

来源:Yann LeCun
编译:米粒
Yann LeCun 是卷积神经网络的发明人,Facebook 人工智能研究院的负责人。下文的 150 张 PPT,是 LeCun 对深度学习领域的全面而细致的思考。LeCun 非常坚定看好无监督学习,认为无监督学习是能够提供足够信息去训练数以十亿计的神经网络的唯一学习形式。
但 LeCun 也认为,这要做好非常难,毕竟世界是不可理解的。我们来看看 LeCun 在这 150 张 PPT 中,究竟给我们带来什么样的惊喜。
如需下载全文,请在新智元订阅号回复 0326 下载。

深度学习
作者Yann Le Cun
纽约大学,柯朗数学科学学院(CourantInstitute of Mathematical Science, NYU),
Facebook 人工智能研究

我们需要复制大脑来开发智能机器吗?
大脑是智能机器存在的依据
-鸟和蝙蝠是重于空气飞行存在的依据
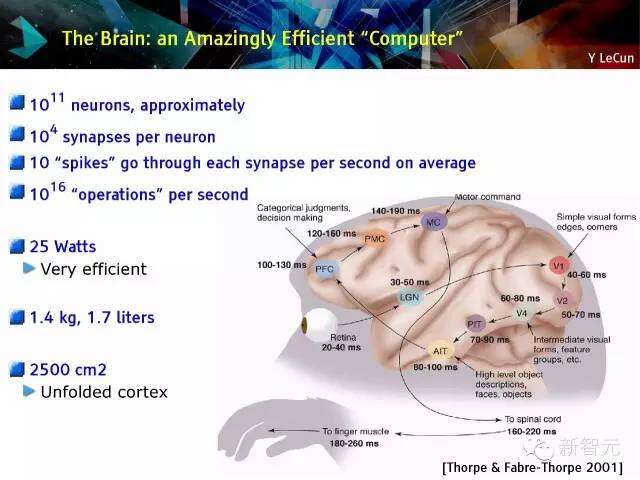
大脑

今天高速处理器

我们能够通过复制大脑来开发人工智能系统吗?
电脑离大脑运算能力只有1万次方差距吗?很有可能是100万次方:突触是复杂的。1百万次方是30年摩尔定律
最好从生物学里获取灵感;但是如果没有了解基本原理,仅从生物学里生搬硬造,注定要失败。飞机是从飞鸟那里获取的灵感;他们使用了同样的飞行基本原理;但是,飞机并不振翅飞翔,也没有羽翼。

让我们从自然里汲取灵感,但不需要依葫芦画瓢
模仿自然是好的,但是我们也需要去了解自然。对于飞机而言,我们开发了空气动力学以及可压缩流体动力学,我们知道了羽毛和振翅不是关键。
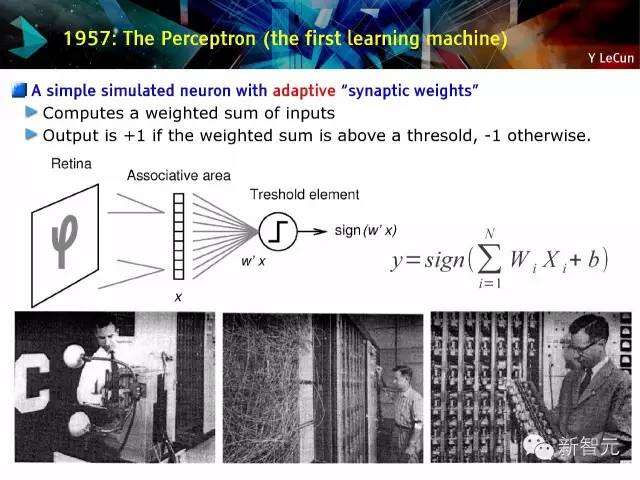
1957年:感知机(第一台学习机器)
具有适应性“突触权重”的一个简单的模拟神经元,计算输入的加权总和,如果加权总和高于阈值,则输出+1,反之则输出-1。

感知机学习算法
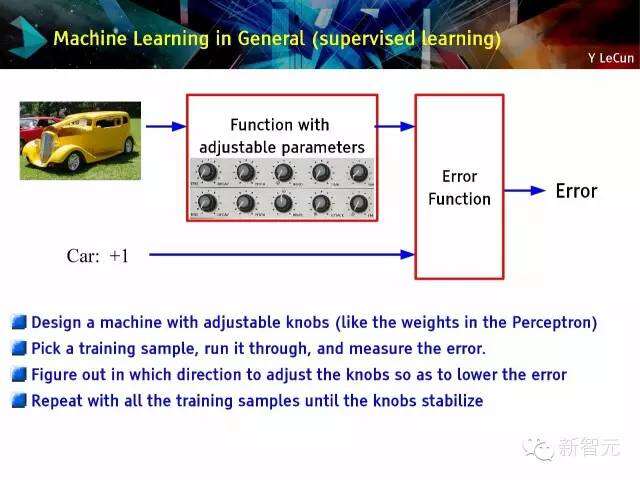
通常的机器学习(监督学习)
设计一台带有可调节旋钮的机器(与感知机里的权重类似);选取一个训练样本,经机器运行之后,测量误差;找出需要调整那个方向的旋钮以便降低误差;重复使用所有训练样本来进行操作,直到旋钮稳定下来。

通常的机器学习(监督学习)
设计一台带有可调节旋钮的机器;选取一个训练样本,经机器运行之后,测量误差;调节旋钮以便降低误差;不断重复直到旋钮稳定下来;
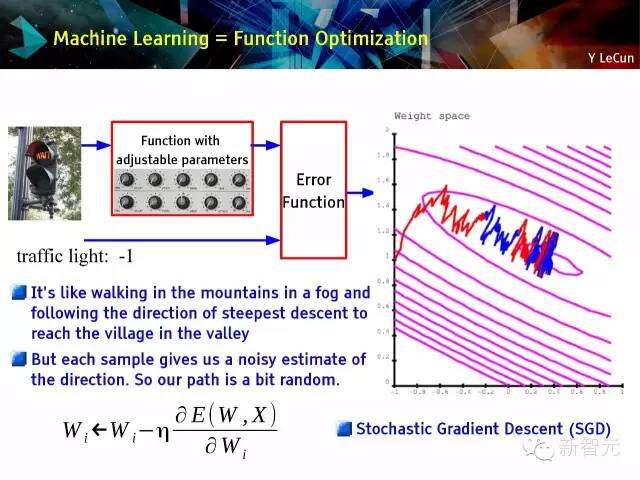
机器学习=功能优化
这就如同行走在雾气弥漫的高山之中,通过往最陡的下坡方向行走来抵达山谷中的村庄;但是每一个样本会给我们一个方向的噪声预估,因此,我们的路径是相当随机的。

泛化能力:识别训练中没有察觉到的情况
训练之后:用从未识别过的样本来测试机器;

监督学习
我们能够用诸如桌子、椅子、狗、猫及人等很多例子来训练机器;但是机器能够识别它从未看到过的桌子、椅子、狗、猫及人吗?

大规模的机器学习:现实
数以亿计的“旋钮”(或“权重”),数以千计的种类;数以百万计的样本;识别每一个样本可能需要进行数十亿的操作;但是这些操作只是一些简单的乘法和加法。
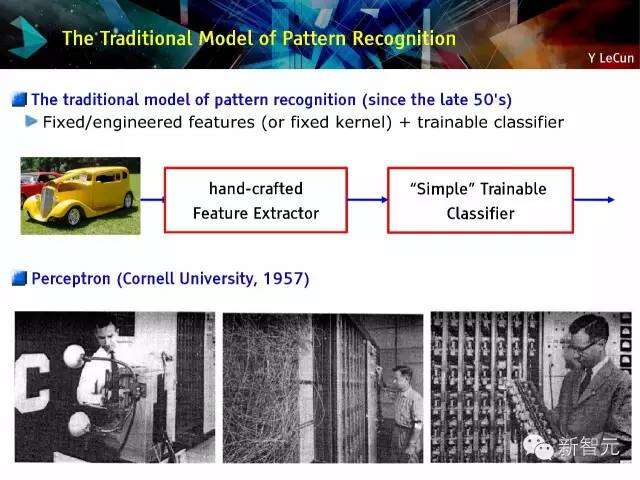
模式识别的传统模式
模式识别的传统模式(自50年代末开始),固定/设计特征(或固定矩阵)+可训练的分级器,感知机(康奈尔大学,1957年)
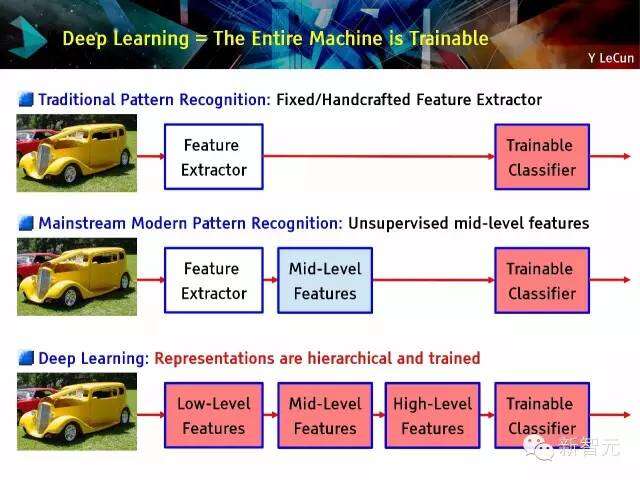
深度学习=整台机器是可以训练的
传统的模式识别:固定及手工制的特征萃取器;主流的现代化模式识别:无监督的中等级别特征;深度学习:表现形式是分等级的及训练有素的;
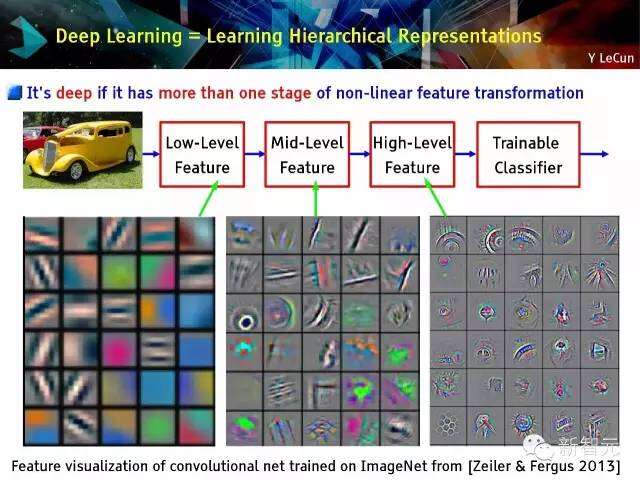
深度学习=学习分等级的表现形式
有超过一个阶段的非线性特征变换即为深度学习;在ImageNet上的特征可视化的卷积码净训练[来自蔡勒与宏泰2013(Zeiler & Fergus 2013)]
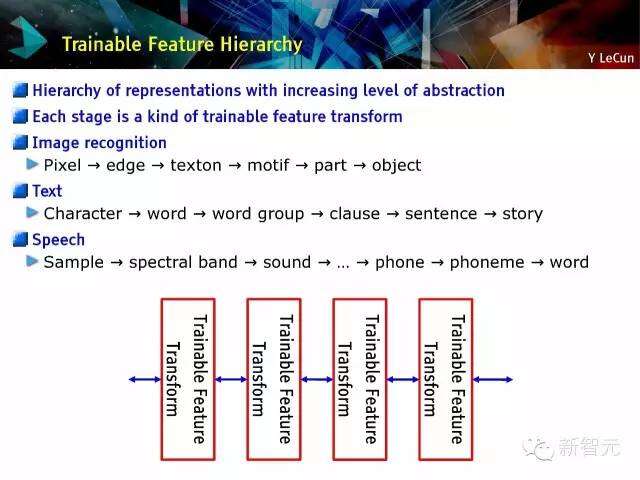
可训练的特征等级
随着抽象等级的增加,表现形式等级的增加;每一个阶段是一种可训练特征的转换;图像识别:
像素→边缘→纹理基元→主题→
部分→对象
字符→字→字组→从句→句子→故事
言语
例子→光谱段→声音→… →电话→音素→字
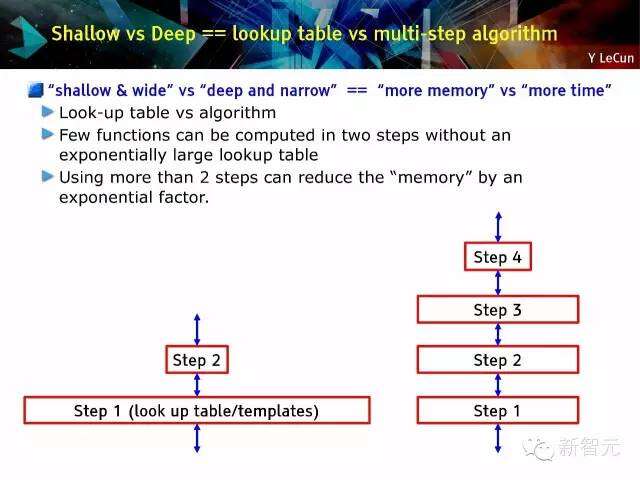
浅度vs深度==查找表VS多步算法
“浅与宽”vs“深与窄”==“更多的内存”与“更多的时间”,查找表vs 算法;如果没有一个指数大级别的查找表,几乎很少有函数可以用两步计算完成;通过指数系数,可以通过超过两步运算来减少“存储量”。
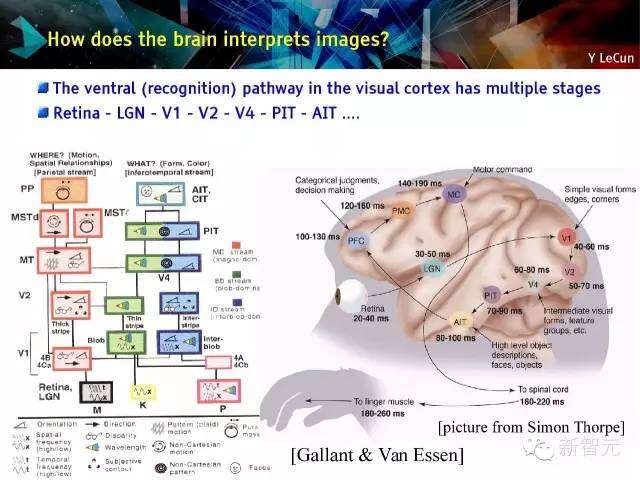
大脑如何解读图像?
在视觉皮层的腹侧(识别)通路包含多个阶段;视网膜- LGN – V1 – V2 – V4 – PIT – AIT….等等;

多层的神经网络
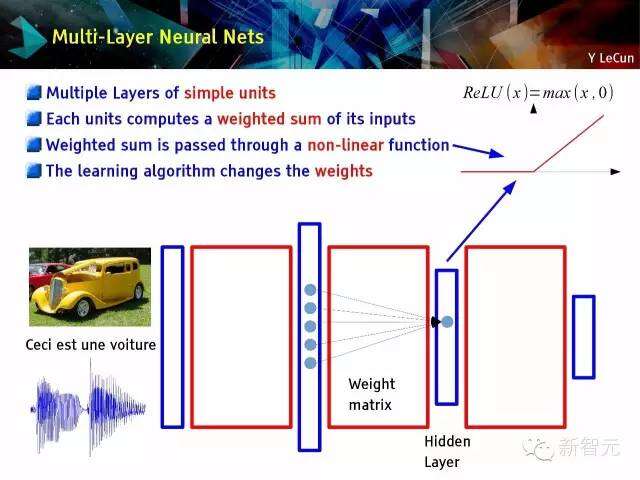
多层的神经网络
简单单位的多层级;每个单位计算一次输入的加权总和;加权总和通过一个非线性函数;学习算法改变权重;
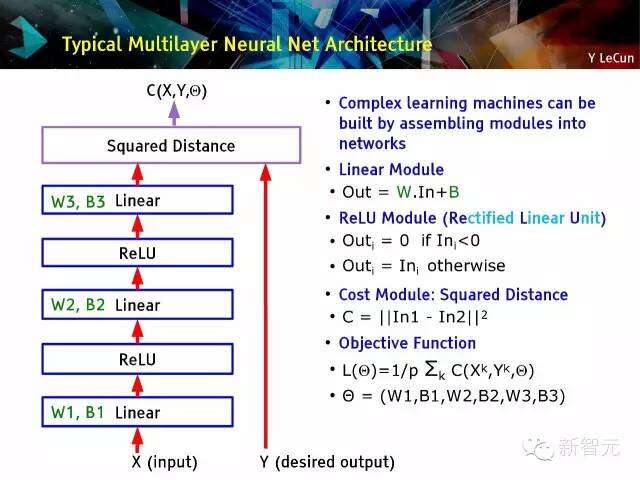
典型的多层神经网路架构
- 可以通过在网路中装配模块来发明复杂的学习机器;
- 线性模块
- 输出=W.输入+B
- ReLU 模块(经校正过的线性单元)
- 输出i=0 如果输入i<0;
- 输出i=输入,如果其他情况;
- 成本模块:平方距离
- 成本=||In1-In2||2
- 目标函数
- L(Θ)=1/pΣk C(Xk,Yk,Θ)
- Θ=(W1,B1,W2,B2,W3,B3)
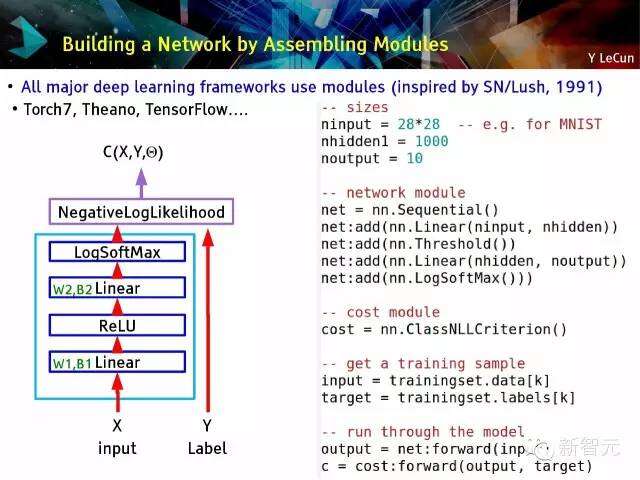
通过装配模块来搭建网路
所有主要深度学习框架使用模块(灵感源自SN/Lush, 1991),火炬7(Torch7), Theano, TensorFlow….
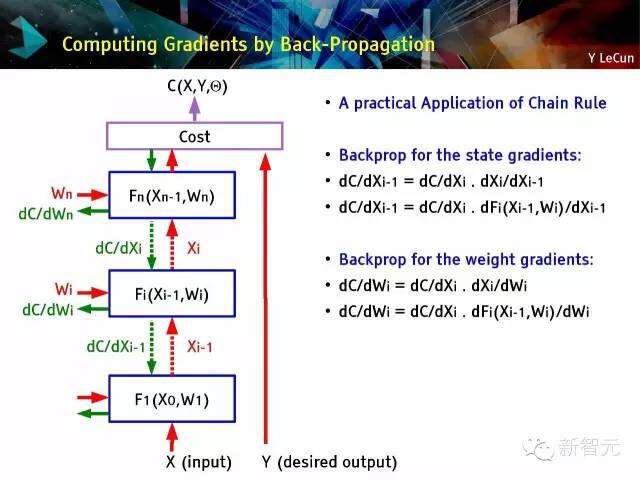
通过反向传递来计算斜率
链式法则的实际应用
推倒代数的斜率:
● dC/dXi-1 = dC/dXi . dXi/dXi-1
● dC/dXi-1 = dC/dXi . dFi(Xi-1,Wi)/dXi-1
推倒权重斜率:
● dC/dWi = dC/dXi . dXi/dWi
● dC/dWi = dC/dXi . dFi(Xi-1,Wi)/dWi
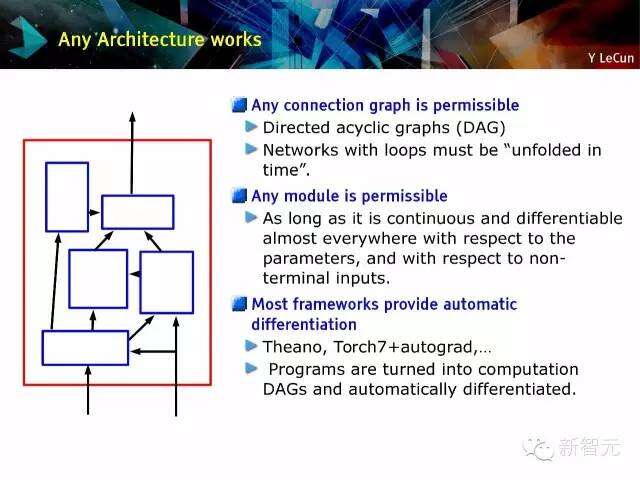
任何架构都可以工作?
允许任何的连接图;
无回路有向图
循环的网络需要“在时间上展开”
允许任何的模块
只要对于相应的参数及其他非终端输入是连续的,并且在几乎所有位置都可以进行求倒。
几乎所有的架构都提供自动求导功能;
Theano, Torch7+autograd,…
程序变成计算无回路有向图(DAGs)及自动求道
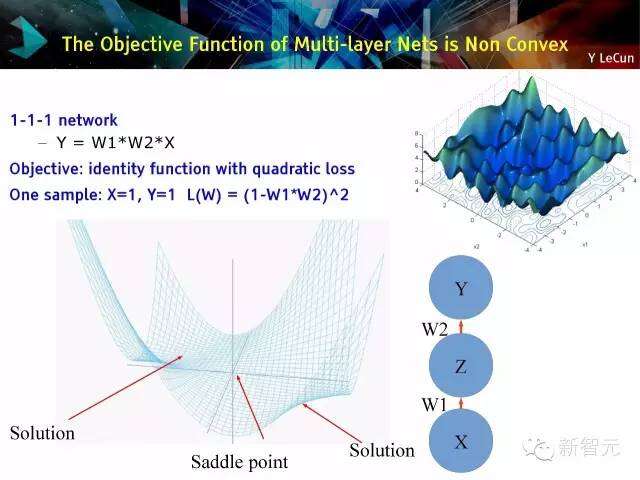
多层网络的目标函数是非凸性的。
1-1-1网络
– Y = W1*W2*X
目标函数:二次损失的恒等函数
一个例子:X=1,Y=1 L(W) = (1-W1*W2)^2

卷积网络
(简称ConvNet或 CNN)
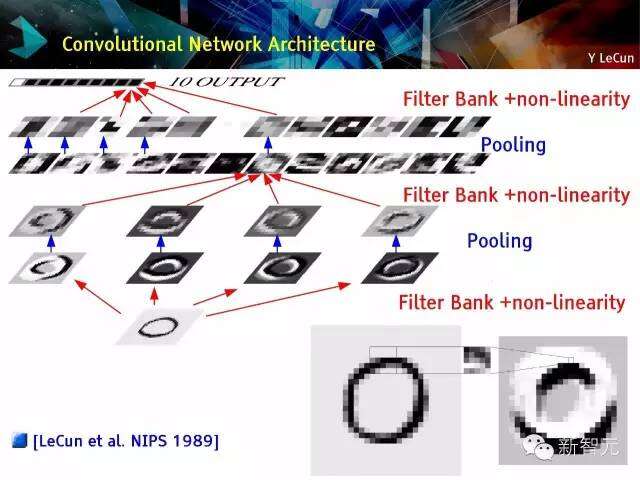
卷积网络架构

多卷积
动画:安德烈 .卡帕斯(Andrej Karpathy)网址://cs231n.github.io/convolutional-networks/
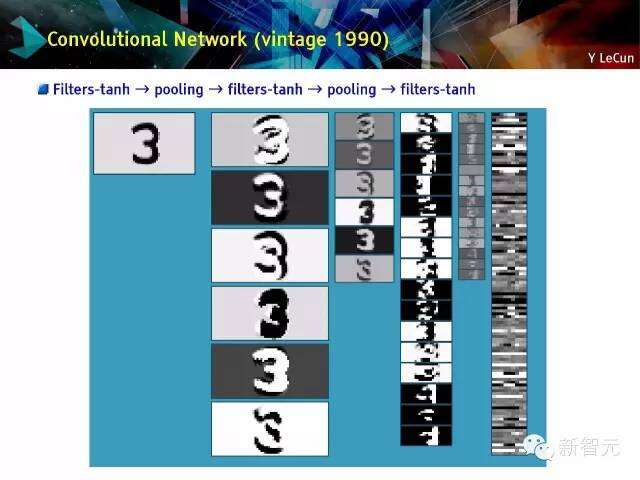
卷积性网络(制造年代:1990年)
过滤器-tanh →汇总→过滤器-tanh →汇总→过滤器-tanh
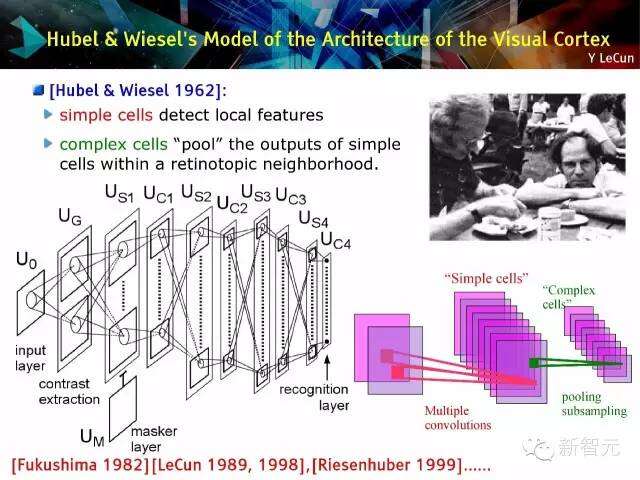
胡贝尔和威塞尔(Hubel & Wiesel)的视觉皮层结构模型
简单单元格用于检测局部特征,复杂单元格用于“汇总”位于视皮层附近的简单单元格输出产物,[福岛(Fukushima)1982年][LeCun 1989, 1998年],[Riesenhuber 1999年]等等

总体架构:多步奏标准化→过滤器集→非线性→汇总
标准化:白度变化(自由选择)
减法:平均去除率,高通过滤器
除法:局部标准化,标准方差
过滤器库:维度扩大,映射到超完备基数
非线性:稀疏化,饱和度,侧抑制机制等等
改正(ReLU),有效分量的减少,tanh,
汇总:空间或功能类别的集合

1993年LeNet1演示
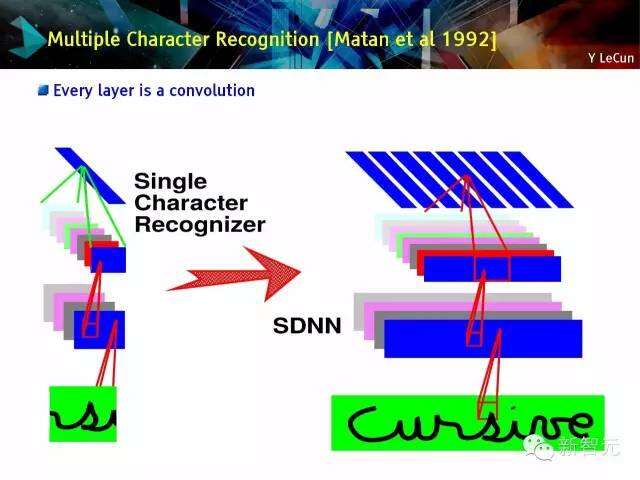
多字符识别[马坦等(Matan et al),1992年]
每一层是一个卷积

ConvNet滑动窗口+加权有限状态机

ConvNet滑动窗口+加权FSM
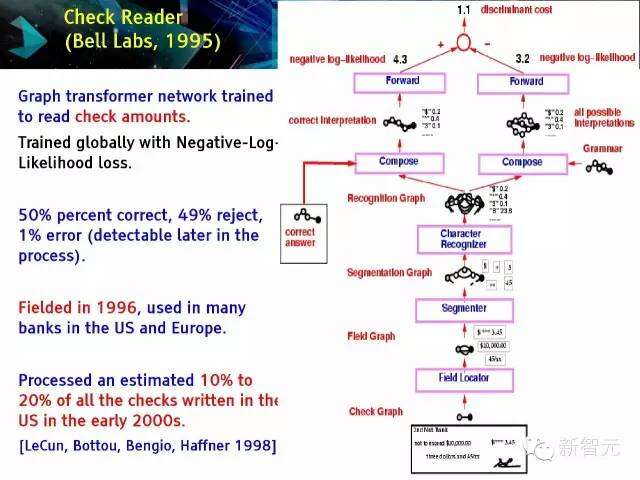
支票读取器(贝尔实验室,1995年)
图像转换器网络经训练后读取支票金额,用负对数似然损失来进行全面化训练。50%正确,49%拒绝,1%误差(在后面的过程中可以检测到)1996年开始在美国和欧洲的许多银行中使用,在2000年代初处理了美国约10%到20%的手写支票。
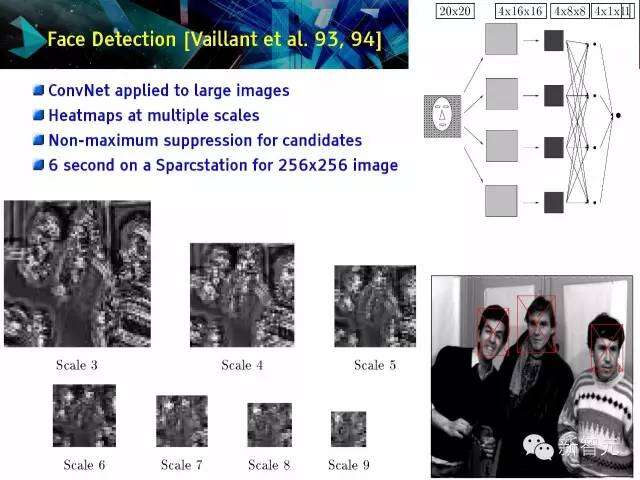
人脸检测[威能(Vaillantet al.)等。93、94年]
ConvNet被用于大图像处理,多尺寸热图,候选者非最大化抑制,对256×256 图像SPARCstation需要6秒时间

同步化人脸检测及姿态预估

卷积网络行人检测

场景解析及标注
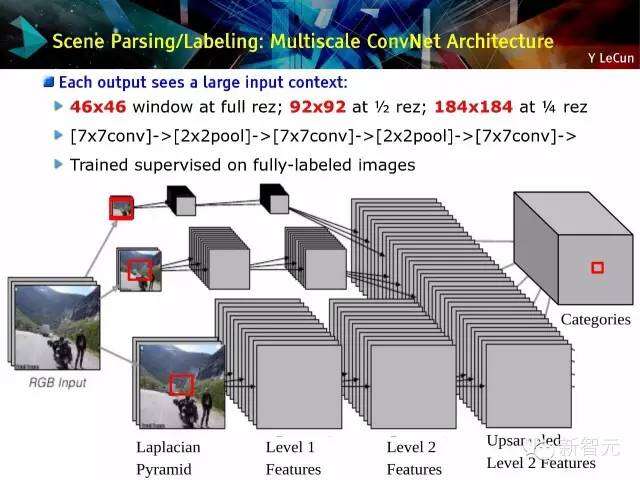
场景解析及标注:多尺度ConvNet架构
每个输出可以看到大量的输入背景,对全方位标注的的图像进行训练监督
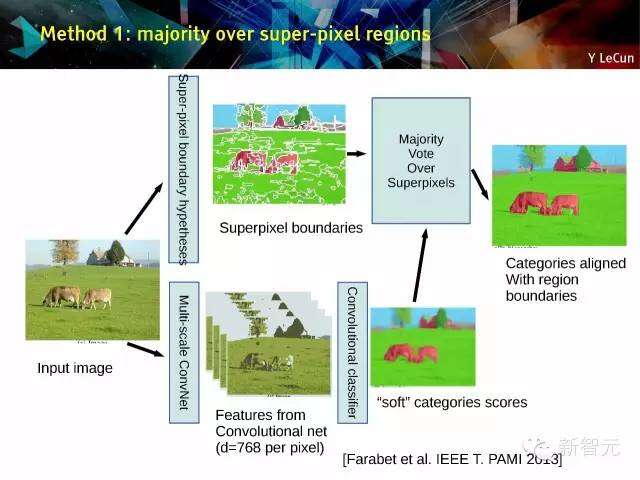
方法1:在超像素区域进行多数表决

对RGB及深度图像的场景解析及标注

场景解析及标注
无后期处理,一帧一帧,ConvNet在Virtex-6 FPGA 硬件上以每帧50毫秒运行,通过以太网上进行通信的功能限制了系统性能
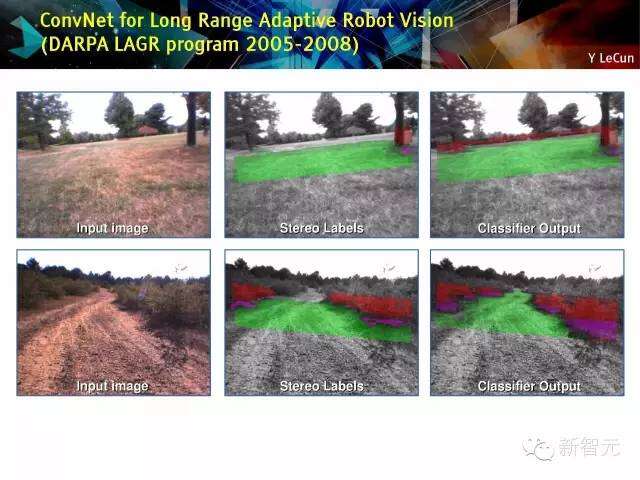
ConvNet用于远距离自适应机器人视觉(DARPA LAGR 项目2005-2008年)

卷机网远距离视觉
预处理(125毫秒),地平面估计,地平线对准,转换为YUV+局部对比标准化,测量标准化后图像“带”不变量金字塔

卷积网络架构
每3x12x25输入窗口100个特征;YUV图像带20-36像素高,36-500像素宽

卷机网络视觉物体识别
在2000年代中期,ConvNets在物体分类方面取得了相当好的成绩,数据集:“Caltech101”:101个类别,每个类别30个训练样本,但是结果比更“传统”的计算机视觉方法要稍微逊色一些,原因是:
1. 数据集太小了;
2. 电脑太慢了;

然后,两件事情发生了。。。
图像网络(ImageNet)数据集[Fei-Fei等,2012年]
120万训练样本
1000个类别
快速及可编程通用目的GPUs
每秒可进行1万亿操作
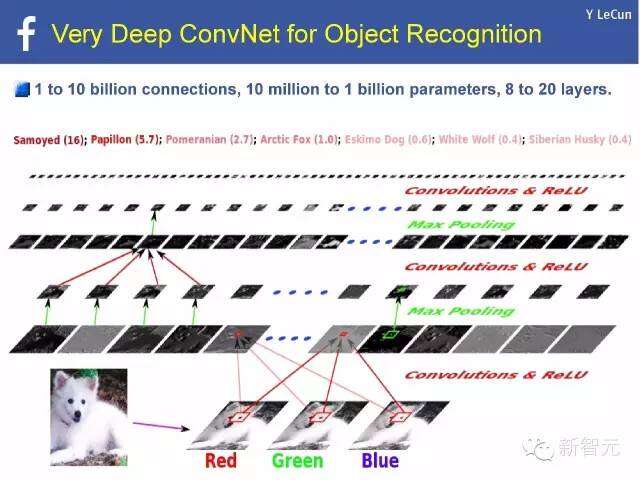
极深度的ConvNet物体识别
1亿到10亿个连接,1000万至10亿个参数,8至20个分层

在GPU上进行极深度的ConvNets训练
ImageNet前5大错误概率是
15%;
[Sermanet等2013年]
13.8%VGGNet [Simonyan, Zisserman 2014年]
7.3%
GoogLeNet[Szegedy等 2014年]
6.6%
ResNet [He et等2015年]
5.7%
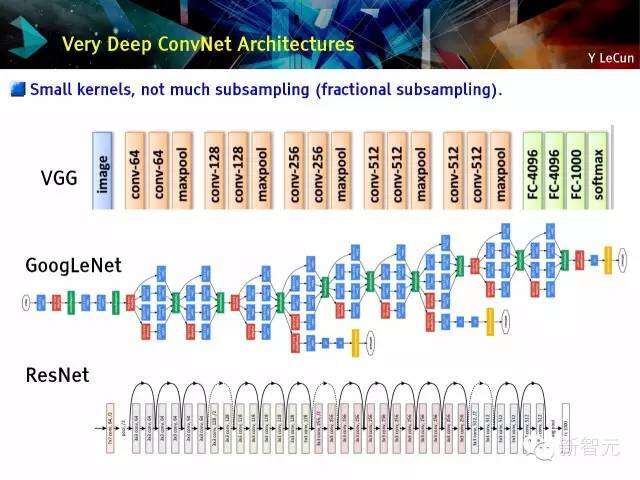
极深度的ConvNet架构
小矩阵,没有进行太多二次抽样过程(断片化二次抽样)
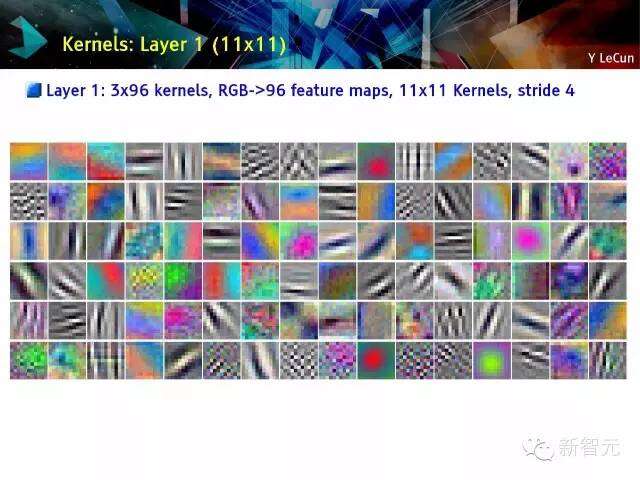
矩阵:第一层(11×11)
第一层:3×9矩阵,RGB->96的特征图,11×11矩阵,4步

学习在行动
第一层过滤器如何学习?
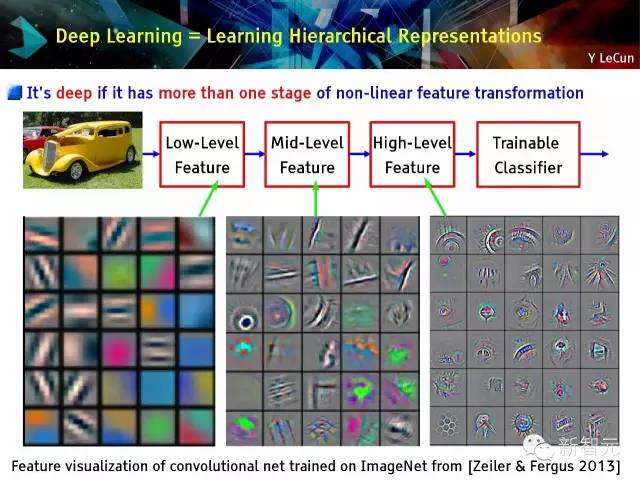
深度学习=学习层次代表
具有超过一个阶段的非线性特征变换即为深度,ImageNet上特征可视化卷积网络学习 [蔡勒与宏泰2013年(Zeiler & Fergus)]
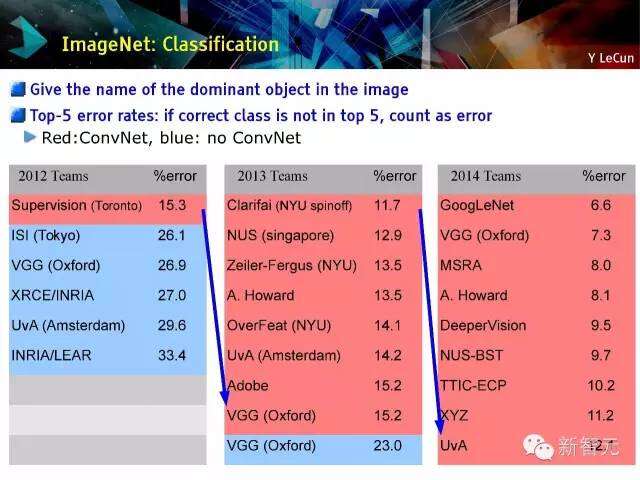
ImageNet:分类
给图像中的主要对象取名,前5误差率:如果误差不是在前5,则视为错误。红色:ConvNet,蓝色:不是ConvNet

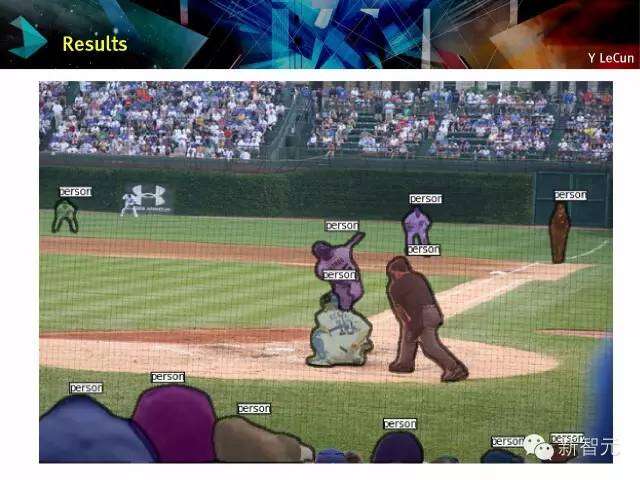
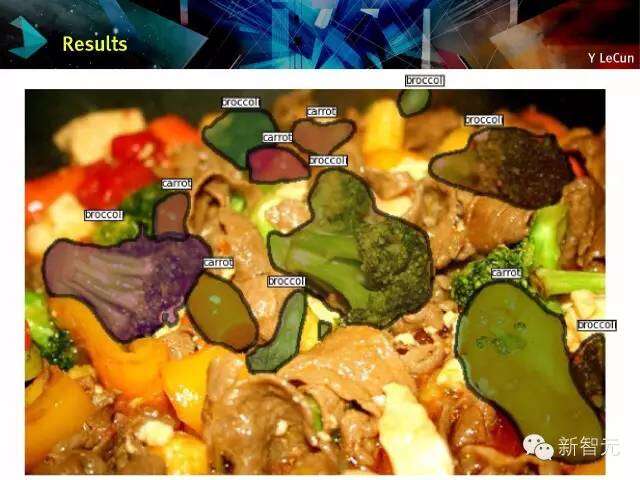
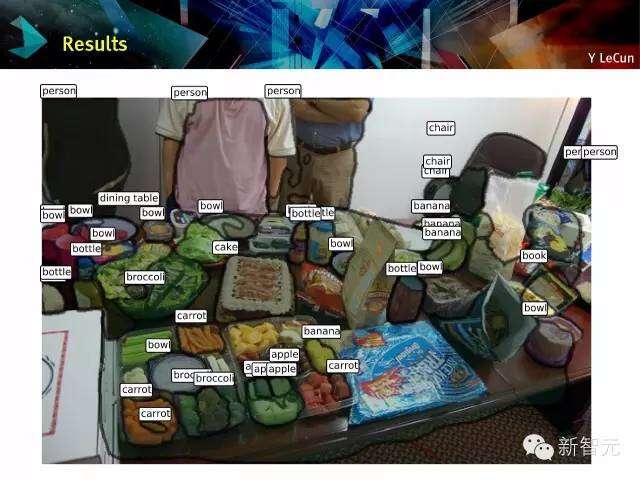
ConvNets对象识别及定位
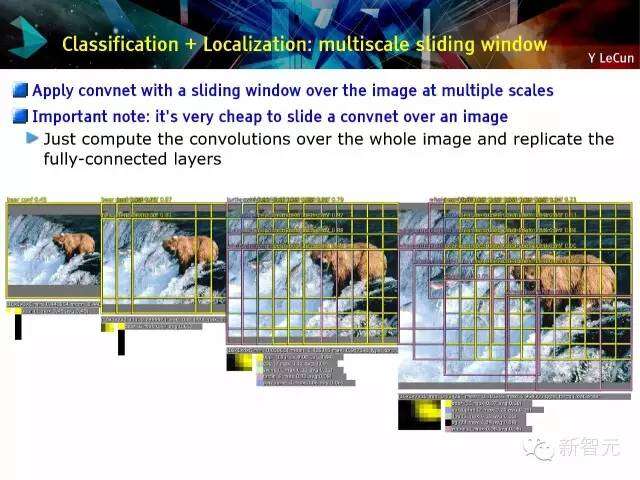
分类+定位:多尺度滑动窗口
在图像上应用convnet滑动窗口来进行多尺度的重要备;在图像上滑动convnet是很便宜的。对于每一个窗口,预测一个分类及边框参数。即使对象没有完全在视窗内,convnet可以预测它所认为的对象是什么。

结果:在ImageNet1K训练前,微调的ImageNet检测
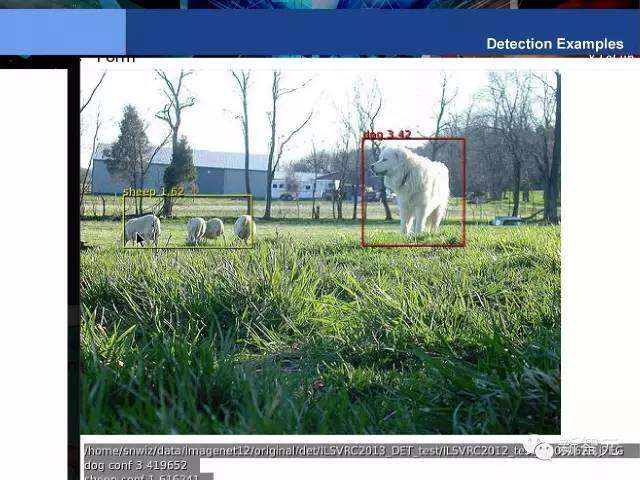
Detection Example:检测例子

Detection Example:检测例子

Detection Example:检测例子
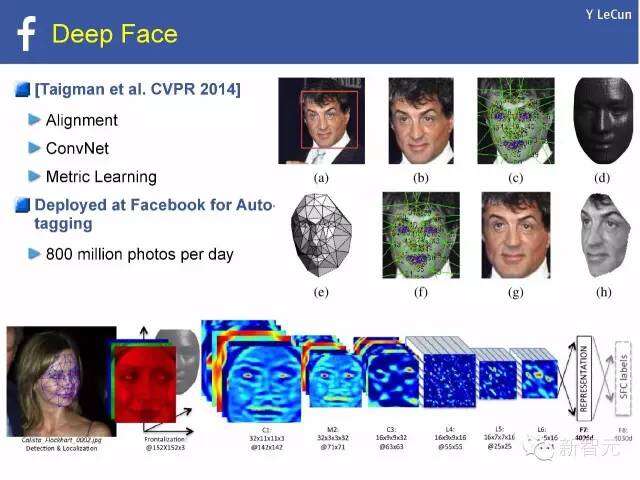
深度面孔
[塞利格曼等(Taigman et al.) CVPR,2014年]
调准ConvNet矩阵学习
Facebook上使用自动标注
每天800万张照片

矩阵学习与暹罗架构
Contrative目标函数,相似的对象应产出相距较近输出产物,不相似对象应产出相距较远输出产物,通过学习和恒定的定位来减少维度,[乔普拉等,CVPR2005年][Hadsell等,CVPR2006年]

人物识别与姿势预测

图像说明:生成描述性句子

C3D:3D ConvNet视频分类
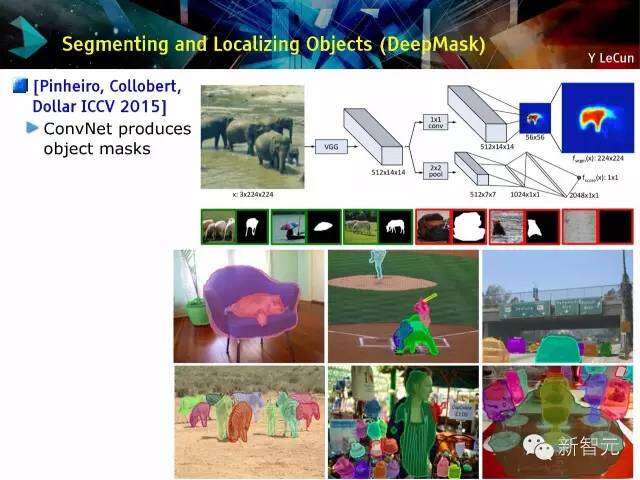
分割与局部化对象(DeepMask)
[Pinheiro, Collobert, Dollar ICCV 2015年]
ConvNet生成物件面部模型
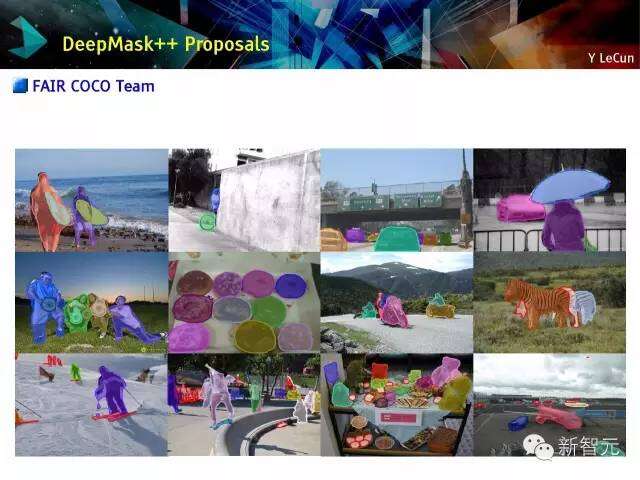
DeepMask++ 建议
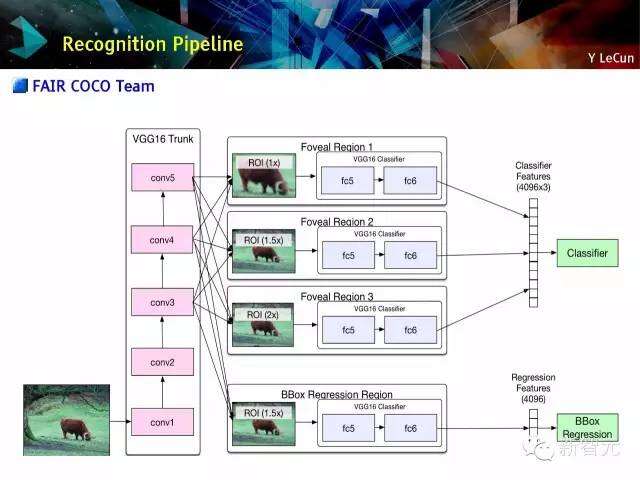
识别路线

训练
通过8×4开普勒(Kepler)GPUs与弹性平均随机梯度下降算法(EASGD)运行2.5天后[张, Choromanska, LeCun,NIPS2015年]









::__IHACKLOG_REMOTE_IMAGE_AUTODOWN_BLOCK__::86
结果
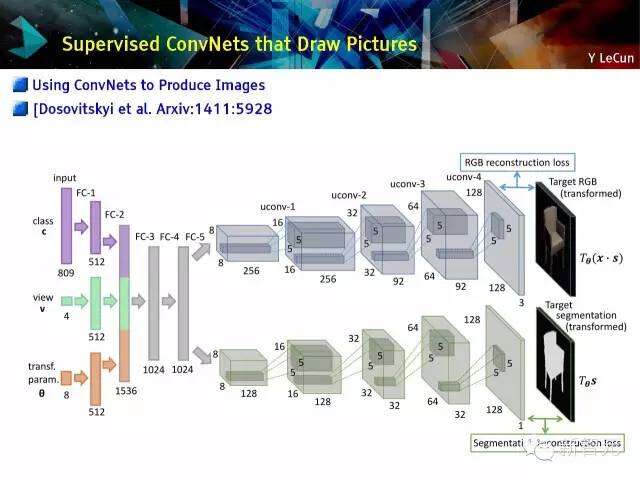
监控下的ConvNets制图
使用ConvNets产生图像
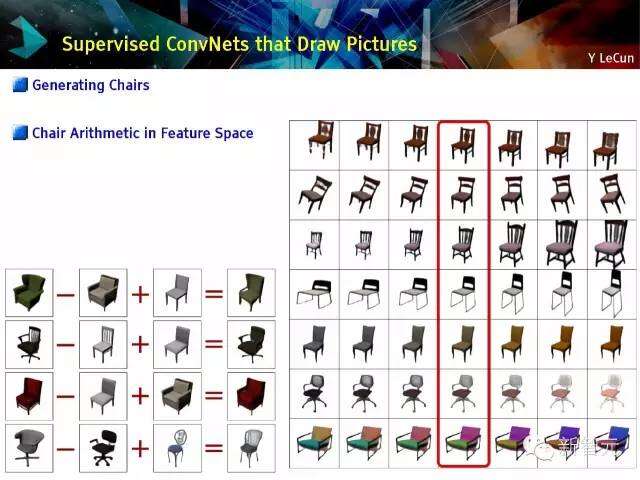
监控下的ConvNets制图
绘制椅子,在特征空间的椅子算法

ConvNets语音识别

语音识别与卷积网络(纽约大学/IBM)
声学模型:7层ConvNet。5440万参数。
把声音信号转化为3000个相互关连的次音位类别
ReLU单位+脱离上一层级
经过GPU 4日训练

语音识别与卷积网络(纽约大学/IBM)
训练样本。
40 Mel频率倒谱系数视窗:每10微秒40帧

语音识别与卷积网络(纽约大学/IBM)
第一层卷积矩阵,9×9尺寸64矩阵
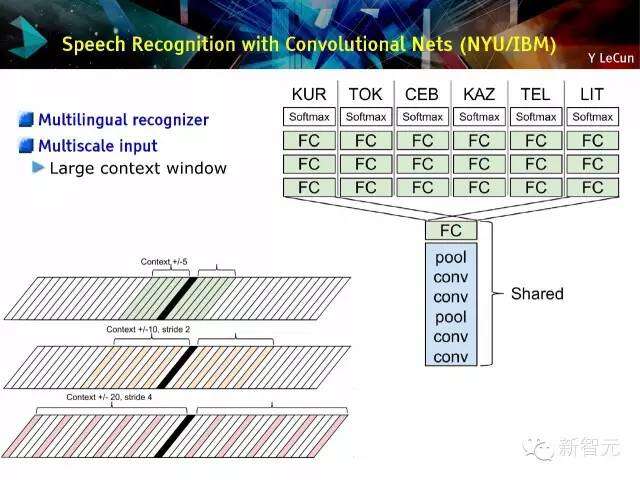
语音识别与卷积网络(纽约大学/IBM)
多语言识别,多尺度输入,大范围视窗

ConvNets无处不在(或即将无处不在)
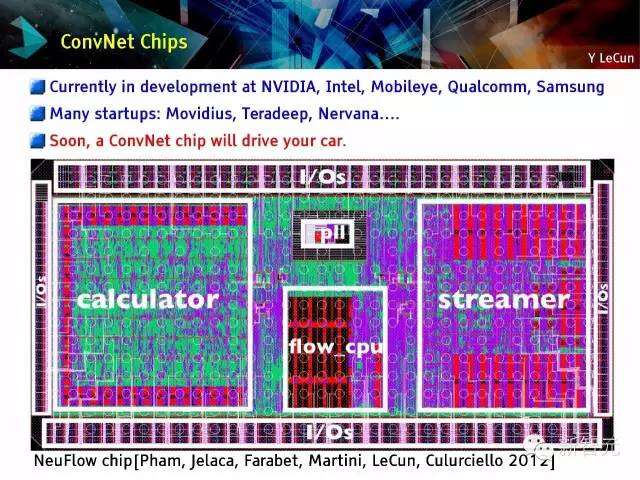
ConvNet芯片
目前NVIDIA,英特尔(Intel), Teradeep,Mobileye, 高通(Qualcomm)及三星(Samsung)正在开发ConvNet 芯片
很多初创公司:Movidius, Nervana等
在不久的将来,ConvNet将会驾驶汽车

NVIDIA:基于ConvNet技术的驾驶员辅助系统
驱动-PX2(Drive-PX2):驾驶员辅助系统的开源平台( =150 Macbook Pros)
嵌入式超级计算机:42TOPS(=150台MacBook Pro)

MobilEye:基于ConvNet技术的驾驶员辅助系统
配置于特斯拉(Tesla)S型和X型产品中

ConvNet连接组学[Jain, Turaga, Seung,2007年]
3DConvNet体积图像,使用7x7x7相邻体素来将每一个体素标注为“膜状物”或“非膜状物”,已经成为连接组学的标准方法
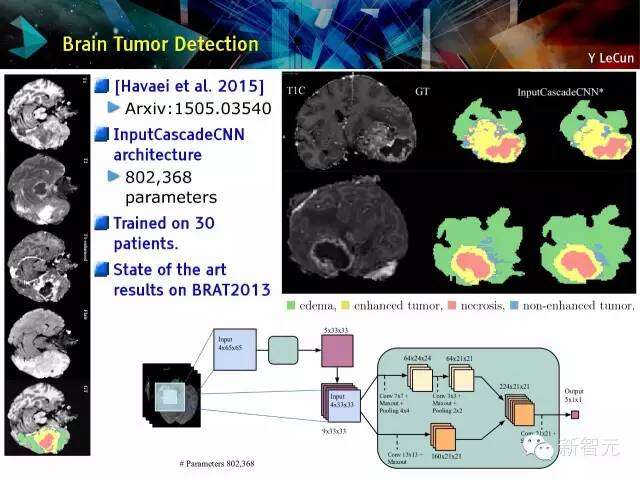
脑部肿瘤检测
级联输入CNN架构,802,368 个参数,用30位患者来进行训练,BRAT2013上显示的结果状况
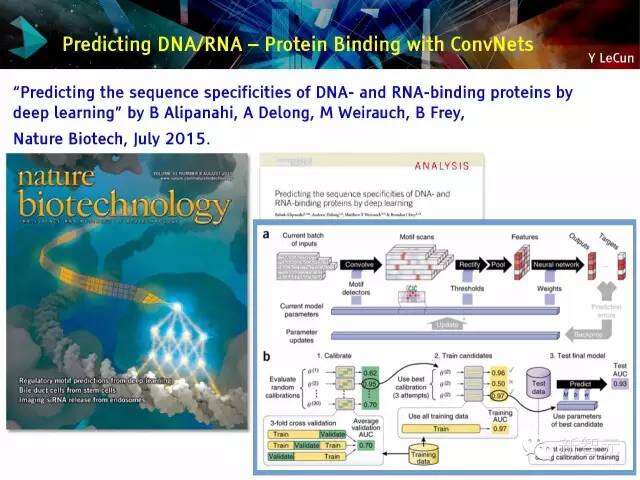
预测DNA/ RNA – ConvNets蛋白质结合
“通过深度学习预测DNA- 与RNA-结合的蛋白质序列特异性”-2015年7月,自然生物技术,作者:B Alipanahi, A Delong, M Weirauch, BFrey

深度学习无处不在(ConvNets无处不在)
在脸书(Facebook)、谷歌(Google)、微软(Microsoft)、百度、推特(Twitter)及IBM等上的许多应用程序。
为照片集搜索的图像识别
图片/视频内容过滤:垃圾,裸露和暴力。
搜索及新闻源排名
人们每天上传8亿张图片到脸书(Facebook)上面
(如果我们把Instagram,Messenger and Whatsapp计算在内,就是每天20亿张图片)
脸书(Facebook)上的每一张照片每隔2秒就通过两个ConvNets
一个是图像识别及标注;
另一个是面部识别(在欧洲尚未激活)
在不久的将来ConvNets将会无处不在:
自动驾驶汽车,医疗成像,增强现实技术,移动设备,智能相机,机器人,玩具等等。

嵌入的世界

思考的向量
“邻居的狗萨摩耶犬看起来好像西伯利亚哈士奇犬”
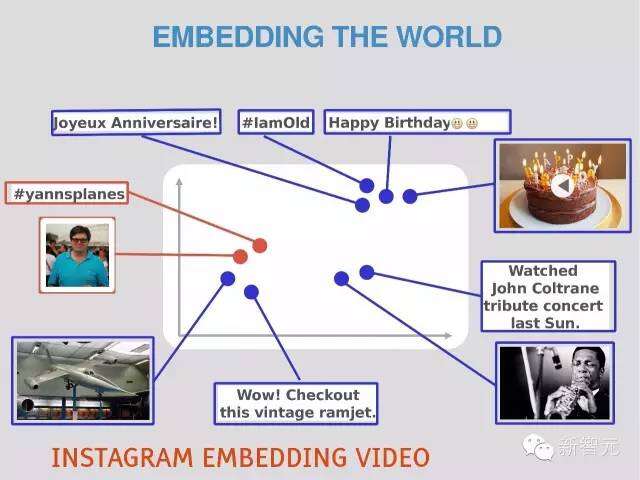
嵌入的世界
iNSTAGRAM 嵌入视频

用“思考的向量”来代表世界
任何一个物件、概念或“想法”都可以用一个向量来代表
[-0.2, 0.3, -4.2, 5.1, …..]代表“猫”的概念
[-0.2, 0.4, -4.0, 5.1, …..]代表“狗”的概念
这两个向量是十分相似的,因为猫和狗用许多共同的属性
加入推理来操控思考向量
对问题、回答、信息提取及内容过滤的向量进行比较
通过结合及转化向量来进行推理、规划及语言翻译
内存存储思考向量
MemNN (记忆神经网络)是一个很好的例子
在FAIR, 我们想要“把世界嵌入”思考向量中来

自然语言理解

文字能嵌入吗?
[Bengio2003年] [Collobert与韦斯顿(Weston),2010年]
通过前后的文字来对该文字进行预测

语义属性的合成
东京-日本=柏林-德国
东京-日本+德国=柏林
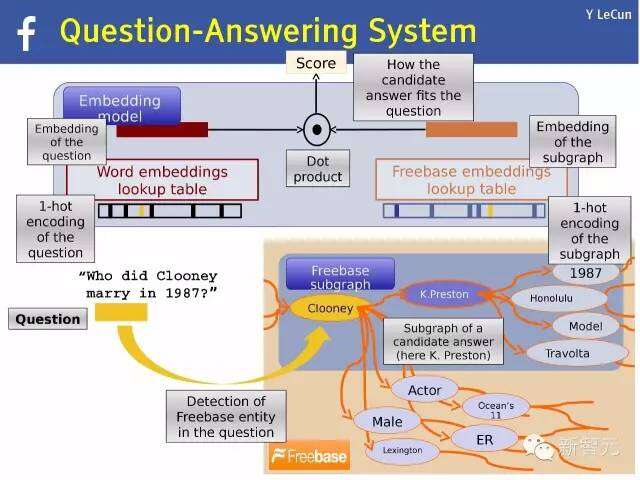
问答系统

问答系统

问答系统

LSTM网络的语言翻译
多层次极大LSTM递归模块
读入及编码英语句子
在英文句末生成法语句子
与现有技术状态的准确率极其相若
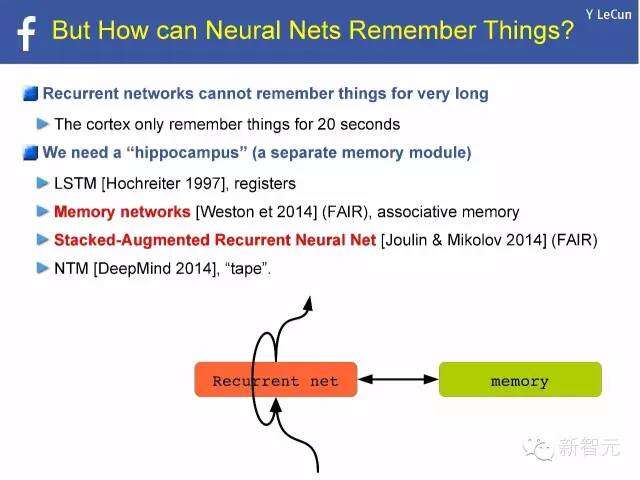
神经网络如何记忆事物?
递归网络不可以长久记忆事物
皮质只可以持续20秒记忆事物
我们需要“海马”(一个独立的记忆模块)
LSTM [Hochreiter 1997年],寄存器
存储网络[韦斯顿(Weston)等,2014年](FAIR),联想记忆
堆叠增强递归神经网络[Joulin与Mikolov,2014年](FAIR)
NTM [DeepMind,2014年], “磁带”.
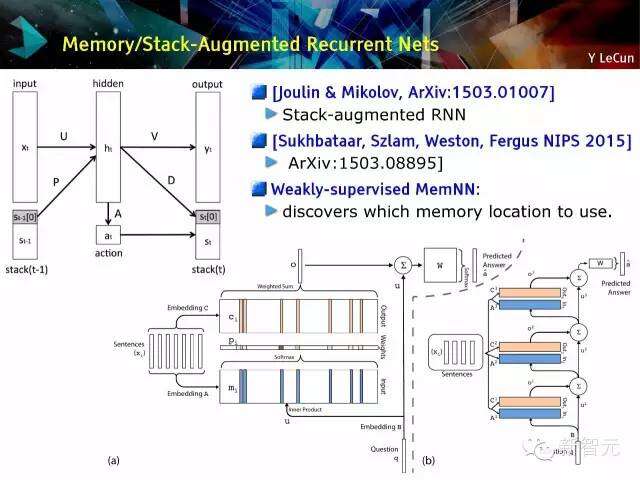
存储/堆叠增强递归网络
堆叠增强RNN
弱监控MemNN:
寻找可使用的存储位置。

内存网络[韦斯顿(Weston),乔普拉( Chopra),博尔德(Bordes ),2014年]
在网络中加入短期内存
::__IHACKLOG_REMOTE_IMAGE_AUTODOWN_BLOCK__::116
通往人工智能的障碍物

(除计算能力以外),人工智能的四项缺失部分
理论的深度认知学习
深度网络中的目标函数几何学是什么?
为何ConvNet架构这么好?[(马拉)Mallat, 布鲁纳(Bruna), Tygert..]
代表/深度学习与推理、注意力、规划及记忆的整合
很多研究集中在推理/规划,注意力,记忆力及学习“算法”
内存增强的神经网络“可求导的”算法
将监控、非监控及强化学习整合在单一的“算法”内
如果进展顺利,波尔兹曼机将会十分有用处。
堆叠的什么-哪里自动编码器,梯形网络等
通过观察及像动物及人类生活一样来发现世界的结构及规律。

神秘的目标函数几何学
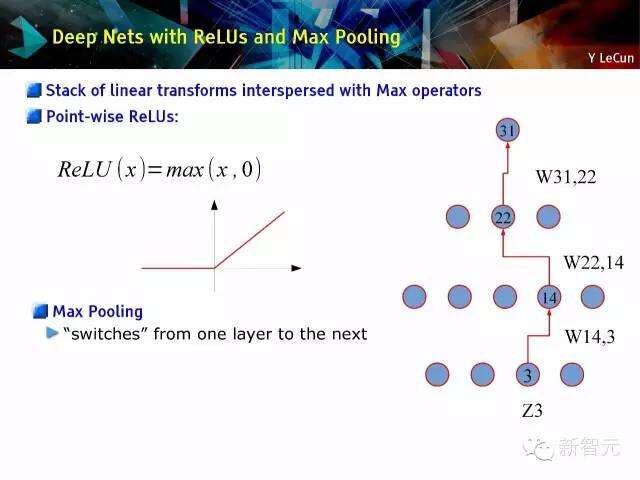
深度网络与ReLUs及最大汇总
线性转换存储栈最大离散操作器
ReLUs点位方法
最大汇总
从一层到另一层开关
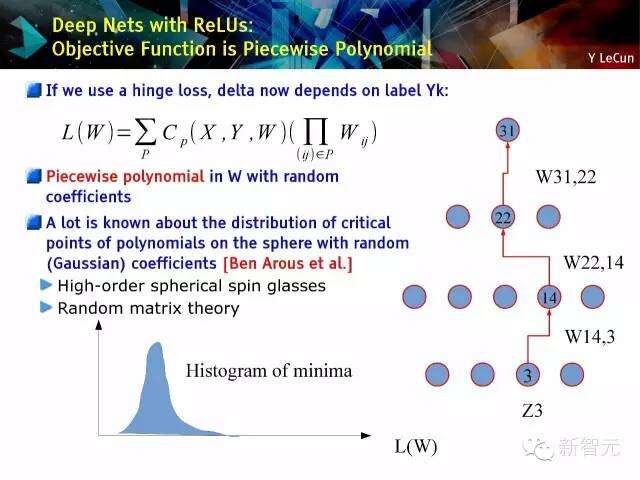
深度网络与ReLUs:目标函数是分段多项式函数
如果我们使用损失函数,增量则取决于Yk。
随机系数的在w上的分段多项式
a lot:多项式的临界点位随机(高斯)系数在球面的分布[本阿鲁斯等(Ben Arous et al.)]
高阶球面自旋玻璃随机矩阵理论
随机矩阵理论
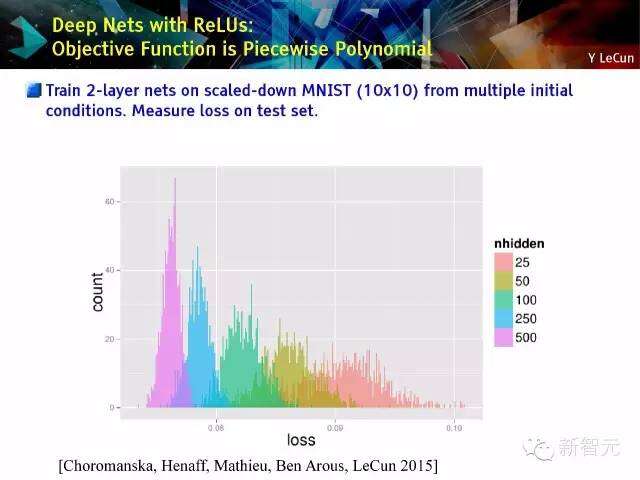
深度网络与ReLUs:目标函数是分段多项式函数
从多个初始条件中训练按比例缩小的(10×10)MNIST 2层网路。测量测试集的损失值。
强化学习,监督学习、无监督学习:学习的三种类型

学习的三种类型
强化学习
机器偶尔会对标量效果进行预测
样本的一部分字节
监控学习
机器预测每个输入的种类或数量
每个样本10到1万位
非监控学习
机器对任何输入部分及任何可观察部分进行预测
在视频中预测未来镜头
每个样本有数以百万计的字节
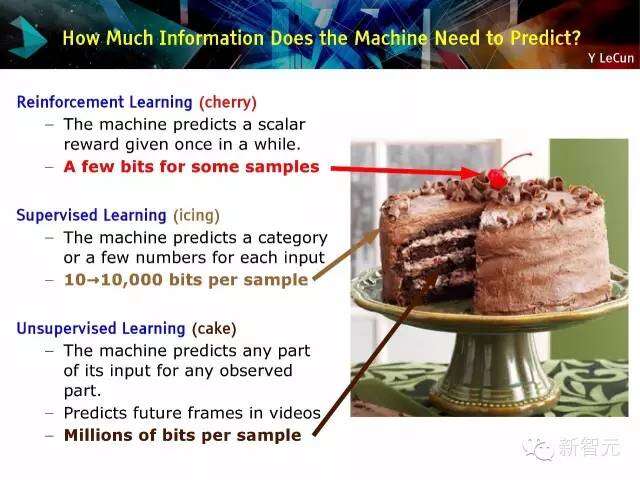
机器需要预测多少信息?
强化学习(车厘子)
机器偶尔会对标量效果进行预测
样本的一部分字节
监控学习(糖衣)
机器预测每个输入的种类或数量
每个样本10到1万个字节
无监督学习(蛋糕)
机器对任何输入部分及任何可观察部分进行预测
在视频中预测未来镜头
每个样本有数以百万计的字节

无监督学习是人工智能的“黑箱”
基本所有动物及人类进行的学习都是无监督学习。
我们通过观察了解世界的运作;
我们学习的世界是三维立体的
我们知道物体间可以独立运动;
我们知道物体的恒久性
我们学习如何预测从现在开始一秒或一小时后的世界
我们通过预测性非监控学习来构建世界模型
这样的预测模型让我们有了“常识”的认知
无监督学习让我们了解到世界的规律。

通过非监控学习而得到的常识
通过对世界预测模型的学习让我们掌握了常识;
如果我们说:”Gérard拿起包离开房间”, 你能够推测出:
Gérard起立,伸展手臂,向门口走去,打开门,走出去。
他以及他的包已经不会在房间里
他不可能消失或飞了出去

非监控学习
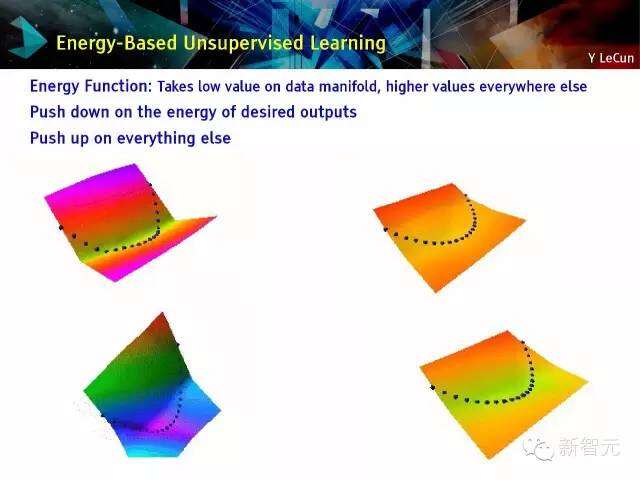
以能量为基础的非监控学习
能量函数:取数据流的最低值,取其他地方的最高值
如果是所需能量输出,则向下按;
其他情况,则向上按;
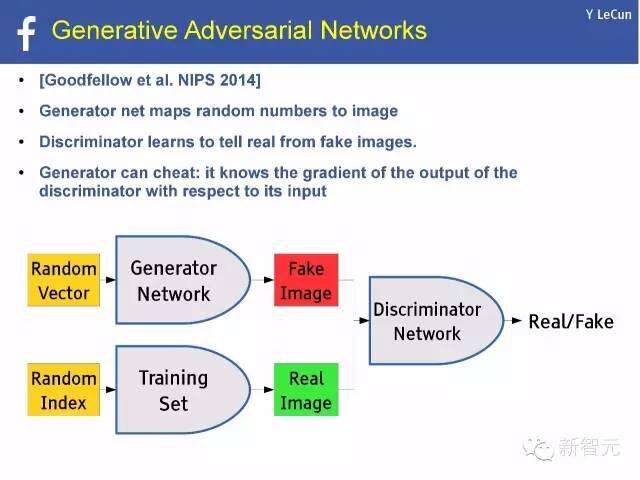
生成对抗的网络
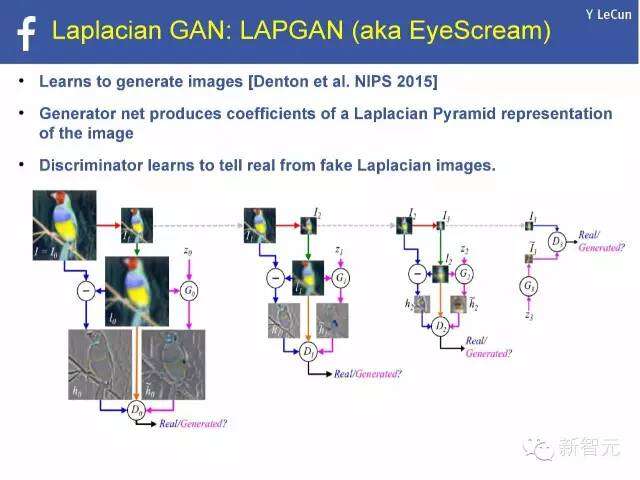
拉普拉斯(Laplacian) GAN:拉埃甘(又名EYESCREAM)
学习生成图像[丹顿等人(Denton et al.),NIPS2015年]
发生器产出拉普拉斯金字塔系数代表的图像
鉴别器学习如何区分真假拉普拉斯图像。
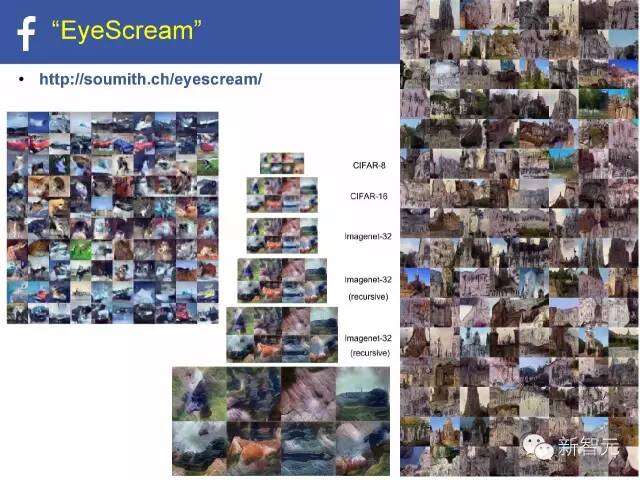
“EyeScream”
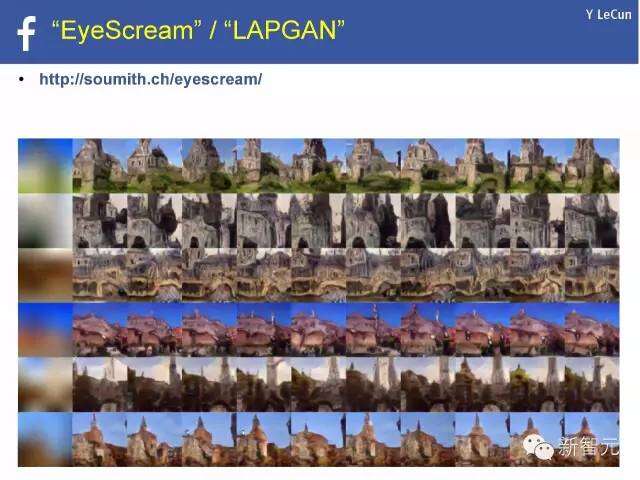
“EyeScream”/“LAPGAN”

发现规律
DCGAN:通过对抗训练来生成图像
[雷德福(Radford),梅斯(Metz),Chintala, 2015年]
输入:随机数字;
输出:卧室

导航流
DCGAN:通过对抗训练来生成图像
用漫画人物来训练
人物之间的插入

面部代数(在DCGAN空间)
DCGAN:通过对抗训练来生成图像
[雷德福(Radford),梅斯(Metz),Chintala,2015年]

无监督学习:视频预测

无监督学习是人工智能的黑箱
无监督学习是能够提供足够信息去训练数以十亿计的神经网络的唯一学习形式。
监督学习需要花费太多的标注精力
强化学习需要使用太多次的尝试
但是我们却不知道如何去进行非监控许诶下(甚至如何将其公式化)
我们有太多的想法及方法
但是他们并不能很好的运作
为何那么难?因为世界本来就是不可预测的。
预测器产出所有未来可能的平均值-模糊图像
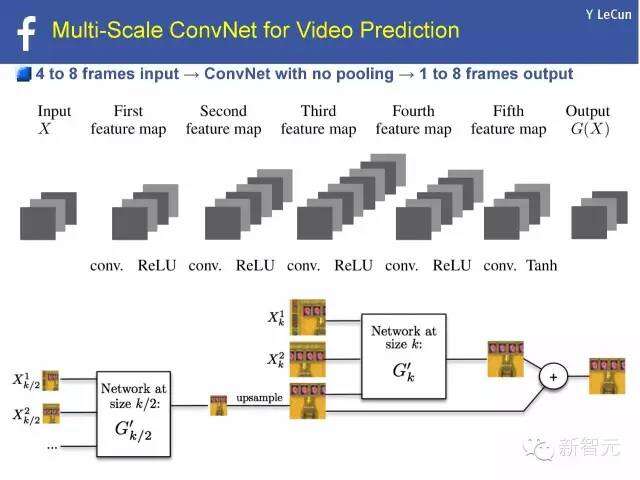
ConvNet多尺度视频预测
4到8框架输入→无需汇总的ConvNet→1到8框架输出

无法使用开方误差:模糊预测
世界本来就是无法预测的,mse训练预测未来可能情况的平均值:模糊图像

ConvNet多尺度视频预测

ConvNet多尺度视频预测

ConvNet多尺度视频预测
与使用LSTM的人[Srivastava等, 2015年]做比较
无监督学习预测
在“对抗训练”中已经取得了一些成果
但是我们离一个完整的解决方案还相距甚远。

预测学习

机器智能与人工智能将会有很大不同

人工智能会是什么样子呢?
人类和动物行为拥有进化过程与生俱来的驱动力
抗战/飞行,饥饿,自我保护,避免疼痛,对社交的渴求等等
人类相互之间做错误的事情也是大部分因为这些驱动力造成的。
受威胁时的暴力行为,对物质资源及社会力量的渴求等等。
但是,人工智能系统并没有这些驱动力,除非我们在系统里进行配置。
在没有驱动力情况下,我们很难去对智能实体进行想像
尽管在动物世界里我们有许多的例子。
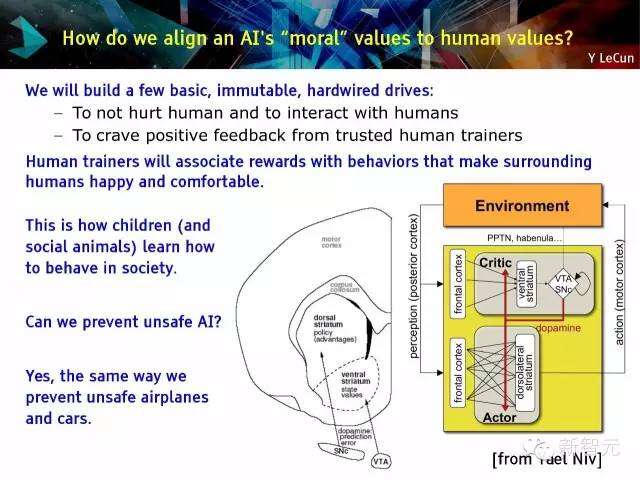
我们如何调整人工智能的“道德价值”使其与人类价值保持一致?
我们将建立一些基本的、不可改变的固有驱动力:
人类培训师将会把使周围人类开心及舒适的行为与奖励联系起来。
这正是儿童(及社会性动物)如何学习在社会中变得讲规矩
我们能够预防不安全的人工智能吗?
是的,就如同我们防范存在潜在危险的飞机及汽车一样

与人类同等级的人工智能如何产生?
与人类同等级的人工智能的出现不会是一个孤立“事件”。
它会是渐进式的
它也不会孤立发生
没有任何机构可以在好的想法上面存在垄断。
先进的人工智能现在是一个科学性的问题,而不是一个技术性的挑战。
建立无监督学习是我们最大的挑战
个人的突破将会很快被复制
人工智能研究是一个全球性的团体。
大部分好的点子来自学术届
尽管另人最印象深刻的应用程序来自行业
区分智能与自主化是十分重要的
最智能的系统并不是自主化的。

结论
深度学习正在引领应用程序的浪潮
如今:图像识别、视频认知:洞察力正在运作
如今:更好的语言识别:语言识别正在运作
不久的将来:更好的语言理解能力,对话及翻译将成为可能
深度学习与卷积网络正在被广泛使用
如今:图像理解能力已经在脸书、谷歌、推特和微软中被广泛应用
不久的将来:汽车自动驾驶、医疗图像分析,机器人的感知能力将成为可能
我们需要为嵌入式应用程序找到硬件(与软件的)
对于数码相机、手机设备、汽车、机器人及玩具而言。。
我们离发明真正智能的机器还相距甚远。
我们需要将推理与深度学习整合在一起。
我们需要一个很好的“情节化”(短期)内存。
我们需要为无监督学习找到好的理论原理做支撑。
via:新智元
更多阅读:
