
无论是产品还是服务都是围绕用户来展开工作的。用户量和用户增长快是每一个App追求的目标方向,也是企业商业变现的基石。
对运营来说,掌握数据分析能力能为运营提供大量支持,但拿到数据后运营到底该怎么看?如何通过数据分析找到用户增长之路?为此我们采访了Top20的运营大佬们,将观点整合为您呈上:
用户数据怎么看?
很多的产品经理看用户数据基本有三个层次:
“看到”第一层:看总量
“看到”第二层:看构成
“看到”第三层:看行为
先说第一个层次,这个是最简单的:
1、“看到”第一层:看总量

众所周知,DAU是每天的活跃用户数。如上图这个例子,“我的App有105,000的DAU,同比增长5%。”这是第一层的看法。
这种看用户的方式是在移动互联网中最普遍的,也是一种最通用的语言。但这有个问题,即:这种看DAU的方式,没办法细分和拆解原因,并没有办法把数据落到实际的工作上。
为什么呢?因为DAU增长、下降都可能有很多原因构成。你看到DAU数据,其实并没有办法来精确地把握:你的用户到底是涨了?做得好了还是不好?
2、“看到”第二层:看构成
其实第二层比第一层更好一点,第二层要看构成。
了解构成的方式,可能还是从DAU出发。我们知道DAU这个“105000”是由一部分新增,还有一部分的流失共同构成的。在这个案例里面,新增是10000,流失是5000,所以比过去的同期增长了5%。
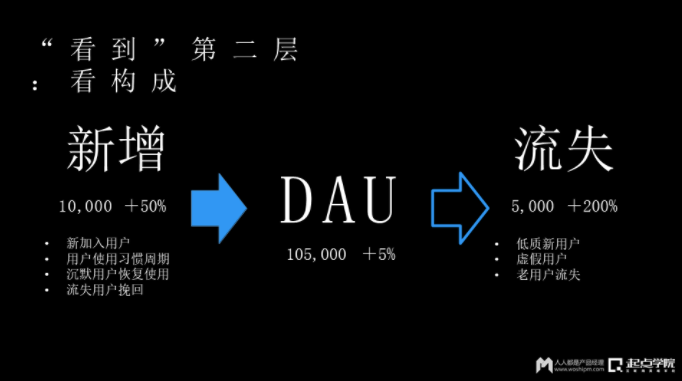
这种方式比上一个方式要好一点,因为它能看到这个流动的构成,即虽然DAU值涨了5%,但其实流失和新增是两个不同环节的要素。所以新增有很多的映射点,当我们看到新增变化的比较大,那可能跟新引入的客户,或者跟用户激活的使用率,都会有一定关系;如果流失比较高,那可能是产品粘性出了问题。
从上面这个案例可以看到,流失的增长比例会更高一些,所以流失就是主要的问题。
我们遇见过绝大部分的产品经理和开发者,基本都会看第一层(总量)和第二层(构成)。做的比较好的会从到(构成)更细致的往下看,比如:用户构成的增长和下降多少?第二层比第一层好在什么地方?
这确实可以找到一些更具体的工作点。至少我们知道是做新增,还是应该做流失。
但这也有问题,是什么呢?比如5000和105000,其实我们都不知道它们是谁。可能今天有5000的流失客户,这已经是一个固定的结果(已经流失掉了)。但想要做应用,我们希望做的是什么?是用户不流失。
其实我们大家都知道,想要这个挽回流失用户是非常困难的。但想要用户不流失,需要怎么做?你需要更早地预知这个用户未来可能会有流失风险。
新增也一样,因为我们是活跃的新增,里面很多问题是说用户的使用频次并不高,可能每个用户每周用一次App,所以我们在看DAU的时候并不好看。而这个行为是用户习惯所导致,所以这种视角来看构成的方法,其实并没办法找到是什么原因来影响了这些事。
接下来我们要说第三层,应该怎么来看用户?
3、“看到”第三层:看行为
第三层,我们就要看行为。这里其实有一个非常明显的概念,大家需要注意:第三层当中,我们本质上并不是在看用户,而是用户怎么看我们,我们需要把每一个用户单独拎出来。
比如上图的这个例子,用户是怎么来看这个App呢?
用户A:每天都在使用,所以对他而言,这就是一个高频次的应用;
用户B:只有在部分的时间里面有所启动;
用户C:几乎都没有启动过。
所以第三层,我们要看行为。从行为方式来识别我们的用户,到底用户是怎么来看这个App应用的。当我们找到这层之后,比前两层的好处是什么样呢?
其实,我们可以真正地找到答案:
第一,到底是谁?A、B还是C,哪一个用户对我们是有更高价值或者更忠诚。
第二,可以根据行为路径做未来预测和预知的。所以,我们可能发现这个客户之前经常使用的应用,后续慢慢不再用了。原来每天都用,后来变成每周用一次,这就是一些流失风险的征兆。
所以第三层要看行为,或者说是看用户怎么看我们的App。只有通过这样的方式才能真正地识别我们的App,从而回答一开头的问题,到底有多少用户?
用户A是我们的用户吗?大家可能觉得是。
用户B是吗?毕竟还启动一次。可能是。
用户C是不是?就不好说了。它可能是流失的,可能只是因为用的频次比较低。
在这里面,我们至少能知道每一个用户到底是什么样子,所以可以看到有高频用户,有普通用户,可能还要流失沉默或者一些准流失的用户。
回归用户,是在后移动互联网时代里面,每一个应用、每一个产品经理或者运营人都需要考虑的问题,即:用户到底怎么来看我们?
所以现在跟大家聊具体的方式,即怎么来找到自己的这个用户增长之路。
如何找到用户增长之路?
其实简单说,就三步:
第一个叫看见;
第二个叫读懂;
第三个叫放大。
接下来我们挨个跟大家说一说,首先是看见:
1、看见:识别用户价值
看见,看的是什么?我们看的是用户价值。如果想看清用户价值,就涉及到两个问题:
问题1 :怎么来度量用户的价值?
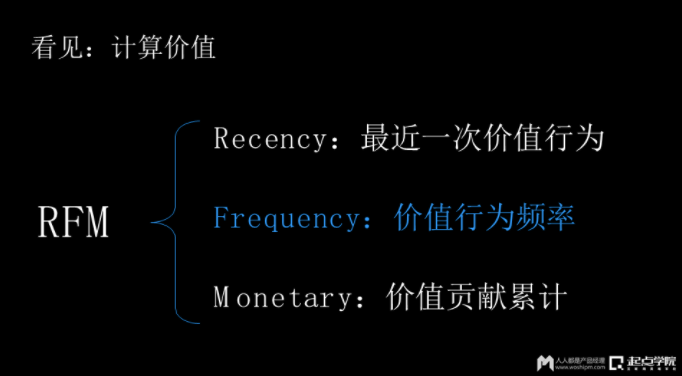
RFM模型是用来度量用户价值的一种比较常见方式。它由三个因素构成:
第一个是最近一次价值行为,当然价值是什么?可能你就要来定。
第二个是价值行为的频率,比如说刚才看的前面一个例子,如果我们认为用户启动对我们来说有很高的价值,那它的启动频率就是我们在评论当中所衡量。
第三个是价值的累积贡献度。如果在刚才的例子里面,就是用户累计启动过你的App多少次。它在这里面,我们中间这条频率标蓝了。为什么?我要跟大家特别强调一点,移动互联网的圈子或者产品,特别重要的就是频率,这也是后移动互联网一种典型的特征。
为什么这么说?我们知道RFM模型在传统行业中也会被用来衡量用户价值的。但后移动互联网的特点是什么?就是用户的耐心很差。我们没有办法通过用户上一次、最近一次启动,或者曾经用过多少次来判断它会不会被别人抢走。
后移动互联网的时代特点,就是你今天可能还很受这个用户的重视,很受他的欢迎;但是转过头之后,他看到一个新的由竞争者做得比你可能在某一方面好一点点,立刻就转头了。
所以价值行为的频率是在移动互联网里面特别重要的一个因子,需要在每一部分当中都有所衡量。而计算价值的方式,就是这个RFM模型。
问题2:什么样的环节是我们度量的价值?
这涉及到一个价值环节的问题。其实所有的App应用当中这个价值,主要就分为三大类:启动、浸入、转化。
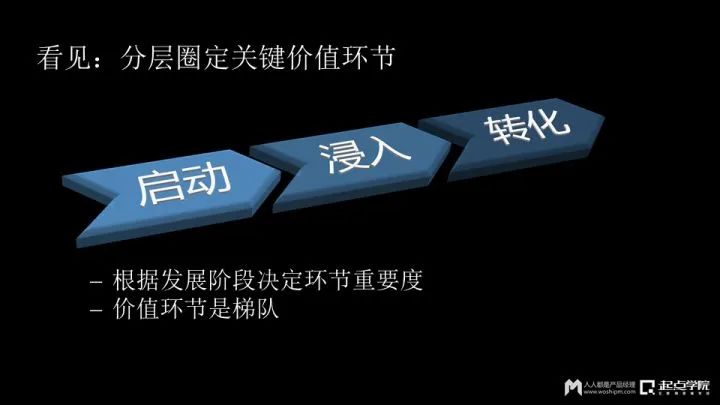
第一类最简单的,叫启动。
启动是每一个用户都会对App产生的一种价值定义,而会自启动,就对你的App有一个价值。
为什么说有价值呢?简单说,你的估值其实就跟这个有关系。比如DAU有多少;这个企业卖多少钱……都是跟这个有关的。所以,启动是第一层价值。
但是,启动并不能标识这个用户对你的真正价值贡献和粘性。所以,启动往往是衡量比较初级、相对表层一点的方式,而且它很重要。
第二点的方式叫浸入,即我的用户跟我的实际交互粘性有多高。
举个例子,比如说一个做电商的APP,它的交互粘性是什么?就是这个用户在你的APP上多元逛街。我们知道购买这件事是需要大量的逛街行为之后才做出购买决策,如果没有逛的行为,那肯定没有买的行为。所以“浸入”这一点就是指的交互粘性,它并不一定是最终给你产生价值。比如说交钱,交会费,买商品,是这些行为之前的前置步骤。
第三个是转化过程。转化过程比较简单,其实指的就是刚才说的,我们会有一个付款的过程,可能是变成会员,或者是电商里面购买的行为。
但这个价值环节有两个非常重要的点:
需要根据你的商业模式来决定到底哪个是你的价值环节。它的发展,决定哪一个环节是你现在阶段里面最重要的价值因素。如果你是一个初创型的公司,或者你可能是一些第三方付费的这种商业模式的公司,那可能前两者就非常重要,即启动和进入环节;但如果你是已经相对偏成熟一点了,有自己的变现能力,你是C端付费的这种商业模式,那最后转化和侵入环节就可能会更重要一些。
不论你发展到什么阶段,这三者都对你是有价值的。所以它的价值环节并不是一个取舍,是一个价值梯队,可能这个价值更高一点,用这种方式价值衡量会更贴近业务结果一点,但另外两者也非常重要。
2、读懂:锚定业务关键
在这里主要介绍三个计算模型:细分、漏斗、留存。
很多人都听过这三个计算模型,但是对这三个模型的理解却不一样。
(1)科学设定事件、属性将数据结构化
在中国互联网市场里,对事件进行埋点,通过事件细分去做分析,这个事情其实是非常痛苦的。在国内有两句话非常简便可以总结埋点:流程结构分事件;业务结构分属性。
第一,流程结构分事件。比如把浏览商品页,点击商品,购买设定一个事件,那么:点击儿童服装、儿童玩具都要分事件吗?并不是!我们现在绝大部分的埋点都是把所有行为都埋成一个点击事件,但分析起来头就大了。流程结构分事件,比如:电商场景,通过浏览,注册,加购,购买是你的业务流程,在业务流程中的关键点就必须要分事件。
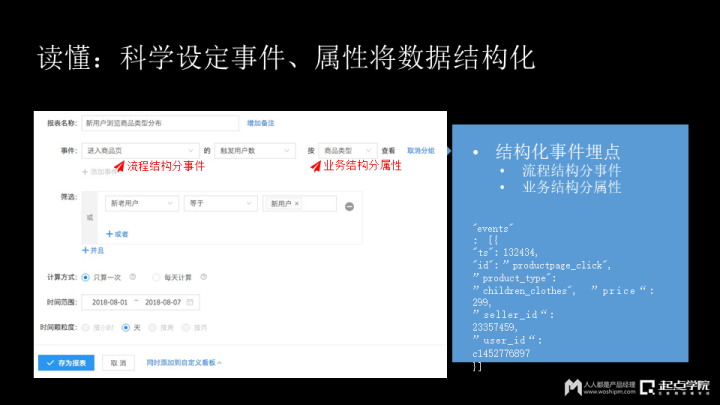
第二,业务结构分属性。这里继续用儿童电商举例,购买玩具,购买服装、购买食品及尿布……这些是儿童电商的业务结构,会分为不同的业务组。代理公司是一组人,运营是另一组人。这种业务结构要分属性,你可以将购买都设定为一个事件。买玩具,带一个属性叫玩具,买服装,带一个属性叫服装。
下面举个例子,你可以看到一个token,他的业务结构是童装,下面带有价格,有购买者和销售者,这个事件传回来,就可以进行结构化分析。

(2)巧用留存挖掘业务潜力
本质上,用户留存是衡量的一个时间序列。比如我们平时说的留存是在七天之前访问的用户,在七天之后是否还有启动,这是比较标准的留存。
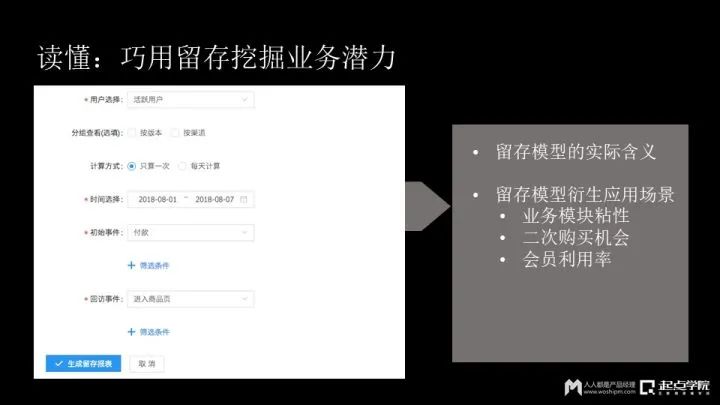
自定义留存,我通过以下案例来阐述:
案例1:他想看看用户在购买商品后,后续还会不会再次购买?会不会有商品浏览行为?所以他就选了回访事件进入产品页。买完东西之后,后续第一天、第三天、第七天用户到底还会不会在浏览商品?通过这种方式将用户圈出来,可以培养有价值的用户。
案例2:除了第二次购买之外,还可以通过其他指标衡量业务模块的粘性。比如通过衡量会员利用率的黏性。用户购买了会员之后,后续会不会真的收听这个课程,这个是对会员粘性和再次续费可能性进行标识。
(3)结合业务现状科学定义漏斗
如何理解漏斗?
第一,漏斗是多入口下的序列监测。
我们有个客户想通过漏斗分析页面,他分析的场景是通过App进入后,会弹出促销商品的页面从而才可以进行购买。他设定漏斗的三步分别为:进入App→点击促销页→点击购买。
这样的漏斗有没有必要?答案是:没有必要!用户只能通过唯一一条路径进行购买,所以只要看这三个不同事件的点击量就可以了,完全不需要设定漏斗。
漏斗是用在入口很多的地方,比如:你有很多渠道和路径完成的购买,可能从A渠道、B渠道、C渠道购买,只有在来源路径很多的时候,漏斗才有价值和作用。
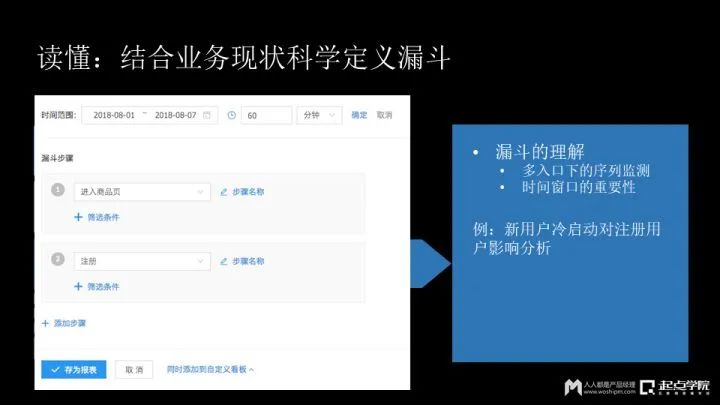
第二,时间窗口的重要性。时间窗口指的是完成漏斗的周期,比如通过漏斗查看在一个月里完成浏览商品、加购、购买的用户是谁?这种分析方式有很大的问题,因为这三个行为,中间可能隔了好几十天,漏斗必须要设定一个周期,也就是在一定时间范围:五分钟、十分钟、一个小时、一天都可以,这时候通过漏斗的分析,才是有意义的。
这里我再举个例子,还是刚才那个客户,他做了一个个性化推荐算法,引入了外部数据,完成了用户的冷启动,来看一看这个冷启动的效果,来验证用户是不是对推荐的内容满意?所以他使用的漏斗有两步:
- 进入商品页。因为之前新用户直接进来是不需要注册,可以直接点击进入到产品页,然后查看产品页面推荐内容;
- 浏览的商品之后完成后面注册。同时他设置了一个时间周期为60分钟,如果他浏览了很多产品和页面,进行了注册,这就和冷启动没有转什么直接关系,也有与广告投放有关。
3、放大:设计增长引擎
放大,其实就是通过复制用户→复制路径→复制习惯这三件事入手。
复制用户,在引流时基于对超级用户画像分析,了解超级用户的特征,同时圈选出与超级用户相似的人群,在外部进行人群圈选投放,通过新用户来检验效果。
复制路径,通过超级用户对关键行为进行漏斗分析,了解他们的转化路径和关键行为;同时通过路径分析调整产品引导,通过App推送或者应用外拉动,通过A/B test来查看哪一个的路径转化更有效。
复制习惯,分析模型一般用的是留存和细分,留存是表示的是用户习惯,通过分析超级用户的习惯。比如:超级用户对什么活动有兴趣,从而培养用户的习惯,最终你会通过消息推送和引导客户进入产品页之后,把那些并不是超级用户的用户培养成超级用户。
来自:
更多阅读:
