
数据科学家如何变得性感的故事,大致也就是作为成熟学科的统计学如何与新兴学科计算机科学发生关系的故事。「数据科学」这个术语的出现较晚近,用来指代一个需要解读大量数据的职业。但解读数据这件事的历史很长,它已经被科学家、统计学家、图书馆员、计算机科学家以及其他人士讨论多年。下文的时间线追溯「数据科学」一词的演化,以及它的应用、对它进行定义的尝试和一些相关的术语。
1962 年 John W.Tukey 在《数据分析的未来》(The Future of Data Analysis)中写道:「长久以来我以为我是一名统计学者,对于从特例中获得关于总体的推断抱有兴趣。但当我目睹了数理统计学的发展,我产生了猜想与怀疑…我开始感到我根本的兴趣在于数据分析…数据分析,以及与之相关的一部分统计学,必须…担负更多科学的特性而非数学的特性…数据分析本质上是一门经验科学…预设程序的电子计算机…究竟有多重要呢?在许多情况下,答案是令人惊讶的:重要但不是至关重要,而在其他情况下计算机无疑是至关重要的。」
1947 年 Tukey 创造了「比特(bit)」这个术语,这个词在 1948 年被 Claude Shannon 用于《传播的数学理论》(A Mathematical Theory of Communications)一文中。1977 年,Tukey 出版了《探索性数据分析》(Exploratory Data Analysis),他在书中提出,应该更重视利用数据做出哪些假设需要被测试的建议,以及,探索性的数据分析和论证性的数据分析「能够且应该并驾齐驱」。

1977 年,国际统计计算联合会( The International Association for Statistical Computing )简称 IASC 作为国际统计研究院( ISI )的一个分支成立。“国际统计计算联合会的任务是把传统统计方法、现代计算机技术和各领域专家的知识连接到一起,以将数据转化为信息和知识。”

1994 年 9 月,商业周刊发表了一篇关于“数据库营销”的商业报道:“企业收集了大量有关你的信息,并使用这些知识提炼成营销信息精确瞄准你…八十年代对扫码器的热潮在大范围的失望中结束:许多公司被数据总量淹没却无法获得有用信息…不过,许多公司相信,除了勇敢站在数据库营销的前线以外他们别无选择。”
1996 年国际分类协会联盟(InternationalFederation of Classification Societies )简称 IFCS 在日本神户举行双年会。「数据科学」这个术语首次被包含在会议的标题里(数据科学,分类和其他相关方法)。联盟于 1985 年由六个国别/语言的分类组织共同成立,其中之一的分类协会( The Classification Society )成立于 1964 年。这些分类协会在其出版物中大量使用数据分析、数据挖掘、数据科学等术语。

1997 年 C.F.Jeff Wu 教授(现就职于乔治亚理工大学)在密歇根大学统计系 H. C.Carver 主席的就职典礼上倡议,统计学应被重命名为数据科学,统计学家应被重命名为数据科学家。
1997 年《数据挖掘与知识发现》( Data Mining and Knowledge Discovery )期刊发行。这两个术语的顺序意味着「数据挖掘」地位的上升,并成为更流行的描述「从大数据库中提取信息」的方式。
1999 年 12 月, 沃顿商学院 Knowledge@Wharton 的《从数据中挖掘知识的金块》引用了Jacob Zahavi 的说法:「传统统计方法在小数据集上工作良好。但今天的数据库有上百万行和大量的列…可拓展性成了数据挖掘的一个大问题。另一个技术挑战是开发出能更好分析数据、发现非线性关系和元素间联系的模型…对于网站决策可能需要特殊的数据挖掘工具。」
2001 年 William S.Cleveland 出版了《数据科学:一份扩展统计领域技术领域的行动方案》(Data Science: An Action Plan for Expanding the Technical Areas of theField of Statistics)。这份计划要扩大统计学领域的技术工作主要领域。这份计划雄心勃勃包含本质性变化。变化后的领域被称为「数据科学」。Cleveland把这个新领域定位在计算机科学与当代数据挖掘工作中:「…数据分析师收益有限。因为计算机科学家思考和分析数据的方法有限,就如同统计学家关于计算环境的知识有限。知识的融合会带来巨大的生产力革新。这意味着统计学家应多注意有关知识的计算,就如同过去数据科学对数学注意 … 数据科学系应该由致力于提升数据计算的成员和与计算机科学家合作的成员组成。」
2001 年 Leo Breiman 出版了《统计建模:两种文化》( Statistical Modeling: The Two Cultures ):「在使用统计模型从数据中提取结论的过程中有两种文化。一个假定数据是由一个特定分布模型生成的。另一个使用算法模型,并把数据结构看作未知的。统计学界普遍致力于仅仅使用针对数据的模型。这种投入产生了无意义的理论、值得怀疑的结论,并让统计学家无法触及大量现实问题。算法模型,在理论与实践中,在统计学之外快速发展。它既可以被应用于庞大复杂的数据集,也可以在小数据集上建立精确信息量大的模型。如果我们这个领域的目标是使用数据解决问题,那么我们需要摆脱对纯粹基于数据模型的依赖,并使用更多样的工具。」
2002 年 4 月,数据科学期刊( Data Science Journal )创刊,旨在发表「科学与技术领域的数据与数据库管理」方面的论文。「此期刊涵盖对于数据系统的描述,及其在互联网上的发布、应用和法律问题。」此期刊由国际科学理事会( International Council for Science )旗下的数据科学技术委员会( Data for Science and Technology )出版。
2003 年 1 月,期刊数据科学( Journal of Data Science )创刊:「我们用‘数据科学’指代与数据有关的一切业务:收集、分析、建模……但最重要的部分是它的应用——所有形式的应用。本刊着眼于广义上的统计方法应用…期刊数据科学为所有数据工作者提供一个展示看法、交流思想的平台。」
2005 年 5 月,Thomas H. Davenport、Don Cohen、 Al Jacobson 共同发表了《分析的较量》( Competing on Analytics ),这是一份巴布森学院工作知识研究中心的报告。报告描述「一种基于对分析、数据、基于事实决策的新型竞争的发展…企业开始应用统计量化方法和预测模型,而不再是传统手段,作为竞争的主要部分。」这项研究晚些时候由 Davenport 发表在《哈佛经济评论》( 2006 年 1 月),之后被扩展成《分析的较量:胜利的新科学》一书( 2007 年 3 月)。
2005 年 9 月,美国国家科学委员会出版了《长存的数码数据收集:使 21 世纪的研究与教育成为可能》( Long-lived Digital Data Collections: Enabling Research and Education in the 21st Century )。此报告的一则推荐语写道:「NSF(美国国家科学基金会)与收集的管理者与广义团体合作。 NSF 应该行动起来,让数据科学家的职业道路发展、成熟,保证研究机构包含一定数量的高质量数据科学家。」这份报告将「数据科学家」定义为「信息与计算机科学家,数据库与软件工程师与程序员,跨学科专家,保管员以及专业注释者,图书馆员,档案馆员和其他人员,这些人对数码数据收集的成功管理至关重要。」
2007 年上海的复旦大学成立了数据科学研究中心( Research Center for Dataology and Data Science )。2009 年此中心的两位学者朱扬勇和熊赟出版了《数据学与数据科学概论》( Introduction to Dataology and Data Science ),这篇文章中他们声称「与自然科学和社会科学不同,数据学与数据科学以数码世界的数据作为研究对象。这是一门新的科学。」这家中心还举办数据科学国际研讨会。
2008 年 7 月,Jisc 出版了一项旨在「盘点与推荐对数据科学家的角色与职业发展,以及相关的数据处理技术在学术界的供应」的研究的最终报告。这份题为《数据科学家与管理者的技能、角色、职业结构:对现有实践与未来需求的评估》的报告( The Skills, Role & Career Structure of Data Scientists & Curators: Assessment of Current Practice & Future Needs ),把数据科学家定义为「在研究实施之处工作-或是在数据中心团队,与数据的创造者紧密合作-可能会进行创造性探寻与分析使他人能使用数码数据工作,以及数据库技术开发的人士。」
2009 年 1 月,《为了科学与社会驾驭数码数据的力量》( Harnessing the Power of Digital Data for Science and Society )出版。这份报告由数码数据跨机构工作组( Interagency Working Group on Digital Data )提交给美国国家科技理事会的科学委员会( The Committee on Science of the National Science and Technology Council )。报告称「国家需要识别与推广擅长在复杂动态的挑战中进行数据保存、维持获取、再利用、变更用途的新学科与技术人才。许多学科见证着一类新型数据科学与管理专家的崛起,他们擅长电脑、信息、数据科学领域以及另外某种科学领域。这些人是科学事业在现在与未来获取成功的关键。然而这些人的贡献通常未被认可,他们的职业路径也有限。」
2009 年 1 月,谷歌的首席经济学家 HalVarian 告诉《麦肯锡季报》( Mc Kinsey Quarterly):「我一直说未来十年最性感的工作是统计学家。人们以为我在开玩笑,但谁会料到电脑工程师成了 1990 年代最性感的工作呢?驾驭数据的能力-能够理解它,处理它,从中提取价值,可视化,进行沟通-这将是未来几十年非常重要的技能。因为现在我们有免费的无处不在的数据。所以,所需的稀缺要素是理解数据并从中提取价值的能力…我真的认为这些能力-接触、理解、传达来自数据分析的洞察-会是及其重要的。管理者需要能够独立接触和理解数据。」
2009 年 3 月 Kirk D. Borne 和其他天体物理学家向 Astro 2010 Decadal Survey 提交了一份题为《天文学教育的改革:大众的数据科学》( The Revolution in Astronomy Education: Data Science for the Masses )的文章。文章中说:「训练下一代从数据中得到明智的结论对科学、社区、项目、机构、商业、经济的成功都是不可或缺的。对于专家(科学家)和非专业技术人员(其他所有人:大众,教育者,学生,劳动力)都是这样。专家比较学习和应用新的数据科学研究技巧以增进我们对宇宙的理解。非专业技术人员作为 21 世界的劳动力需要基础的信息技能,加之从日益被数据占领的世界中终身学习的技能。」
2009 年 5 月,Mike Driscol 在《数据极客的三种性感技能》( The Three Sexy Skills of Data Geeks )中写道:「…生活在数据时代之下,那些能够建模、合并、视觉传达数据的人——请叫我们统计学家或数据极客——是抢手货。」Driscol 后来又在 2010 年 8 月发表了《成功数据科学家的七个秘密》( The Seven Secrets of Successful Data Scientists )。
2009 年 Nathan Yau 在《数据科学家的崛起》( Rise of the Data Scientist )中写道:「我们都曾读到过,谷歌的首席经济学家 Hal Varian 在 1 月坦言未来十年最性感的工作会是统计学家。我显然完全同意这个看法。见鬼,我想说得再绝对一点。它现在就已经是最性感的工作了,无论肉体或精神层面。不过,如果你继续读 Varian 的访谈,你会发现他所谓的统计学家实际是泛指一类人,他们从大型数据集中提取信息,然后为不是数据专家的人们呈现一些可用的东西…(Ben) Fry 提倡一个把许多分散领域专业知识的技能和人才汇集在一起的全新领域… (包含计算机科学,数学,统计学,数据挖掘,图形设计,数据可视化和人机交互)。在 Flowing Data 网站强调可视化的两年之后,领域间的合作看起来变得更常见,但更重要的是,计算信息设计逐步逼近现实。我们看到数据科学家——能完成全部这些工作的人——从人群中脱颖而出。」
2009 年 6 月 ,Troy Sadkowsky 在 LinkedIn 上创建了数据科学群组(data scientists group),跟他的网站 datasceintists.com 配套(之后变成 data scientists.net)。
2010 年 2 月, KennethCukier 为《经济学人》写了特别报道《数据,到处都是数据》( Data, Data Everywhere ):「…一种新的职业出现了,数据科学家,他们结合了软件程序员、统计学家和讲述者/艺术家的技能,从数据的群山中挖掘金块。」
2010 年 6 月, Mike Loukides 在《数据科学是什么?》( What is Data Science? )中写道:「数据科学家把创业实践、增量建立数据产品的意愿、探索的能力、迭代获取解决的能力相结合。他们本质是跨学科的。他们可以触碰同一个问题的所有方面,从最初的数据收集和调整到做出结论。他们能超出常规思考,提出解决问题的新方式,或者处理很宽泛的问题:这里有很多数据,你能由此做点什么吗?」
2010 年 9 月, Hilary Mason 和 Chris Wiggins 在《数据科学的一种分类法》( A Taxonomy of Data Science )中写道:「…我们认为提出一种分类法是有用的…有关数据科学家都做些什么,以粗略的时间顺序排列:获得,清洗,探索,建模,解读…数据科学很明显是黑客艺术、统计学、机器学习,以及数学知识加上要用数据分析解读的领域知识的一种混合…这需要在一个科学环境中的创造性决策和开明的思想。」
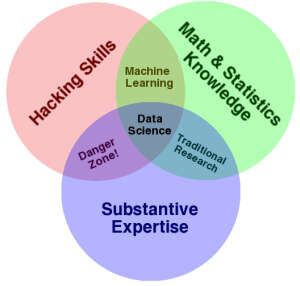
来源:Drew Conway
2010 年 9 月, Drew Conway 在《数据科学文恩图》( The Data Science Venn Diagram )写道:「…如果有人想成为一个完全称职的数据科学家,那需要学习很多东西。可惜的是,单纯例举文本和教材并无法缓解这种纠结。所以,出于简化讨论的考虑,以及把我个人的想法添加进这个已经很拥挤的思想集合中的考虑,我把数据科学文恩图呈现给大家…黑客技能,数学与统计知识和专业知识。」
2011 年 5 月,Pete Warden 在《为何‘数据科学’一词有瑕疵却也有用》( Why the term ‘data science’ is flawed but useful )里写道 : 「什么属于,什么不属于数据科学,并没有被广泛认同的边界。它只是对统计学进行一种时髦的再包装吗?我不这么认为,但我也没有对它详尽的定义。我相信近期出现的数据充裕为世界点亮了什么新的东西,而当我环视四周我看到的是拥有共同特征,却难以被归入传统类别的人们。这些人倾向于超越那些统治着企业和工业界的狭窄细分,掌控从寻找数据、大规模处理、可视化、将其写成故事的每个环节。他们的工作看似是始于审视数据能告诉他们什么,然后从中挑出有趣的线索进行深入,而不是像传统的科学家那样先选择问题,然后寻找数据来探讨问题。」
2011 年 5 月, David Smith 在《数据科学:这名字包含什么?》( Data Science : What’s in a name? )写道:「数据科学和数据科学家这两个术语被广泛使用了一年多,但从那时起它们就真的大获成功:许多公司现在在招聘‘数据科学家’,会议都被冠以‘数据科学’的名字。但尽管存在这种广泛接受,有些人还是拒绝改掉‘统计学家’或‘量化’,‘数据分析师’这些相对传统的术语…我认为‘数据科学’这个词最能描述我们实际做的事:一种计算机黑客、数据分析、问题解决的组合。」
2011 年 6 月,Mat thew J. Graham 在「天文大型数据库中天文统计和数据挖掘研讨会」谈到「数据科学的艺术」。他说:「为了在 21 世纪新型数据密集环境中获得成功,我们需要开发新的技能…我们需要理解(数据)遵从什么规律,如何被符号化和传播,以及它们与物理时空的关系。」
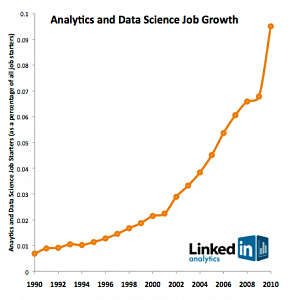
2011 年 9 月,D.J.Patil 在《建立数据科学团队》( Building Data Science Teams )中写道:「起初在 2008 年,我和 Jeff Hammerbacher (@hackingdata) 坐在一起分享我们在 Facebook 和 LinkedIn 建立数据与分析团队的经历。在许多意义上,那次会面是数据科学作为一个独特专业领域的开始…我们意识到随着我们所在机构的成长,我们都要琢磨如何称呼团队的成员。‘商业分析师’听起来太局限。‘数据分析师’是另一个备选,但我们担心这个头衔会限制成员的能力范围。毕竟,我们团队的很多成员有深厚的工程师背景。‘研究科学家’在 Sun、HP、 Xerox、 Yahoo、IBM 这样的大公司听起来是个合理的头衔。不过我们感觉研究科学家大多专注于未来抽象的项目,实验室里的工作也与产品开发团队隔绝。如果实验室的工作最终能影响核心产品,也需要花费几年时间。与之不同的是,我们的团队致力于数据的应用,能够立即对业务产生大规模的影响。‘数据科学家’看起来是最合适的头衔:同时使用数据与科学创造新东西的人。」
2012 年 9 月,Tom Davenport 和 D.J. Patil 在《哈佛商业评论》发表了《数据科学家:21世纪最性感的职业》( Data Scientist: The Sexiest Job of the 21st Century )。
来源:forbes.com
作者:Gil Press
编译:Datartisan数据工匠-王鹏宇
更多阅读:
