
导语 在内容推荐系统里,一个常用的方法是通过理解内容(挖掘内容属性)去挖掘用户的兴趣点来构建推荐模型。从大多数业务的效果来看,这样的模型是有效的,也就是说用户行为与内容是相关的。不过有一点常被忽略的是:相关性是对称的!这意味着如果可以从内容属性去理解用户行为,预测用户行为,那么也可以通过理解用户行为去理解内容,预测内容属性。
相关性是对称的
在内容推荐系统里,一个常用的方法是通过理解内容(挖掘内容属性)去挖掘用户的兴趣点来构建推荐模型。从大多数业务的效果来看,这样的模型是有效的,也就是说用户行为与内容是相关的。不过有一点常被忽略的是:相关性是对称的!这意味着如果可以从内容属性去理解用户行为,预测用户行为,那么也可以通过理解用户行为去理解内容,预测内容属性。
利用行为数据生成内容向量
推荐系统里我们一直有基于用户行为去理解内容,典型的例子是基于用户行为构造内容特征,例如内容的点击率、内容的性别倾向,内容的年龄倾向等。这样的理解是浅层的,仅仅是一些简单的统计。我们其实有更好的办法可以构建内容特征,它的第一步是利用用户行为将内容转化为向量,下面会以应用宝业务为例讲解利用用户行为将app转化为向量的思路。
从直觉上来看,用户下载app的先后关系是相关的,以图1的行为数据为例,一个用户之前下载过街头篮球,那么他接下来会下载体育类app的概率会比他接下来下载时尚类app的概率更大。也就是说 P(腾讯体育|街头篮球)>P(唯品会|街头篮球)


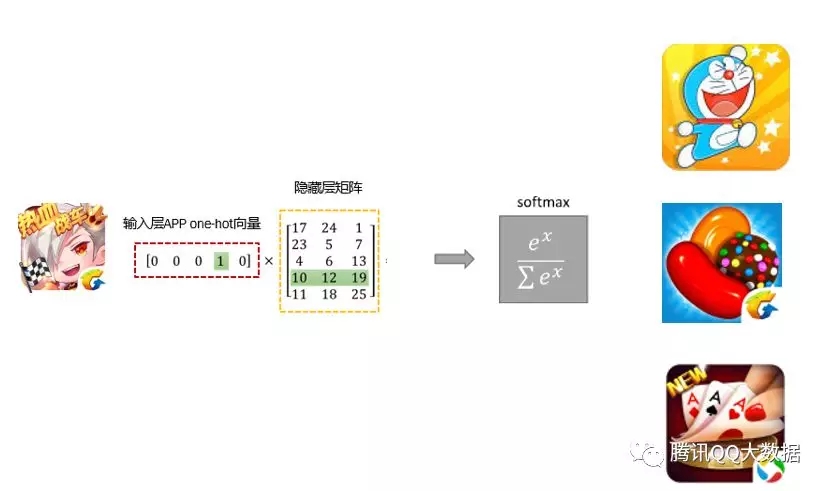
到这里我们已经大致介绍了利用用户行为将内容转化为向量的方法,这里将这种技术称作item2vec。以应用宝为例,它的item是app,它的实际应用也可以称作app2vec。
内容向量聚类
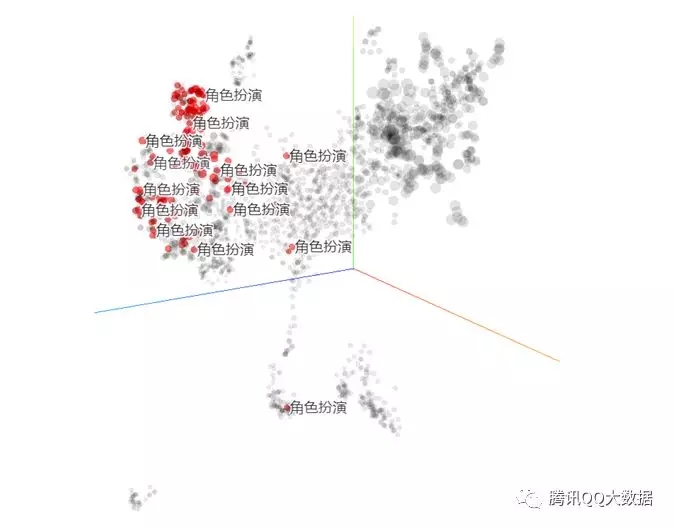
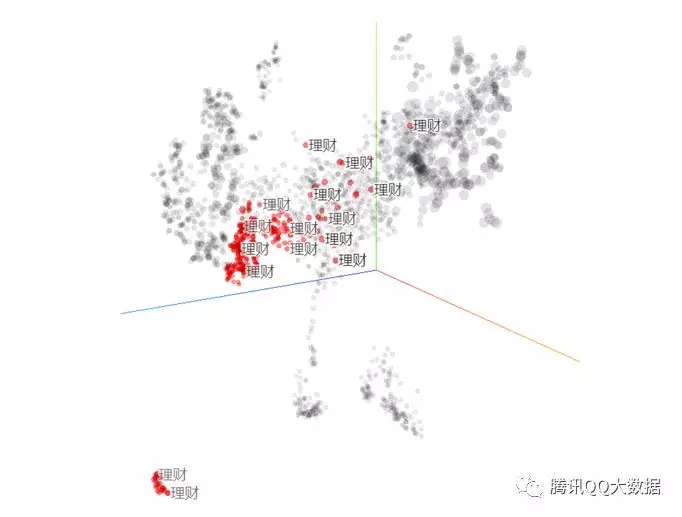
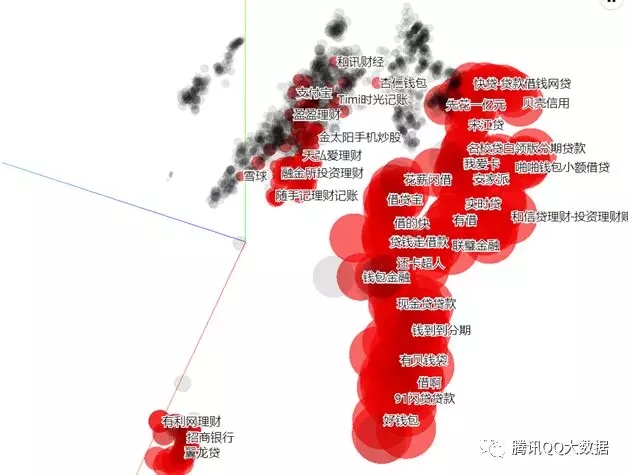
基于应用宝已有的类别体系观察,可以明显区分开角色扮演类游戏app和理财app。
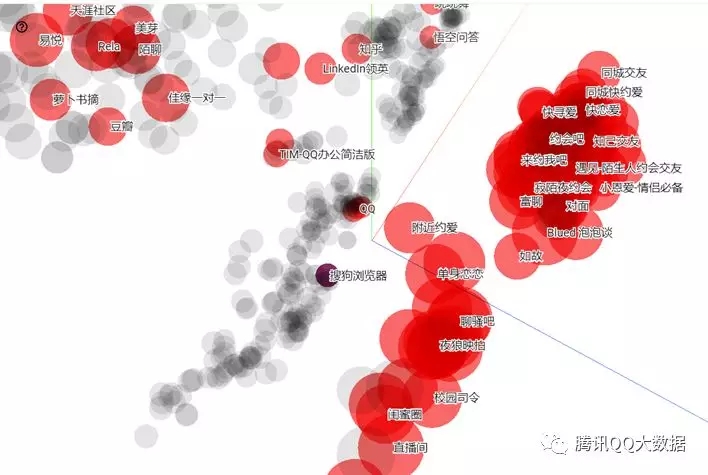
也可以发现一些没有加入类别体系的特殊app群体。
now直播业务也基于该方法进行了生成了主播向量并对主播进行了聚类,初步结果来看是聚类是可以明显区分开男女主播的,并且也发现了几个有趣的主播类型,例如直播玩王者的主播,直播电影电视剧的主播,直播农村生活的主播。
基于内容向量的分类模型
应用宝的app分类(打标签)场景长期以来都存在这样的痛点:
- 分类体系经常会面临变动
- app的人工标注成本高,复杂标签体系下app的标注数据很少
- app属于复杂数据结构的内容,它的内在难以用已有算法进行挖掘,过去只能通过它的描述和图片来挖掘其信息
这里我们可以先思考一个问题:为什么要给app做分类和打标签?
答:给app做分类和打标签实际上是为了让用户可以更方便的找到自己想要的app,为了让我们可以更容易地结合用户兴趣给用户推送app。
从问题和答案我们可以得出一个结论:给app做分类和打标签有意义的前提是用户的行为是和app的类别、标签相关的!例如下面的这个例子里,第一位用户喜欢下载纸牌类游戏,第二位用户喜欢下载跑酷类和儿童类游戏,第三位用户喜欢下载休闲类游戏。

上面的分析我们知道用户行为应该可以用于判断app的类别标签。因此在给应用宝的app进行分类和打标签时,我们引入了基于用户行为生成的app向量。具体框架可看下图:

通过增加app向量作为分类模型的特征,可以很大程度上提高app分类的准确度(可以参考聚类中的例子),在实际业务中,部分标签的分类准确率和覆盖度都有大幅度提升。
基于内容向量的推荐召回
直观的例子是相关推荐,因为这一场景通常不会对召回结果做太多的加工。常见的召回结果生成方法是先计算item与item之间的相似度(一般使用cosine相似度),再取其中的top n相似item。
在应用宝的两个场景中基于app向量做了app的推荐召回进行了测试,相对于原模型效果有明显的提升。
基于内容向量的语义召回
在app搜索场景基于行为数据生成的搜索词向量优化了语义召回,明显增强了词的模糊匹配能力。例如搜索“潮流”,出来的结果是从用户行为角度跟“潮流”相关的app,而不是单纯基于语义匹配。
或者举一个更直观的例子,吃鸡游戏出来的时候,搜索吃鸡出来的都不是吃鸡游戏。但是对此感兴趣的用户后续还是会去找到正确的搜索词,例如之后搜索“绝地求生”,或是下载了“绝地求生”,基于这些词,基于这些行为,可以将“吃鸡”和“绝地求生”关联起来。
基于内容向量的应用场景还有很多,加入我们,我们一起来玩转机器学习!
来源:腾讯QQ大数据
更多阅读:
