
当Hadoop进入企业,必须面对一个问题,那就是怎样解决和应对传统并成熟的IT信息架构。业内部,如何处理原有的结构化数据是企业进入大数据领域所面对的难题。
当Hadoop进入企业,必须面对一个问题,那就是怎样解决和应对传统并成熟的IT信息架构。以往MapReduce主要用来解决日志文件分析、互联网点击流、互联网索引、机器学习、金融分析、科学模拟、影像存储、矩阵计算等非结构化数据。但在企业内部,如何处理原有的结构化数据是企业进入大数据领域所面对的难题。企业需要既能处理非结构化数据,又能处理结构化数据的大数据技术。
在大数据时代,Hadoop主要用来处理非结构化数据,而如何处理传统IOE架构的结构化数据则成为企业面临的一个难题。在此背景下,既能处理结构化数据又能处理非结构化数据的SQL on Hadoop应运而生。
SQL on Hadoop是2013年最热门的话题,它由Cloudera Impala的发布版推到热议。目前,SQL on Hadoop正处于起步阶段,其技术实践方式很多样。而企业由于已经适应了在小数据上的灵活处理方式,转到Hadoop一下子变得无所适从,所以对SQL on Hadoop的呼声越来越大。SQL on Hadoop既要保证Hadoop性能,又要保证SQL的灵活性。关于SQL on Hadoop,业界有不同的看法,业内专业大数据公司也在积极的研究。
1.传统方式的DB on TOP
一些北美厂商采用传统方式的DB on TOP来解决SQL on Hadoop,即组合利用不同的计算框架面向不同的数据操作。其中以EMC Greenplum、Hadapt、Citus Data为代表。Hadapt以PostgreSQL架接在Hadoop上,来完成对结构化数据的查询。它提供了统一的数据处理环境,利用Hadoop的高扩展性和关系数据库的高速性,分开执行Hadoop和关系数据库之间的查询。Citus Data通过把多种数据类型转化成数据库的原生类型,运用分布式处理技术来完成查询。
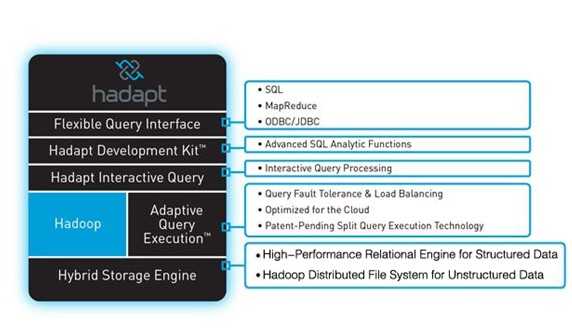
图1、Hadapt
DB on Top 方式是业内同事解决结构化与非结构化数据的最初尝试,最早由Hadapt公司在2010年提出,也就绪了能够跑在Amazon EMR上的社区版。但是,其本质是数据在两种计算框架中分别存放,如图1所示,结构化数据存储于高性能关系型数据引擎(High-Performance Relational Engine for Structured Data),非结构化数据存储于Hadoop分布文件系统(Hadoop Distributed File System for Unstructured Data),对两种类型的数据交互依靠查询的切片执行,元数据的组织控制必然是系统扩展演变中的过度技术。
2.原生态Hive的优化
在开源社区方面,以Hortonworks的Stinger、Apache Drill为例。Hortonworks的Stinger通过对原生态Hive做改造,优化SQL查询速度,使其达到5-30秒,完成对SQL查询。Apache Drill通过对原生态的Hive做优化,完成对SQL的查询。

图2、Hortonworks Stinger
开源社区原生态的改造,目标是建立共同的计算框架和接口,目前各个开源项目虽然还只是孵化阶段,也还是获得了业内的支持,例如Apache的Drill项目,因开放的数据格式和查询语言,就获得了专业的Hadoop商业发行版供应商MapR的支持。
开源社区的发展和贡献,将成为推动SQL on Hadoop大规模落地行业的主要力量。
3.人机流程交互
在国内,对于SQL on Hadoop,主要是从SQL的数据处理流程和即席分析两方面来进行。在SQL的数据处理流程方面,很多操作是可以通过对数据处理流程进行预定义,然后对MapReduce作业进行批处理。例如ETL流程处理。ETL流程处理是对数据进行抽取、清洗、转换、加载的阶段。在此阶段,通过对数据流程进行预定义,在一个人机交互的友好界面上把MapReduce作业预先组装好,进行拖拽等操作形成工作流,来解决传统的SQL。
4.多级索引结构的即席查询
大数据的即席查询是大数据所面临的一个难题。在PB级别的数据,其查询效率和查询性能都不尽如意。在传统DW环境下,企业多采用OLAP cube。OLAP cube通过对数据进行预处理,将数据根据维度进行最大限度的聚类运算,通过对维度的配置,可以完成对小数据即席分析。但是对于PB级别的大数据环境,如何建立大数据的cube来兼顾前端应用的灵活性和查询效率呢? HBase自带的哈希快速定位功能可以实现即席查询的毫秒级响应和高并发。天云大数据通过在HBase上构建多级索引以及引用MPP方式基于统计分析的分区设计,不仅解决了HBase查询不灵活的特点,还能满足对PB级别大数据的即席查询。
5.操作型SQL on Hadoop
对于操作型Hadoop,其对SQL on Hadoop 数据查询、响应等已经由存储磁盘级转移到内存上。由于其分布内存一致性要求,使得其发展比较缓慢,目前还不能达到企业应用级别。目前,分布式内存计算已渐趋繁荣,比较有代表的技术先锋如Splice Machine、SQLstream等。目前对于操作型Hadoop,业界正在积极探索中。
面对企业多年运营所积累的大量结构化数据,SQL on Hadoop无疑成为了分布式计算框架进入企业传统计算市场的敲门砖,但我们更清楚的认识到,Hadoop等主流分布式计算的舞台远不如此,它为企业计算定义了一个更为广阔的零消费市场(White Space)解决SQL之外的计算。
纷繁复杂的世界不可能简单地由平面展开的表结构来描述,SQL能够胜任查询和数值计算工作。但大量碎片的文字信息、影像图片如何计算?“买入”+“大涨”等于什么?“女性”+“Dior”等于“优雅”还是“性感”?能否用Sum、Group By、Join SQL来做非结构化信息的主题缩略、分类、聚类,我们将在后续文章中探讨这些话题。
更多阅读:

评论已关闭