
“应用机器学习像是把你当一个伟大的工程师,而非伟大的机器学习专家。”
这是我在一份谷歌内部文件中读到的如何应用机器学习的第一句话。的确如此。以我作为服务器工程师/数据分析师的有限经验,数据(以及如何存储/处理)一直都是所有问题的核心,在整体中举足轻重。去问问任何一位Kaggle的获胜者,他们都会说,最大的收获总是来源于聪明地表示数据,而不是使用某些复杂的算法。即使CRISP数据挖掘处理也使用了不是一个,而是两个阶段,专门用来理解和准备数据。
◆ ◆ ◆
特征工程
那么,什么是特征工程?
简而言之,就是用最好的方法来表示数据的艺术/科学。
为什么说是艺术/科学?因为好的特征工程是专业知识,直觉和基础的数学能力的优雅组合。呃,最有效的数据表示法基本不包含任何数学计算(下文我会解释)。“最好的”是什么意思?大体上,提供给算法的数据的方式,应该以最有效的方式表示潜在信息的相关结构/属性。当你进行特征工程时,你是在把你的数据属性转化为数据特征。
属性基本上是数据的所有维度,但是所有这些以原始形态存在的属性是否以最佳的表示方式表示了你想学习的潜在趋势?也许不是。所以特征工程是对数据进行预处理,在此基础上进行建模/建立学习算法,从而可以花最小的力气处理噪声数据。在此“噪音”的含义是,任何与学习/预测你的最终目标无关的信息。实际上,由于你已经自己完成了一部分“思考”的工作,使用好的特征甚至可以让你使用简单得多的模型。
但是就像任何机器学习中的技术一样,一定要通过验证确保你引入的新特征确实能够改进预测,而不是增加不必要的复杂性。如果机器学习是发型:模型—华丽的,装饰的,不易打理的,特征工程—接地气的,即兴的,直接的。
如同之前提到的,好的特征工程包含直觉,专业知识(个人经验)和基本的数学技巧。以下是几个非常简单的技巧,你可以应用在你的下一个数据科学解决方案中。
1.表示时间戳
时间戳属性经常是用EPOCH时间来定义,或者分离到多个维度里,比如(年,月,日,时,分,秒)。但是在很多场合下,很多信息是不必要的。比如,在一个监督学习系统里,预测一个城市关于地点+时间的交通流量,如果以秒来发现其趋势,很有可能得到错误的结论。以年为单位对这个模型来说没有太多价值;小时,天和月可能是你需要用到的维度。所以,当表示时间时,试着去确认一下你的模型是否需要你所提供的所有数字。
别忘了时区。如果你的数据源自不同的地域,务必记得在需要的时候用时区做标准化。
2.分解分类型属性
有的属性是种类而非数字。一个简单的例子是“颜色”属性,比如{红,绿,蓝}之一。最常见的表示方法是将种类转化为二元属性,从{0,1}中二取一。于是你得到了一系列增加的属性,数目与种类的个数相等,而且在每个数据点的这一系列属性中,只有一个的值是1(其余的都是0)。这是一种独热编码形式。
如果你第一次接触到这个概念,你可能会认为分解属性是平添了不必要的麻烦(本质上我们扩大了数据集的维度)。相反,你可能更愿意将种类属性转变为一个标量值,比如,颜色特征可能用{1,2,3}代表{红,绿,蓝}。这会带来两个问题。第一,对于一个数学模型,这个可能表示“红色”比“蓝色”更接近“绿色”(因为|1-3|>|1-2|)。除非你的种类的确包含自然顺序(natural ordering)(比如一条火车线路上的车站),否则的话这种表示法可能会误导你的模型。第二,它可能导致统计学参数(比如平均值)失去意义。甚者,造成误导。再次考虑颜色的例子,如果你的数据集包含同样多的红色和蓝色值,而没有绿色值,取平均值仍会得到“2”——代表着绿色!
将种类属性转化为标量值最安全的情况是当你只有两个种类时。这样你就有了{0,1}对应{种类1,种类2}。这种情况下,“次序”不是必要的,并且你可以将属性值解读为属于种类2抑或种类1的概率值。
3.数字分组
有时候,将数字属性表示成分类属性也是一种有效的分析方法。这种方法通过将数字分段划组,来减少噪声对机器学习算法的干扰。比如说,如果我们要预测一个人是否拥有某一件特定的衣服。显然年龄是一个影响因素。实际上年龄组可能更加恰当一些。所以我们可以给年龄分段,比如1-10岁,11-18岁,19-25岁,26-40岁等。对于这样的分类,我们便没有必要像第2点所说的那样再去做类别内的分解,直接用标量值划分组别就可以了,因为相近的年龄组确实是有相似之处的。
属性域能被清楚归类的数据,其同一区间的数字能够代表相同的特征,分组这种方法就比较适用于这样的数据。如果你不想让你的模型区分太相近的数值,这种方法可以减少一些应用中的过拟合问题。比如说,如果你的关注点是一整个城市,你就可以把该城市所有的纬度归到一起。分组这个方法通过将数值”化整”到离它最近的典型数值,来减少微小错误带来的影响。不过,如果分组数量与你的可能值数量相当,或者你要求很高的精度,那么数据分组就没有什么意义了。
4.特征交叉
特征交叉也许是这些方法中最为重要和有用的一种了。这种独特的方法可以将两个或两个以上的类别属性组合成一种。这个方法非常有用,尤其如果相对于单个属性本身,与其他属性的结合能更好地表示某些特性。从数学上讲,是把所有这些属性的可能值做了叉乘。
若某特征A的值域为{A1,A2},特征B的值域为{B1, B2}。A和B之间的交叉特征(我们称之为AB)则是以下这些值中的一个:{(A1, B1),(A1, B2), (A2, B1), (A2, B2)}。你可以自由命名这些“组合”,任何一个组合都代表了A或B特征中的某些信息的合成。
比如以下图表:
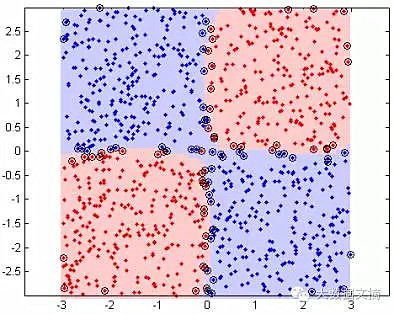
另一个更加具体也更加相关的好例子是经纬度。一个常见的纬度值与世界上很多地方都有关联,经度也是这样。但是如果你将经纬度相结合,并划分到不同的“区块”,它们就可以代表地理上的“地区”,各个地区内部有着相似的特性。
有时候,多个数据属性可以通过简单的数学计算被“组合”成一个新的特征。在上一个例子中,假设你把特征重定义 为和
为和 :
:

 :
:
作为补充,我接下来将简单介绍几个数学上比较复杂的特征工程技巧,并附带了链接以便大家更好地理解。
5.特征选取
运用某些算法来自动选择原始数据特征中的一个子集,以建立最终模型。你不需要建立/修改现有的数据特征,而是对它们进行删减,来降低干扰,减少数据冗余。
6.特征缩放(数据标准化)
有时候,你可能会注意到有些属性的数量级比别的属性更大,比如一个人的收入,相对于他的年龄而言。在类似的情况下,有些模型(比如岭回归)就要求你把所有的属性都缩放到一个可比较的、同等的范围内。这可以防止某些属性被给予过多的权重。
7.特征提取
特征提取包含了许多算法,它们能够从原始数据属性中自动生成新的特征集合。数据降维是这类方法里的一种。
来自:大数据文摘
更多阅读:
