从而提高我们对模型的信任程度。
在传统分析流程中使用机器学习
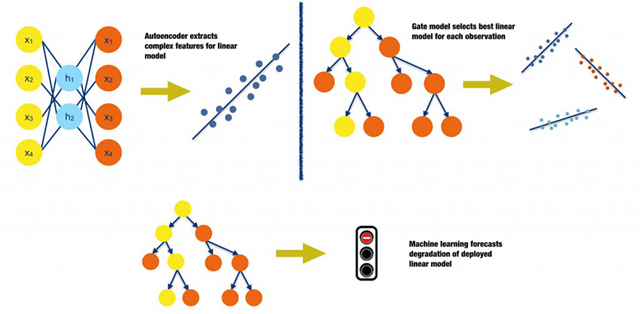
图11. 在传统分析流程中,使用机器学习的几种可能的方式,以图形呈现。感谢Vinod Iyengar以及H2O.ai团队友情提供图形
相较于直接使用机器学习的预测来做分析决策,我们可以通过一些机器学习的技术,对传统分析的生命周期流程(比如数据准备加模型部署)进行一些增强,从而有潜力达到比满足监管的线性、单调性的模型精度更高的预测。图11简要描述了三种可能的场合,在这些场合中,传统分析流程靠着机器学习的加持得以增强效果:
- 在传统的线性模型中,加入(加工过的)复杂自变量:
把交叉效应、多项式函数或者把变量经过简单函数的映射加入到线性模型中算得上是标准做法了。机器学习模型可以产生各种各样非线性、非多项式的自变量,甚至还能表征原有自变量之间存在的高阶交叉效应。产生这些自变量的方法有不少选择。例如,从自编码机神经网络中提取非线性特征,或者从决策树的叶子节点中获得最优化分箱。
- 使用多个带门限的线性模型:
根据重要的数据属性,或者根据不同的时间段对数据分成小组,再对每一个小组分别建模,可以获得更准确的模型。对于一个企业而言,同时部署多个线性模型来处理不同的细分市场数据,或者处理不同年份的数据,这类情况也并非少见。要决定如何手动融合这些不同的模型,对于数据分析师和数据科学家而言是个琐碎的活计。不过,如果关于历史模型表现的数据也能收集起来的话,这个流程就可以实现自动化:建立一个门限模型,让它来决定在遇到观测点时,究竟使用哪个线性模型来对它进行预测。
- 预测线性模型的退化行为:
在大部分情况下,模型是根据静态数据快照建立的,它们会在后来的数据快照上进行验证。尽管这是一种被广泛采纳的实践方式,但是当训练集、验证集数据所代表的真实世界中的数据模式发生变化时,这样做会导致模型发生退化。当市场中的竞争者进入或者退出,当宏观经济指标发生变动,当客户追逐的潮流发生了改变,或者其他各种因素发生时,都可能引起这种退化。如果关于市场、经济指标和旧模型表现的数据能够被上收上来,我们就可以基于此数据另外建立一个模型,来预估我们所部署的传统模型大概多久需要重新训练一次(译者注:仅调整模型参数),或者多久需要被全新的模型(译者注:模型结构发生了改变)所替代。就像在需要保养之前就替换掉一个昂贵的机械部件一样,我们也可以在模型的预测效力降低之前就进行重新训练,或者以新模型取而代之。(我之前写过一遍文章是有关应用机器学习时导致的验证误差,以及如何正确地在真实世界中使用机器学习的。)
当然,还有很多在传统模型的生命周期中引入机器学习技巧的机会。你可能现在就已经有更好的想法和实践了!
在传统分析流程中使用机器学习,能提供全局性还是局部性的可解释性?
一般来说,这种方法致力于保持传统线性模型所具有的全局可解释性。然而,在线性模型中加入机器学习算法所生成的特征,会降低全局可解释性。
在传统分析流程中使用机器学习,能产生何种复杂程度的响应函数?
我们的目标仍然是继续使用线性、单调性的响应函数,不过是以一种更加有效、更加自动化的方式来实现这一目的。
在传统分析流程中使用机器学习,如何帮助我们更好的理解数据?
在传统分析流程中引入机器学习模型的目的,是为了更有效、更准确地使用线性、可解释的模型。究竟是什么驱动力导致了数据表现出非线性、时间趋势、模式迁移?如果在线性模型中引入非线性项,使用门限模型,或者预测模型失效等等手段能够让你更深入地掌握这种知识的话,那么对数据的理解自然就加深了。
在传统分析流程中使用机器学习,如何让我们更加信任模型?
这种手段使我们可以理解的模型更加精确。如果对特征的增加确实导致了精度提升,这就暗示着数据中的关联现象确实以一种更可靠的形式被建模。
对可解释的模型进行小型的模型集成(ensemble)
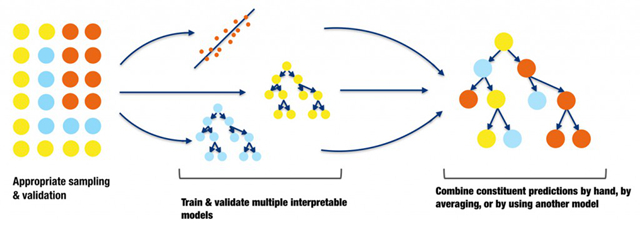
图12. 一个小型、堆叠的集成算法图。感谢Vinod Iyengar以及H2O.ai团队友情提供图形
很多企业如此擅长使用传统的线性模型建模技巧,以至于他们几乎无法再对单独某一个模型压榨出更高的精度。一种在不太损失可解释性的条件下提高精度的可能办法是,把数个已经理解透彻的模型组合起来进行预测。最终预测结果可以是对这些结果简单取平均,手动对它们进行加权,或者用更复杂的数学方式组合起来。举例说明,针对某种特定用途,总体表现最好的模型,可以和那些处理极端情况特别好的模型组合起来。对一名数据分析师或者数据科学家而言,他们可以通过实验来决定为对每一个模型选取最优加权系数进行简单集成;为了保证模型的输入和预测仍然满足单调性关系,可以使用偏相关图进行确认。
如果你倾向于,或者需要使用一种更严格的方式来整合模型的预测,那么『超级学习器(super learners)』是一个很棒的选择。在上世纪90年代早期,Wolpert介绍了『堆叠泛化法』(stacked generalization),超级学习器是它的某种实现。堆叠泛化法使用了一种组合模型来为集成模型中的每个小部分赋予权重。在堆砌模型时,过拟合是个很严重的问题。超级学习器要求使用交叉验证,并对集成模型中各个部分的权重加上约束项,通过这种方法来控制过拟合,增加可解释性。图12的图示表明,两个决策树模型和一个线性回归模型分别交叉验证,并且通过另外一个决策树模型把它们堆叠在一起。
可解释模型的小型集成提供了局部性还是全局性的可解释性?
这种集成可以增加精度,但是它会降低全局可解释性。这种集成并不影响其中的每一个小模型,但是集成在一起的模型会难以解释。
可解释模型的小型集成产生了何种复杂程度的响应函数?
它们会导致很复杂的响应函数。为了确保可解释性,使用尽可能少的模型进行集成,使用模型的简单线性组合,以及使用偏相关图来确保线性、单调性关系依然存在。
可解释模型的小型集成怎样让我们更好的理解数据?
如果这种把可解释模型组合在一起的流程能够让我们对数据中出现的模式更熟悉、更敏感,对未来数据进行预测、泛化时能够有所裨益,那么它就可以说是提高了我们对数据的理解。
可解释模型的小型集成如何让我们对模型更加信任?
这种集成让我们在没有牺牲太多可解释的情况下,对传统的可靠模型的精度进行一定的提升。精度提高意味着,数据中的有关模式以一种更可信、更可靠的方式被建模出来。当数个模型互为补充,做出符合人类预期或者领域知识的预测时,这种小型集成就显得更加可靠。
单调性约束
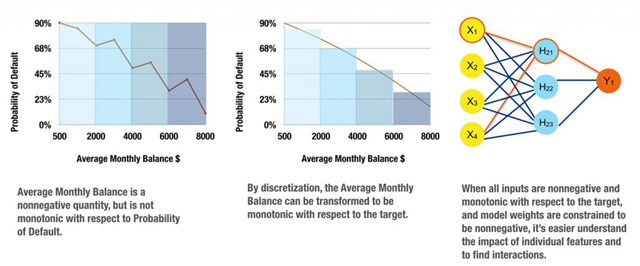
图13. 在神经网络中为数据和模型加入单调性约束的示意图。感谢Vinod Iyengar以及H2O.ai团队友情提供图表
单调性约束能够把难以解释的非线性、非单调模型转化成为高度可解释的、符合监管要求的非线性单调模型。我们之所以认为单调性很重要,是基于两个原因:
- 监管方希望模型满足单调性。无论数据样本是如何的,监管方总是希望见到模型具有单调性的表现。比如,考虑信贷评分模型中的账户余额。账户余额高,倾向于代表着账户所有者更值得授信,低账户余额则代表着有潜在的违约风险。如果某一批特定的数据包含着的大量样本中,含有很多『储蓄账户余额高但贷款违约』的个体以及『储蓄账户余额低但正在还贷款』的个体,那么,基于这份训练数据进行机器学习学出的响应函数对于账户余额这个变量自然会是非单调的。监管方是不会对这种预测函数感到满意的,因为它和几十年来沉淀下来的领域专家的意见背道而驰,因而会降低模型本身或者数据样本的可信度。
- 单调性能够令生成的『原因代码』保持一贯性。具有一贯性的原因代码生成一般被认为是模型可解释性的金标准。如果在一个信贷评分模型中,单调性得以保证,为信贷申请结果分析原因不但直观,而且能够自动化。如果某个人的储蓄账户余额低,那么他的信用水平自然也低。一旦我们能够保证单调性,对于一次授信决定(译者注:一般指拒绝授信)的原因解释可以根据最大失分法(max-points-lost)可靠地进行排序。最大失分法把一个个体放在机器学习所得到的、具有单调性的响应曲面上,并度量他和曲面上最优点(也就是理想的、可能具有最高信用水平的客户)的距离。这个人与理想客户之间,在哪个坐标轴(也就是自变量)距离最远,也就说明拒绝授信时,哪个负面因素最重要;而这个这个人与理想客户之间,在哪个坐标轴(也就是自变量)距离最近,也就说明这个原因代码产生的负面影响最不重要;根据这个人和『理想客户』的相对位置来计算,其他自变量的影响都排在这二者之间。在使用最大失分法时,单调性可以简单地确保我们能做出清晰的、符合逻辑的判断:在单调性模型下,一个在贷款业务中被授信的客户,其储蓄账户余额绝不可能低于一个被拒绝贷款的客户(译者注:在其他条件都接近的情况下)。
在输入数据上加约束,以及对生成的模型加约束,都可以产生单调性。图13显示,仔细选择并处理非负、单调变量,把它们与单隐层神经网络结合使用,达到了使拟合系数始终为正的约束效果。这种训练组合产生了非线性、单调的响应函数,根据响应函数可以对『原因代码』进行计算;通过分析模型的系数,可以检测高阶交叉效应。寻找以及制造这些非负、单调的自变量的工作十分枯燥、费时,还需要手动试错。幸运的是,神经网络和树模型的响应函数往往能够在规避枯燥的数据预处理的同时,满足单调性的约束。使用单调性神经网络意味着可以定制化模型结构,使得生成模型参数的取值满足约束。对于基于树的模型来说,使用均匀分叉往往可以强制保证单调性:使用某个自变量分的叉上,总是能保证当自变量取值往某个方向前进时,因变量在其所有子节点上的平均值递增;自变量取值往另一个方向前进时,因变量在其所有子节点上的平均值递减。在实践中,为不同类型模型实现单调性约束的方法千变万化,这是一种随模型而改变的模型解释性技术。
单调性约束提供了全局性还是局部性的可解释性?
单调性约束为响应函数提供了全局的可解释性。
单调性约束能够导致何种复杂程度的响应函数?
它们产生了非线性且单调的响应函数。
单调性约束如何让我们更好的理解数据?
它不仅可以确保『原因代码』能够自动化地生成,同时在特定场景下(比如使用单隐层神经网络或者单棵决策树时),变量之间重要的高阶交叉效应也能够被自动检测出来。
单调性约束如何让模型更可信赖?
当单调性关系、『原因代码』以及检测出的交叉效应能够简洁地符合领域专家意见或者合理预期的时候,模型的可信度会得以提升。如果数据中存在扰动时结果依然保持稳定,以及模型随着时间产生预料之内的变化的话,通过敏感性分析也能够提升模型的可信度。
第三部分:理解复杂的机器学习模型
在这一部分中我们所要展现的技术,可以为非线性、非单调的响应函数生成解释。我们可以把它们与前两部分提到的技巧结合起来,增加所有种类模型的可解释性。实践者很可能需要使用下列增强解释性技巧中的一种以上,为他们手中最复杂的模型生成令人满意的解释性描述。
代理模型
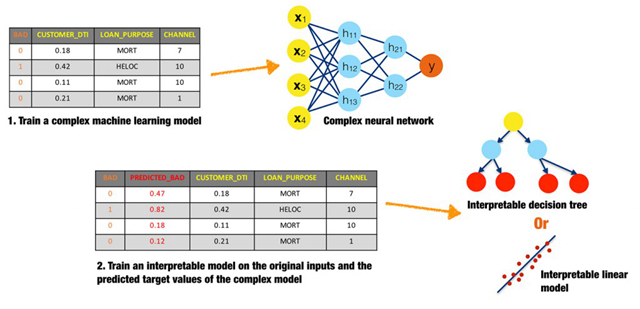
图14. 为了解释复杂神经网络而使用代理模型的示意图。感谢Patrick Hall以及H2O.ai团队友情提供图形
代理模型是一种用于解释复杂模型的简单模型。最常见的建立方法是,对原始输入和复杂模型给出的预测值建立简单线性回归或者决策树模型。代理模型中所展示的系数、变量重要性、趋势以及交互作用,是复杂模型内部机制的一种体现。不过,几乎没有理论依据能够保证简单的代理模型能够以高精度表达出更复杂的模型。
代理模型适用于何种尺度的可解释性?
一般而言,代理模型是全局性的。一个简单模型的全局可解释特性会用于解释一个更复杂模型的全局特性。不过,我们也无法排除代理模型对复杂模型条件分布的局部拟合能力,例如先聚类,再用自变量拟合预测值、拟合预测值的分位点、判断样本点属于哪一类等等,能够体现局部解释性。因为条件分布的一小段倾向于是线性的、单调的,或者至少有较好的模式,局部代理模型的预测精度往往比全局代理模型的表现更好。模型无关的局部可解释性描述(我们会在下一小节介绍)是一种规范化的局部代理模型建模方法。当然,我们可以把全局代理模型和局部代理模型一起使用,来同时获得全局和局部的解释性。
代理模型能够帮助我们解释何种复杂程度的响应函数?
代理模型能够有助于解释任何复杂程度的机器学习模型,不过可能它们最有助于解释非线性、非单调的模型。
代理模型如何帮我们提高对数据的理解?
代理模型可以针对复杂模型的内部机制向我们提供一些洞见,因此能提高我们对数据的理解。
代理模型如何让模型更可信赖?
当代理模型的系数、变量重要性、趋势效应和交叉效应都符合人类的领域知识,被建模的数据模式符合合理预期时,模型的可信度会得以提升。当数据中存在轻微的或者人为的扰动时,或者数据来自于我们感兴趣领域的数据模拟,又或者数据随着时间改变时,如果结合敏感性分析进行检验发现,对于模型的解释是稳定的,并且贴合人类领域经验,符合合理预期,那么模型的可信度会得以提升。
模型无关的局部可解释性描述(Local Interpretable Model-agnostic Explanation, LIME)
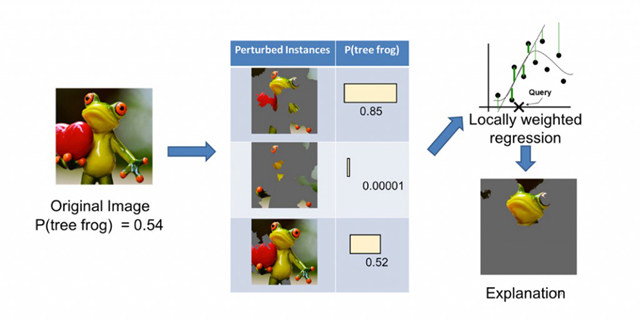
图15. 对LIME流程的一个描述,其中使用了加权线性模型帮助我们解释一个复杂的神经网络是如何做出某个预测的。感谢Marco Tulio Ribeiro友情提供图片。图片使用已获得许可
LIME是围绕单个样本建立局部代理模型的一种方法。它的主旨在于厘清对于特定的几个样本,分类器是如何工作的。LIME需要找到、模拟或者产生一组可解释的样本集。使用这组已经被详细研究过的样本,我们能够解释机器学习算法得到的分类器是如何对那些没有被仔细研究过的样本进行分类的。一个LIME的实现可以遵循如下流程:首先,使用模型对这组可解释的数据集进行打分;其次,当模型对另外的数据进行分类时,使用解释性数据集与另外的数据点的距离进行加权,以加权后的解释性数据集作为自变量做L1正则化线性回归。这个线性模型的参数可以用来解释,另外的数据是如何被分类/预测的。
LIME方法一开始是针对图像、文本分类任务提出的,当然它也适用于商业数据或者客户数据的分析,比如对预测客户群违约或者流失概率的百分位点进行解释,或者对已知的成熟细分市场中的代表性客户行为进行解释,等等。LIME有多种实现,我最常见的两个,一个是LIME的原作者的实现,一个是实现了很多机器学习解释工具的eli5包。
LIME提供的可解释性的尺度如何?
LIME是一种提供局部可解释性的技术。
LIME能帮助我们解释何种复杂程度的响应函数?
LIME有助于解释各种复杂程度的机器学习模型,不过它可能最适合解释非线性、非单调的模型。
LIME如何帮我们提高对模型的理解?
LIME提供了我们对重要变量的洞察力,厘清这些变量对特定重要样本点的影响以及呈现出的线性趋势。对极端复杂的响应函数更是如此。
LIME如何让模型更加可信?
当LIME发现的重要变量及其对重要观测点的影响贴合人类已有的领域知识,或者模型中体现的数据模式符合人类的预期时,我们对模型的信心会得到增强。结合下文将会提到的最大激发分析,当我们能明显地看到,相似的数据被相似的内部机制处理,全然不同的数据被不同的内部机制处理,在对多个不同的样本使用不同处理方式上,能够保持一贯性。同时,在数据存在轻微扰动时,数据是由我们感兴趣的场景模拟得出时,或者数据随时间改变时,LIME可以被视为是敏感性分析的一种,帮助我们检查模型是否依然能够保持稳定,是否依然贴合人类的领域知识,以及数据模式是否依然符合预期。
最大激发分析
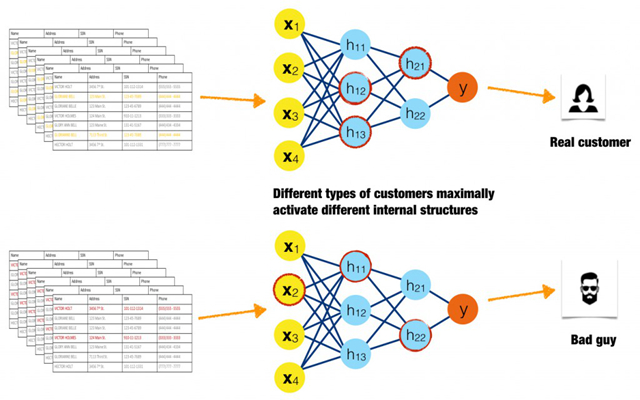
图16. 不同输入数据激发神经网络中不同神经元的示意图。感谢Patrick Hall以及H2O.ai团队友情提供图片
在最大激发分析中,可以找到或者模拟出这样的例子,它们总是会对特定的神经元、网络层、滤波器(filter)、决策树集成模型中的某棵树进行大量激发。像第二部分所提到的单调性约束一样,最大激发分析在实战中,是一种很常见的与模型相关的解释性分析技术。
对于特定的一组样本或者一类相似的样本,观察它们能够对响应函数的哪一部分进行最大程度的激发(对于神经元而言是激发强度最大,对于树模型而言是残差最低,二者都可以算最大激发),这种最大分析厘清了复杂模型的内部工作机制。同时,如果不同类型的样本持续激发模型中相同的部分,那么这种分析也可以发现交叉效应。
图16描绘了一种比较理想化的情况:一个好的客户和一个欺诈型客户分别以高强度激发了两组不同的神经元。红圈表示两类输入数据所激发的强度排名前三的神经元。对于这两类数据而言,最大激发的神经元不同,表示着对于不同类型的样本,神经网络的内部结构会以不同的方式对其进行处理。如果对很多不同子类型的好客户和欺诈型客户而言这种模式依然存在,那么这就是一种很强烈的信号,意味着模型内部结构是稳定的、可靠的。
最大激发分析适用于哪种尺度的可解释性?
最大激发分析在尺度上是局部性的,因为它刻画了一个复杂响应函数的不同部分是如何处理特定的一个或者一组观测样本的。
最大激发分析能够帮助我们解释何种复杂程度的响应函数?
最大激发分析能够解释任意复杂的响应函数,不过它可能最适合于解释非线性、非单调的模型。
最大激发分析如何让我们更好的理解数据和模型?
最大激发函数通过像我们展示复杂模型的内部结构,提高我们对数据、模型的理解。
最大激发分析如何让模型变的更加可信?
上文讨论过的LIME有助于解释在一个模型中对条件分布的局部进行建模并预测。最大激发分析可以强化我们对模型局部内在机制的信心。二者的组合可以为复杂的响应函数建立详细的局部解释,它们是很棒的搭配。使用最大激发分析,当我们能明显地看到,相似的数据被相似的内部机制处理,全然不同的数据被不同的内部机制处理,对多个不同的样本使用不同处理方式这一点保持一贯性,模型中发现的交互作用贴合人类已有的领域知识,或者符合人类的预期,甚至把最大激发分析当做一种敏感性分析来用,以上的种种都会让我们对模型的信心得以提高。同时,在数据存在轻微扰动时,数据是由我们感兴趣的场景模拟得出时,或者数据随时间改变时,最大激发分析可以帮我们检查模型对于样本的处理是否依然保持稳定。
敏感性分析

图17. 一个变量的分布随着时间而改变的示意图。感谢Patrick Hall以及H2O.ai团队友情提供图片
敏感性分析考察的是这样一种特性:给数据加上人为的扰动,或者加上模拟出的变化时,模型的行为以及预测结果是否仍然保持稳定。在传统模型评估以外,对机器学习模型预测进行敏感性分析可能是最有力的机器学习模型验证技术。微小地改变变量的输入值,机器学习模型可能会给出全然不同的预测结论。在实战中,因为自变量之间、因变量与自变量之间都存在相关性,有不少线性模型的验证技巧是针对回归系数的数值稳定性的。 对从线性建模技术转向机器学习建模技术的人而言,少关注一些模型参数数值不稳定性的情况,多关心一些模型预测的不稳定性,这种做法可能还算是比较谨慎。
如果我们能针对有趣的情况或者已知的极端情况做一些数据模拟,敏感性分析也可以基于这些数据对模型的行为以及预测结果做一些验证。在整篇文章中提及或者不曾提及的不少技巧,都可以用来进行敏感性分析。预测的分布、错误比率度量、图标、解释性技巧,这些方法都可以用来检查模型在处理重要场景中的数据时表现如何,表现如何随着时间变化,以及在数据包含人为损坏的时候模型是否还能保持稳定。
敏感性分析适用于什么尺度的可解释性?
敏感性分析可以是一种全局性的解释技术。当使用单个的像代理模型这种全局性解释技术时,使用敏感性分析可以保证,就算数据中存在轻微扰动或者有人为造成的数据缺失,代理模型中所存在的主要交叉效应依然稳定存在。
敏感性分析也可以是一种局部性的解释技术。例如,当使用LIME这种局部性解释技术时,它可以判断在宏观经济承压的条件下,为某个细分市场的客户进行授信时,模型中使用的重要变量是否依然重要。
敏感性分析能够帮我们解释何种复杂程度的响应函数?
敏感性分析可以解释任何复杂程度的响应函数。不过它可能最适合于解释非线性的,或者表征高阶变量交叉特征的响应函数。在这两种情况下,对自变量输入值的轻微改变都可能引起预测值的大幅变动。
敏感性分析如何帮助我们更好的理解模型?
敏感性分析通过向我们展现在重要的场景下,模型及其预测值倾向于如何表现,以及这种表现随时间会如何变化。因此敏感性分析可以加强我们对模型的理解。
敏感性分析如何提高模型的可信可信度?
如果在数据轻微改变或者故意受损时,模型的表现以及预测输出仍然能表现稳定,那么稳定性分析就可以提高我们对模型的信任。除此以外,如果数据场景受到外来影响,或者数据模式随时间发生变化时,模型仍然能够符合人类的领域知识或者预期的话,模型的可信度也会上升。
变量重要性的度量
对于非线性、非单调的响应函数,为了量化衡量模型中自变量和因变量的关系,往往只能度量变量重要性这一种方法可以选。变量重要性度量难以说明自变量大概是往哪个方向影响因变量的。这种方法只能说明,一个自变量跟其他自变量相比,对模型影响的相对强弱。
变量重要性的全局度量
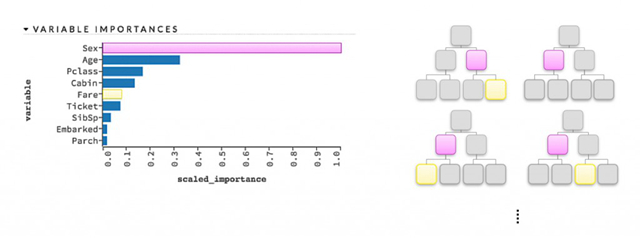
图18. 在决策树集成模型中,对变量重要性的描绘。感谢Patrick Hall以及H2O.ai团队友情提供图片
在基于树的模型中使用变量重要性度量是一种常见做法。如图18所示,一种拍脑袋的变量重要性规则是,同时考虑树模型中一个变量用于分叉的所在深度和出现的频率:自变量所在分叉位置越高(译者注:在越浅的层数出现),或者自变量在树中出现的频率越高,那么它就越重要。对于单棵决策树来说,每次这个自变量在某个节点成为最佳分叉使用的变量时,把对应的分支准则(Splitting Criterion)收益累加起来,就可以量化地判断这个变量究竟有多重要。对于梯度提升树的集成(译者注:Gradient boosted tree ensemble, 往往也称作GBDT)而言,可以先对单棵树计算变量重要性,然后再做聚合加总;我们还有一种额外的度量,如果把单个自变量排除掉之后导致了模型精度的降低,那么这个精度差异可以代表自变量在模型中有多重要(Shuffling,洗牌法可以视作考察排除一个/一部分变量的效应,因为其他变量并没有被洗掉)。对于神经网络而言,对我们感兴趣的特定自变量的重要性度量,一般来说是它所对应的模型参数绝对值的加总。全局性的变量重要性度量技术往往因模型而异,实践者们要特别注意,变量重要性的简单度量可能会偏向于那些取值范围较大,包含类别数目较多的那些变量。
去除某一自变量的分析法(Leave-One-Covariate-Out, LOCO)
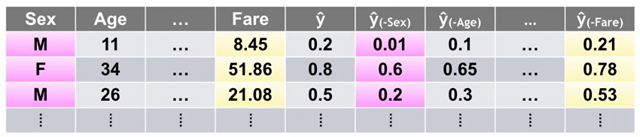
图19. LOCO方法的示意图。感谢Patrick Hall以及H2O.ai团队友情提供图表
最近某篇文章的预印版本给出一种局部性的、模型无关的、通过模型平均精度下降的方式来考察变量重要性的度量,称为『去除某一自变量的分析法』(Leave-One-Covariate-Out),简称LOCO。最开始LOCO是用于回归模型的,不过LOCO的大体思想是无关于模型的,而且可以有多重不同的实现。可以按照如下流程实现LOCO:对训练集或验证集中的每一行以及每一个变量(自变量)进行局部性的重要性评分。在此之外,每一个变量被设置为缺失值、零值、平均值或者其他值域中的值,来把它在预测时起到的效果消除掉。对预测精度有最大绝对影响的自变量就是对那一行预测时的最重要变量,同时,可以对每一行中所有变量对预测的影响大小进行排序。LOCO还能为每一个变量计算它们对整个数据集精度的平均影响,给出全局性的变量重要性度量,甚至还能给出这些全局变量重要性度量的置信区间。
变量重要性度量适用于哪种尺度的可解释性?
一般来说变量重要性度量方法提供的解释性是全局的;不过LOCO方法可以为数据集中的每一行或者新来的数据提供局部的变量重要性度量。
变量重要性度量能够帮我们解释何种复杂程度的响应函数?
变量重要性度量对于非线性、非单调的响应函数而言是最有效的;不过它们可以广泛应用于各种机器学习习得的响应函数上。
变量重要性度量如何帮我们更好的理解模型?
变量重要性度量让我们对模型中最具影响力的变量及其影响力顺序有所了解,因而提高了我们对模型的理解。
变量重要性度量如何让模型更加可信?
如果变量重要性度量的结果能够贴合人类领域知识、符合人类预期,在数据存在轻微扰动或人为干扰的情况下仍然保持稳定,在数据随时间变化或者经由模拟得到时变动幅度可以接受的话,那么它就能够让模型更加值得采信。
决策树模型解释器
图20. 单棵决策树中,对于某一样本点的预测,以高亮的决策路径显示。感谢Twitter网友 @crossentropy友情提供图片。图片的使用已获得允许
几种『平均树』的解释方法已经提出了几年了,不过名为『决策树模型解释器』的简单开源工具最近几个月才开始流行起来。决策树模型解释器把决策树、随机森林给出的预测进行分解,表示成为全局平均值(bias)和各个自变量带来的贡献之和。决策树模型解释器是专门为决策树设计的算法。图20显示了如何将决策树中的决策路径分解成为全局平均值以及各个自变量的贡献。图中给出了某个特定的样本的决策路径(决策树模型不仅可以输出模型中的平均值和自变量的贡献值,也能输出对于某个样本而言的平均值以及自变量的贡献值)eli5包中也有一个决策树解释器的实现。
决策树解释器适用于哪种尺度的模型可解释性?
当决策树解释器给出在整棵决策树或者整个随机森林中各个自变量的平均贡献时,它的解释性就是全局的。当它用于解释某些特定的预测时,它的解释性就是局部的。
决策树解释器能够解释何种复杂程度的响应函数?
决策树解释器往往是用于解释由决策树、随机森林模型构建的非线性、非单调响应函数的。
决策树解释器如何提高我们对于模型的理解?
对于决策树以及随机森林模型中的自变量,决策树解释器通过展示它们平均的贡献,并对它们进行排序,来增进我们对模型的理解。
决策树解释器如何让模型变得更加可信?
如果决策树解释器所展现的结果能够贴合人类领域知识、符合人类预期,在数据存在轻微扰动或人为干扰的情况下仍然保持稳定,在数据随时间变化或者经由模拟得到时变动幅度可以接受的话,那么它就能够让模型更加值得采信。
结语
在最近几个月里,当我的朋友和同事们听说我要写这篇文章后,他们用邮件、短信、推特、Slack提醒我这方面新工作的速度简直是有增无减。现在,我很可能一天要看两个新的算法库、算法或者论文,我几乎不可能跟上这样一种节奏,把这些东西一股脑塞进这篇综述性的文章中。实际上,这篇文档总要有个尽头,必须要在某个地方戛然而止。所以我们就在这里停下吧!我相信,为了让理解机器学习的可解释性更上一层楼,这篇文章提供了有效的总结,把这些解释性技巧从四个标准上进行分类:它们的尺度(局部性的,或者全局性的),它们所能解释响应函数的复杂程度,它们的应用领域(跟特定模型相关,或者跟特定模型无关),以及它们如何能够更易于理解、更容易受信任。同时,我相信,这篇文章涵盖了主流类型的技巧,尤其是那些领域应用型的或者是商业应用型的技巧。如果我有更充裕的时间能够无止尽的向本文添砖加瓦的话,我想要马上给读者展现的是两个课题:一个课题是RuleFit(译者注:基于规则的集成模型工具,RuleFit3是R语言中的一个包),另一个课题则是让深度学习更具可解释性的诸多工作,比如论文『学习深度k近邻表达』即是其中之一。针对这两个课题我自己当然是要深入钻研下去的。
如此多的新进展纷至沓来,对于在这个课题(即机器学习可解释性)上做研究的人而言,这是个令人激动的时代。我希望你们能够在这篇文章中发现有用的信息。因为这个领域可以把机器学习和人工智能以更有效、更透明的方式传达给用户和客户,我希望那些跟我处于统一领域的工作者们能够像我一样,受到这些具有光明未来的革命性技术的鼓舞。
更多阅读:
