
9月16日,阿里数据经济研究中心(ADEC)以数据经济新型智库平台的角色,牵手清华大学公共管理学院举办了一场主题为“政府数据开放的挑战、困惑与探索”的沙龙,来自清华、北大、人大、复旦、一财研究院、中科院、国研中心等学界和研究机构的30多位业内学者专家以及阿里巴巴集团的专家参与了此次思想的碰撞与交流,沙龙形式活泼,主题分享和分组讨论气氛热烈。本文为复旦大学移动与数字治理实验室主任郑磊的沙龙发言《中国地方政府开放数据现状、问题与难点》,此为上篇。

我们实验室最近选了七个开放政府数据的城市和城区做了研究评估,今天先给大家汇报一下这个报告的发现,然后再讲一下我们在各种研究和案例调研中发现的一些开放数据中的难点,然后提出一些可能的路径和建议。
关于政府数据开放的概念
开放政府数据跟之前的信息公开是相关的,但是这两个也有重要的差别,现在我看到有些报道把政府信息公开和数据开放等混在一起,信息公开是保障知情权,公开的大多是一些文件、政策,也公开了一些数据,主要是为了保障知情权,也就让你知道的权利等,而数据开放则是强调利用权,我们在评估数据开放平台的时候,这是一个重要的切入点,如果你把数据上传到平台只是让大家去查询,而无法利用,那就只是公开而不是开放。所以公开和开放是两个概念,我们在调研当中发现有一些网站,他说是数据开放,但其实只属于数据发布和信息公开,不是真正的开放,因为没法下载和利用这些数据。
下一张图,纵轴上是信息层和数据层,数据层是底层的,对数据层进行加工和解读才成为信息,横轴上从左到右是知情,有限利用和自由利用,传统的“政府信息公开”是在知情这个层次,过去提到过的“政府信息资源再利用“主要指的是有限利用,政府把信息给几家比较信任的公司,只让他们来开发利用,这就是有限利用,不是平等的、开放的自由下载和利用,其他的公司得不到这些数据就没有办法开发利用。
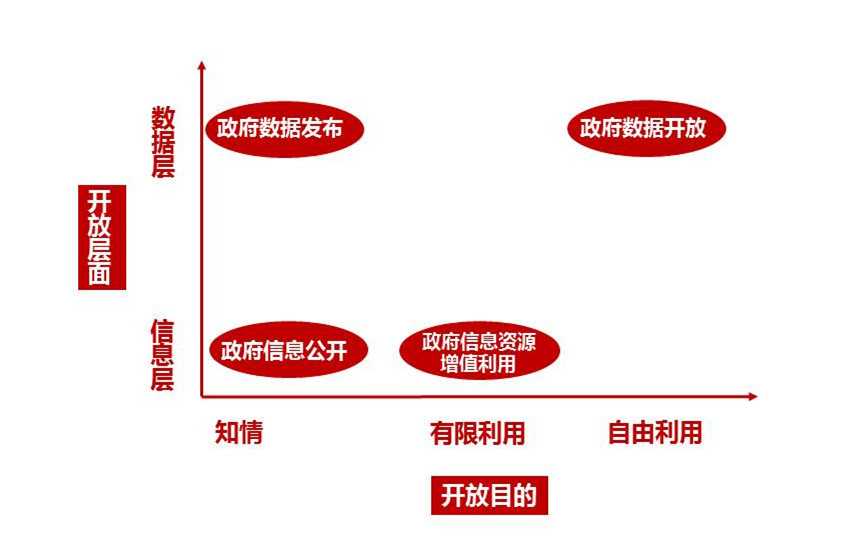
数据开放是要开放到数据层,同时又能保障自由利用,大家有平等的使用的权利。虽然“政府信息公开”有时也达到了数据层,但更多的是数据查询服务和数据发布,并不能让人下载利用这些数据。政府开放数据的思路把数据层跟应用层分开,政府提供数据,但政府自己不再需要把数据开发成应用,这时政府依然在提供公共服务,但不再需要自己生产公共服务,而是与市场实现合作共创,共同为社会创造价值。
举一个例子,如果我们把数据当成底层资源,数据相当于大米,我把大米开放给社会以后,社会是可以做成各种饭的,取决于他想吃什么饭,他善于做什么饭,以及社会需要什么饭。如果政府自己把米做成了蛋炒饭,就面临三种情况,一、别人想不想吃蛋炒饭?如果别人只想吃白米饭怎么办?众口难调怎么办?二、政府自己来开发数据需要花财政的钱,而开放数据给市场来开发花的是市场的钱。三、政府能做得比市场好吗?有那么多的人和时间来开发一个个的应用吗?市场的需求越来越多元化,政府的投入总是有限的,能忙得过来吗?结果就是政府自己做的很辛苦,但吃力不讨好。其实政府只需开发一些基本的应用作为公共产品,个性化的应用让市场自己去开发就可以了。
中国政府开放数据现状与问题
我们对于开放数据的研究,目前得到了三方面的资助,包括国家自然科学基金,世界银行开放数据能力评估与建设课题以及上海市开放政府数据三年规划课题。我们去年首先做文献理论和框架构建,今年开始做现状评估。我们参考了国际上知名的针对各国的开放数据评估报告,这些报告主要是针对国家层面的,而我国是地方层面现行探索,国家数据开放平台尚未推出,所以目前尚缺少对中国地方政府开放数据现状与问题的研究。我们希望通过该研究建立一套适用于中国国情的地方政府开放数据实践评估框架,呈现和评估中国地方开放数据实践的现状与问题,然后为我国开放政府数据实践提供政策建议。
我们首先对国际上的十几种开放数据报告进行梳理,然后探索建立适合中国的评估框架。我们决定首先针对供应端,也就是政府开放数据平台进行评估,国际上的评估报告同时对供应端和需求端进行评估,比如开放数据500强,哪些公司利用政府开放的数据,给他建立500强,这是对需求端的评估,但是中国开放政府数据刚刚起步,还没发展到这一步,目前的工作主要集中在数据的供应端,先要把数据开放出来,才谈得上对应用端进行评估,所以我们这次的评估报告主要针对供应端。
我们采用三个一级指标:平台层、数据层和基础层,下面有13个维度和53项指标。第一个是平台层,然后是数据层,平台建的再好,上面没有干货的数据也不行,这个是更关键的,在表面的平台层和数据层之后,还有基础层,更多是指体制机制的支撑,经济社会的基础,而不是指技术上的基础设施。我们这次报告采集的数据主要来自互联网上公开可见的数据和信息,不包括从政府内部得到的信息。我们选取了几个比较有引领性的、有代表性的七个地方,北京、上海、武汉、无锡、湛江、宁波海曙、佛山南海。
首先看数据层,这七个地方平均公开278个数据集。武汉号称最多,他是635,但是有一半是PDF格式的,可机读比例仅54%,不能让人直接利用,其实还是以信息公开为主。可机读数据开放最多的是上海市,一共有398个数据集,各地平均可机读率是84.1%。各地平均有86.25%是静态数据,仅17.21%的数据按承诺得到了更新。仅无锡、海曙明确保障数据的永久免费;各地的开放数据中,0%明确赋予并保障自由增值、解读、分享数据的权利。
总的来说,现在开放数据总量还是偏低,可机读性差,大多为静态数据,数据按承诺更新比例低,整体都未严格符合开放授权。
然后看平台层,各地方平台包含三个模块,一个是数据导引,一个是数据获取,一个是互动交流,这是双向的,你需要什么数据或者提一些问题。我们发现,只有无锡和湛江是无需注册即可下载数据,开放出来的数据既然已经经过了国家安全、商业机密和个人隐私的审核,开放之后谁来下载利用应该是自由便利的,不一定非要注册跟踪,当然政府也确实想知道开放的数据产生了怎样的效益,有利于下一步的开放。
开放数据本身不会直接产生价值,只有开放出来的数据被社会利用了才真正有意义。各地都开设了应用展示频道,展示市场上基于开放数据开发出来的应用,这样就形成一个循环,政府开放数据市场拿去用开发成应用,然后政府的开放数据网站上还成为一个展示这些应用的一站式的平台,这样首先政府一方面知道了谁利用了我开放的数据,更重要的是也让公众容易找到这些应用。展示应用数量最多的是上海,列出APP共 78个,各地平均APP数量为20个,但需要指出的是,这些展示出来的应用很多并不是市场开发的,而是政府自己开发的。
研究还发现仅宁波海曙一个地方公开了用户提出的数据请求,其他的地方只有政府后台才能看见这些请求。对比国外的开放数据平台,用户在提交数据需求后,还发起了附议的行动,其他有同样需求的公众可以点赞附和。报告还发现,仅佛山南海开设了社交媒体帐号向公众传播开放数据信息,仅上海一个地方实现了数据平台的移动端适配。这些数据都是截止到五月底的数据,我们希望每半年更新一次这个数据。在平台层的总体现状是普通交互便捷性差,缺乏高质量数据应用展示,沟通交流缺乏便捷性、有效性和公开性。
在基础层,数据开放已经从特大型城市扩展到不同地域、不同规模的地方,但依然集中于沿海一二线地区,经济通常较为发达,政府信息化基础相对较好、IT产业发展具备一定潜力的城市。针对开放数据的专门政策和工作方案普遍缺位,管理体制和领导力支持尚不足以支撑工作推进。从体制保障来看,仅南海、上海建立了专门针对数据统筹开放的主管单位,特别是南海成立了数据统筹局。仅上海公开发布了开放数据的针对性政策和工作方案。仅上海、南海有公开报道高层行政领导对开放数据的支持。
总体来说,上海跟南海两地整体数据开放水平最高,武汉、宁波海曙相对偏低。
然而,如果把上海跟纽约在一起比,差距仍然很大。上海是31个部门开放435个数据集,纽约是98个部门1831个数据集。当然,我们不能光看数据集的数字,还要看数据的价值。我还想重点指出的是在开放数据集的同时,还要开放元数据,元数据开放才会让大家更多了解数据的背景,告诉我们数据什么时间采集,如何采集的,然后在利用的时候就能用得更好,也会发现原来有些开放的数据集并不是自己想要的。可以看到纽约市开放的元数据字段有22项,而上海市是13项。再有是格式的多样性,纽约是五星指标,说明格式种类很丰富,而上海是二星指标,因为其开放的数据主要是EXCEL格式为主。这几个关键指标其实代表了数据是否能被容易便利地利用。
来源:阿里研究院
更多阅读:
