
CentOS 的全面停更不仅是一个时代的结束,更迫使 CIO 和 IT 架构师们重新审视底层基础设施的价值。在 AI 模型爆发与全面容器化的今天,操作系统已经从简单的“承载工具”变成了影响业务敏捷性和安全合规的核心变量。面对市场上众多的 Linux 发行版,企业该如何抉择?本文将围绕交付效率、生命周期、智能运维与商业合规四大维度,对目前主流的三大路径——RHEL 10、Ubuntu Server、以及 Rocky Linux进行评估。
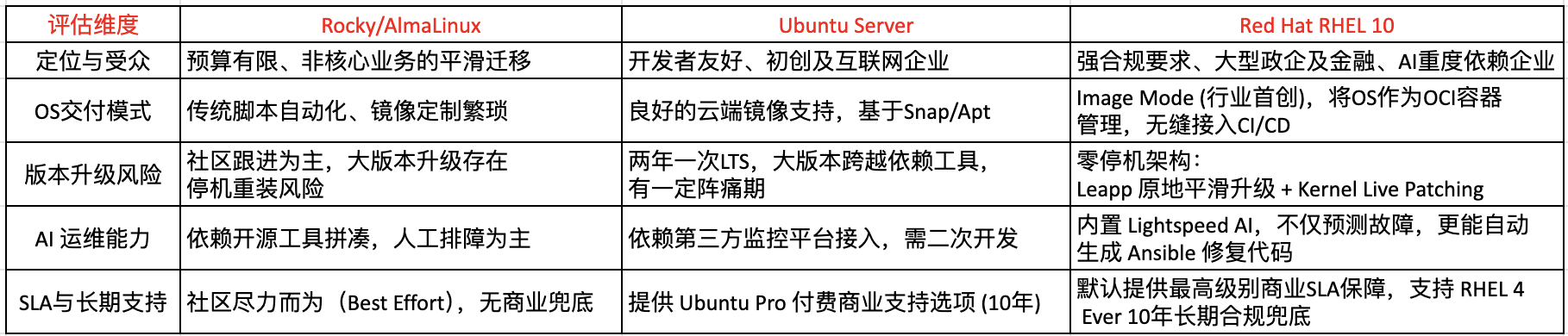
交付效率:从“手工调机”到“镜像化交付”的进化
Rocky Linux(社区替代):继承了传统 RPM 系列的运维方式,仍依赖大量 Kickstart、Ansible 脚本适配不同云环境。规模一旦扩大,“配置漂移”问题就会显现,导致环境不一致、排障成本飙升。
Ubuntu Server:在云原生与开发者生态方面优势明显,镜像丰富。但其包管理体系在多云、混合架构的统一部署场景中仍需要较多人工维护,难以做到平台级一致性。
RHEL 10镜像化交付(Image Mode),把操作系统封装成标准OCI镜像。这种方式让OS的部署方式与容器保持一致,使跨云、跨硬件环境的上线流程更可控,也减少配置漂移。对于大规模、多地域的企业环境,这类“一次构建、全域一致”的交付模式正成为新趋势。
连续性与安全:如何避免“深夜拔网线”的被动操作?
社区发行版的主要不确定性在于安全补丁时效、升级路径可控性以及缺乏SLA保证。许多企业为了避免版本升级带来的风险,往往选择停留在旧版本,让系统“带病运行”。
Ubuntu LTS与企业版Linux都具备长期维护,不过不同发行版的生命周期工具链有所差异。
部分企业级发行版在这一点上走得更远,例如:
RHEL 10生命周期管理自动化工具(如 Leapp 类工具)能在保留现有配置的前提下进行版本切换内核Live Patching可让业务在修复高危漏洞时不必重启。
这类能力在金融、电信、能源等需要 7×24 稳定运行的行业尤为重要。
AI 时代的运维压力:谁在弥补“工程师缺口”?
在容器规模快速扩大、AI 计算节点不断增长的背景下,传统运维模式正在接近极限。许多企业发现,过去依赖人工排查和脚本化处理的方式,已经很难支撑复杂的生产环境——故障定位耗时更长,系统隐患往往在出问题后才显现,导致 MTTR(平均修复时间)持续偏高。
正因如此,企业级 Linux 的发展方向正在发生变化。新一代发行版开始引入生成式 AI 辅助运维,通过自动分析日志异常、提前预测潜在风险,并在系统告警时生成可直接执行的 Ansible 修复动作,让系统能够从“被动响应”逐渐迈向“主动预防”与“自愈”。这种能力正在成为缓解高级运维工程师短缺、提升整体 IT 可靠性的关键支撑点,也成为 CIO 制定基础设施策略时的重要考量。
CIO 选型参考
在操作系统选型上,并不存在放之四海而皆准的答案。对于规模较小的边缘业务或实验性环境来说,免费的社区发行版往往已经能够覆盖基础需求,尤其在预算敏感的场景中,是一种相对务实的选择。
但当企业进入数字化与AI大规模落地的阶段,情况就变得不同。此时,系统不仅要支撑关键业务,还需要提供清晰可审计的合规链路、可控且可预期的生命周期管理、大规模部署的一致性、主动式的安全能力,以及能够协助团队应对复杂环境的AI辅助运维特性。在这些场景下,企业往往会更倾向采用具备完善能力体系的商业发行版,因为从长期来看,这类方案的稳定性、可控性和整体拥有成本往往更具优势。
更多阅读:
