
DI是什么?DI与你我有着怎样的联系?5月23日,在2017UBDC的主旨演讲中,【友盟+】首席数据官李丹枫从解析DI开始,将我们带入一个由数据智能驱动的全新世界。

(图为【友盟+】首席数据官李丹枫)
以下为演讲实录:
去年UBDC大会的主题是“无数据,不智能”,经过一年多的努力,今年我们对数据和智能的关系有了更明确的定义,即数据驱动智能。这里面包括最重要的两个词,一个是数据、一个是智能,当然我们谈到智能就不得不谈在风口浪尖的一个词“人工智能”,人工智能是什么呢?作为一个理工男,下面讲述的就是我心中的人工智能,今天的人工智能。
首先对学文的同学表示歉意,我一大早上不是要杀死你一亿脑细胞。为什么把这个式子放在这儿呢?它特别好地表达了今天人工智能做的绝大多数的事情,接下来我具体解释一下。

这里面有很多参数,第一个参数是M,就是我们所说的模型,简单来说,工业界40多年开始用模型,今天叫深度学习。这个模型包含有一些参数,有一些无参数的模型(大部分模型现在是有参数的),我选好这个模型,要去找到这一系列的参数来帮助我解决这个问题,我怎么去找这个参数呢?我有输入,有一堆的训练数据,输入包括有输出,有输入、输出,输入和输出定义好了,我就说你去学吧。就像训练小狗一样,我们教它一些东西,给它一些反馈,这个反馈就告诉你,你做的事情是对的还是错的,模型也是一样。
当然,训练模型没有那么简单,如果这么简单就不需要我们科学家了,所以我们训练模型的时候有很多技巧。第一个技巧,我们要定义损失函数,因为模型推算出一个东西不可能是完全正确的,总是跟实际的差一点点,怎么衡量这个差别呢?由损失函数来决定,比如说大家用最小的方差,很多场景里头我们会加一些权重,这就是损失函数。
还有一个叫惩罚函数,这个模型我们对它的参数是有一定限制的,不能任这个参数想怎么着就怎么着,比如说有些参数值特别特别大,一般来说是不太好的模型,所以我们要给他一些惩罚,你训练的时候要注意这些参数不要太大,这些合起来呢?这儿还有一个i,是样本数,一个两个样本我训练不了,现在的样本上万、上十万、上百万、上千万或者上亿,模型越多训练的效果越好,把这个加在一起,定义了损失函数、定义了惩罚函数,有了输入和输出,我让这个算法去找吧,在所有的维度里找到最佳的参数,这个就是你的模型。下面,再看一个图:
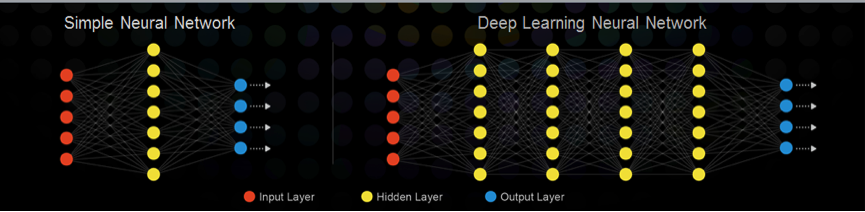
左侧这张图是一个简单的神经网络模型,是一个非常简单的身体神经网络,复杂的有几百层。我大概说一下这个模型是怎么工作的,这里面有输入节点,就是模型的X,还有藏层、输出层、神经网络工作原理非常简单。模型训练做的就是要把连线上面的权重参数找出来,有了输入、有了输出,有了数据,用训练的方法,把这些参数找出来,让模型根据我定义的损失函数达到最优。
这个是什么呢?实际上大家想想,这个就是一个暴力的计算与记忆。当然我说这个话可能有点不太公平,因为这么多数据科学家、这么多年的努力,用暴力来形容不太公平。实际上,我们有一个聪明的、暴力的计算方法,我们要搜索的权重的组合非常多,你怎么能够有效地找到它,实际上是今天大家解决问题时,运用的有效的找到参数的方法,但不管怎么说,这个模型本身是一个计算与记忆的机制。
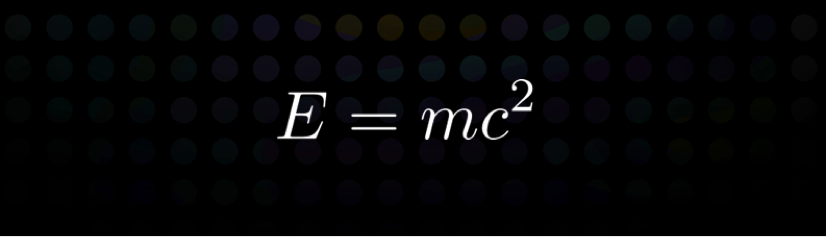
这张图是众所周知的一个公式,即爱因斯坦有名的质能方程,这个式子跟刚才的神经网络比起来弱爆了。你想想爱因斯坦用这么简单的方程涵盖了物理界这么多的现象,现在人工智能做大量的数据,用非常复杂的网络来做到对这个事情的预测,比较起来差距很大。所以现在的人工智能叫弱人工智能。
所谓弱人工智能,就是需要完整的信息、完整的定义好的输入和输出,需要借助非常强的计算与记忆的能力。我们可以想象,麦斯威尔和爱因斯坦的计算能力有多强?估计不及我们手里的手机。跟弱人工智能对应的是强人工智能,在信息不对称的情况下,考验的是大家的推理和解决问题的能力,这是我们做人工智能追求的极致的方向。
谭铁牛院士有一句话总结得非常好,“现在的人工智能是有智能没有智慧、有智商没有情商,会计算不会算计,有通才无专才”。现在很多人研究人工智能就是某一个特定的场景下训练一个模型专门为他来服务。而人的智能是什么呢?从小孩到长大思维不断成熟,这是机没法比的。因而,我们人的智能是我们追求人工智能的真正的方向。

我再回到这个公式,再重新回忆一下这些参数,第一组参数,第一个是模型,第二个是损失函数,第三个是惩罚函数,这三个是什么呢?作为人工智能数据科学家,我们天天琢磨的很多事就是给我一个问题,我选什么样的模型?我用什么样的惩罚函数,用什么样的损失函数?这就是数据科学家的缺点,好的数据科学家可能能选非常合适的模型,非常合适的损失函数与惩罚函数。不好的可能说我什么东西都用我最熟悉的模型,这个就是数据科学家的区别。
这个大部分是什么呢?实际上是计算能力,第一个是建模能力,第二个是计算能力。X跟Y这两个是数据,我们有了数据才能训练模型。对于建模能力和计算能力,实际上对于大家来说,竞争的战场是平的,你可以有很好的数据科学家,我也可以有。目前世界上有名的数据科学家可能都被几大公司招去了,你只要说有足够多的吸引力,你愿意付足够多的钱,你就能招到合适的人帮你做这件事情,计算能力更不用说了,现在计算越来越便宜、存储越来越便宜,所以计算能力大家都可以有,没什么太高的门槛。
最大的门槛是什么呢?是数据,因为没有数据,模型就是我PPT上列的这个公式,有了数据你才能把这个模型的参数找到,所以数据是最大的竞争壁垒。一个是你有数据,你有很多很好、很高质量的数据,另外一个是你对数据的理解。这是你和竞争对手区分的最大壁垒。
我前几天看到极客的创始人张鹏写了一篇文章,他说:“数据是AI的血液,一个滚滚流动的商业实践带来的数据,有时候比一个天才的科学家,或者一个领先的算法对于AI的意义更大。”与我的理解不谋而合。
我绕了这么多,讲了这么多,这个令人头疼的公式放了两遍,我要说明的问题是什么呢?数据是驱动智能非常重要的因素,也是竞争的壁垒。大家要重视数据,因为有了数据,才能做更多的事情。
下面我举三个例子,大家应该不会陌生,第一个:谷歌。谷歌有7个叫10亿用户俱乐部,这个产品有10亿人,包括什么呢?谷歌的搜索、Gmail、地图、U2、安卓、Google play,他有这么多数据就可以做好的搜索和广告。
第二个:淘宝。淘宝有4亿多深度用户,不是说一般的用户,我在这儿买一次两次东西,而是经常买。比如,我太太就是一个深度用户,天天在淘宝上淘。所以依据淘宝数据数据所做的推送,能够做到我们所说的千人千面,每个人打开淘宝看见的东西都不一样,它能够给你推荐最适合你的产品。
第三个:今日头条。用户规模大,用户平均使用时长76分钟,使用深度非常深入,所以今日头条可以做到非常好的内容智能分发。
这三个公司就是因为有了规模可观的数据、有了别人没有的这么大量级的数据,才能做到跟别人非常大的不同。当然了,你说这些公司他们已经积累了这么多,作为我,我有一个企业,我很多问题,因为我不是他,我没有这么多数据,没有这么多的技术力量,怎么办?如何搜集数据?怎么分析?数据分了各个业务线如何打通?数据单一如何地全面了解客户?AI大数据的概念不错,怎么来解决我们的痛点问题?在目前新一轮技术革命中,怎么样才能保证核心竞争力?怎么办?没关系,看一个超人飞过来,上面带着一个【友盟+】的LOGO。
【友盟+】的使命是创造你的数据价值,因为我们有这么多数据,有这么多经验,我们希望拿出我们的数据、拿出我们的经验帮助大家把这个事情做好。
我们的数据包括哪些类别呢?首先在移动端有125万个APP、680万个网站用我们的数据服务,我们每天可以搜集到数据的设备是14亿。14亿什么概念?中国网民大概是7亿多,当然一个人有多个设备。所以【友盟+】基本上是覆盖了全网用户。我们每天处理280亿的数据量。在基础数据之上,我们有完整的数据业务线,今年有三个主打的产品,第一个U-Dplus是进行数据采集和决策的,可以把数据整个链路闭环都能覆盖上;第二个是U-ADplus,广告效果数据服务,不只是监测效果,投前、投中、投后的整个数据服务;第三个是U-Oplus,是我们基于智能感知,用数据驱动的线下数据服务平台,帮助线下的商家在数据革命、智能革命的浪潮中保持不败。在这三个大的产品背后,是U-DIP数据智能平台,我们的很多数据分析、数据处理、预测、智能应用都是U-DIP大牛实现的。用我们的数据+服务的同时,会和阿里云一起合作来提供服务,帮助大家解决生产和经营中的问题,能够让你利用好你的数据,能够让你出去再说的时候我们也用数据,我们也做AI,我们也用数据和AI解决我们的实际问题。
我接下来分享几个案例,展现我们【友盟+】搜集的这么多数据在各个行业的应用情况。

第一个是我们的合作伙伴融360。融360CRO是【友盟+】做的早期项目,是在中国普惠金融这么流行的情况下,借助用户行为数据所做的独到应用。因为我们的地位是非常独特的,其他人很难有这么大规模的数据。而对于普惠金融来说,金融最重要的是风险控制,风险控制最重要的是数据。我们在融360平台上推出了基于用户互联网和移动互联网行为的风险控制分。我们发现设备覆盖率是大于90%的,基本上拿来一个设备,或者用户通过一个移动设备来申请你的贷款,我们就可以找到这个设备的相关信息以及这个用户在这个设备上的行为信息,这个涉及到覆盖率,我们的数据体量非常大,覆盖率特别高。此外,效果如何呢?我们可以提高风控效果20%。20%是在业内是非常理想的效果。这个项目就充分证明了我们用我们自有的数据在一个新的领域和合作伙伴一起来探索,实现了一个小目标,今年我们会在金融领域上继续发力。

第二个合作伙伴平安科技。对于金融场景,我们跟平安合作的数据核心是什么?我们通过对人的理解,去判断哪些人有申请信用卡的倾向,哪些人有贷款的倾向,我们用这些标签跟平安一起做了测试,发现在两个场景中,我们的CTA,广告花费明显的降低,从35%下降到20%。
第三个是梨视频,项目需要主要是推荐,推荐中有一个很大的问题是冷启动,比如来了一个客户没有它的数据,有很多企业解决冷启动的算法,但再好的算法也不如我知道这个人,你把这个人的邻居拉过来,或者把他的好友拉过来说你告诉我他喜欢什么,再好的算法也比不过这些数据,因而我们用数据帮助梨视频解决冷启动的问题。
第四个是广告投放方面的案例,我们希望把整个人群定向做得更智能一些,现在很多方式是什么呢?比如分析一下你的客户群体,你的标签跟其他人的标签有什么不同?如果发现你这儿男性比例比较高,就给你投男性。这里面有很多人工因素的介入,有很多的主观判断,我们希望能让机器来做,这才叫人工智能,机器替人做事。我们要做的就是,让机器根据我们后台的大数据判断核心用户,哪些人与你的客群最相近。这样做的效果非常明显,比如我们服务闲鱼游戏后,其获客成本降低了50%。
第五个是汽车之家。汽车之家在金融领域有精准营销的服务,运用我们的数据后CTR提升了100%。
上面的分享是我们过去一年多里做的一些案例,今年【友盟+】会以更加开放的心态跟大家合作,希望大家从业务上,数据上,技术上,用数据和人工智能解决用户的痛点问题。
现在大家都说人口红利消失了,但是数据的红利已经来临,希望我们与大家一起跟发掘数据的潜力,把数据作为第一生产力。
更多阅读:
