

2012年5月,新浪微博设立了举报处理大厅,谣言占了不良信息中的一大部分。研究人员利用微博举报大厅公布的实时数据收集谣言信息。

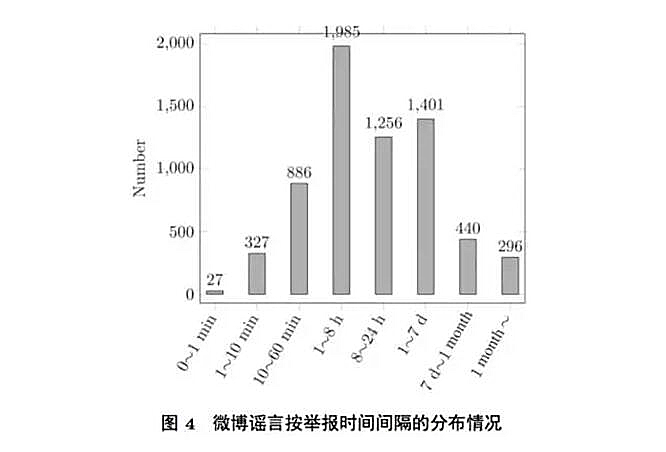
▶大部分微博谣言会在其发布的一个周内被举报并辟谣
第一,大多数微博谣言的影响力都比较小, 转发和评论数在500次以下的微博占到整体的84%。只有极少量的微博谣言具有极广的传播范围和强大的影响力 。
第二,谣言通常要传播一段时间后,才有可能遭到举报;同时, 由于传播速度快,大部分微博谣言会在其发布的一个周内被举报并辟谣 (88.9%)。
第四,大量发布谣言的用户,往往带有网络水军的性质,例如,有微博用户仅在几分钟的时间里发布了几十条微博, 其中大部分是谣言, 之后该用户就再未发过微博。
▶常识类谣言经常反复出现转发高峰
研究人员还根据谣言内容将其分成了5个分类:
•政治类谣言,例如钓鱼岛海域中日两国爆发海战;
•经济类谣言,例如三星赔偿苹果几十车硬币;
•欺诈类谣言,例如“四川藏区儿童需要御寒冬衣”,然后留下了一个虚假的联系电话;
•社会生活类谣言,社会各界人物的花边新闻,例如六小龄童去世;
•常识类谣言,例如阿司匹林能治疗心脏病。
这些谣言中,大部分属于社会生活类和政治类谣言 (约占70%)。而结合微博谣言发布、传播、高峰和消亡的过程还可以发现,不同的谣言出线转发峰值的情况也各部相同。
70%的谣言话题只有一个较大转发峰值,也就是说,被辟谣后,它们就会逐渐消亡。
另外,谣言的内容也和其转发峰值有关系:例如,常识类谣言由于受众广,辟谣难度较大,往往会反复被人们提及,出现多次爆发,约70%的常识类谣言通常有多个转发峰值。而关于名人或知名机构的谣言,由于关注人数众多,辟谣难度较小,因此发布之初就会出现较大转发峰值,但很快会被辟谣,约60%的此类谣言会在一个周内消亡。
▶人们为什么相信谣言
人们为什么会相信这些谣言呢?研究人员分析后将原因归结为两类:(1)知识受限,即缺乏专业知识而导致误信或无法辨认的谣言。例如,阿司匹林可以治疗急性心脏病;(2)时空受限谣言,即由于地域和时间限制无法辨认的谣言。例如, 有谣言称 “杭州上城区一妇女喝了3罐可乐,两天后离开了这个世界。验尸结果是她死于细螺旋体病, 发病原因是直接用嘴对可乐罐饮用”。
▶自动辟谣框架
在对谣言进行分析之后,研究人员还试图建立一个自动辟谣机制。当然,在目前的技术条件下,自然语言处理技术还无法根据微博内容自动判断其是否为谣言。所以,研究人员的思路通过语义分析,自动根据谣言主题对其进行分类,然后发现最有可能判定该谣言的专家,推荐专家对疑似谣言进行鉴别。
研究人员的框架主要包括3个阶段的工作:
1. 谣言发布早期,通过用户举报和对可疑用户的监控建立疑似谣言的集合。一方面,将疑似谣言和谣言库中进行比对;另一方面, 对于在谣言库中没有匹配内容的谣言,通过查询该领域的专家库,推荐若干专家对该疑似谣言进行鉴别。
2. 谣言发布中期,通过自然语言处理技术分析疑似谣言的评论信息,通过社会网络分析技术分析疑似谣言的传播模式,判定该信息是否为谣言。
3. 谣言发布后期,对于判定为谣言的信息, 将其加入谣言库;对信息发布人进行可信性分析,确定其信用等级,将信用等级低于一定阈值的用户加入可疑用户库,在一段时间内对其发布的微博内容进行监控;对信息举报人和评论人进行专家发现,充实和更新该信息相关的知识领域的专家库。
当然,目前这一切还处于理论研究阶段,而建立可以用户库也需要以网站更严格地执行实名制为前提。用大数据、人工智能去对付谣言,前提是需要很多人交出更多的隐私,你愿意吗?
注:以上文章引用自论文《中文社交媒体谣言统计语义分析》,更多详情请阅原文:刘知远, 张乐, 涂存超, 孙茂松. 中文社交媒体谣言统计语义分析. 中国科学 信息科学, 2015, 45(12): 1536-1546. //info.scichina.com/sciF/CN/10.1360/N112015-00243 本文摘选全球深度报道,文/蒋鸿昌。
更多阅读:
