
为什么要编译这篇文章,一方面是讲述大数据在生活中的应用,另一方面,作者则写了一些话:
通过编译与癌症有关的文献得知,有近90%的癌症患病风险与人们的生活方式密切相关,而程序员群体的生活方式,很多都处于不健康或亚健康状态,如熬夜、加班、抽烟、缺乏运动,都是很多程序员的日常生活状态。我们与其用寄希望于用最先进的技术(如大数据)来诊断和治疗癌症,远远不如用良好的生活方式将癌症“扼杀于摇篮当中”。
2015年7月初,李开复先生在癌症医治康复后,在其微博上解嘲自己:大家以后不要叫我李开复,叫我李康复就好了。如果生命可以后退30年,或许李先生会重新选择自己的生活方式。有句话说得好:健康是前面的1,事业、财富、名利等都是其后的0,失去前面的1、一切皆为零!
知易行难,共勉之!
以下是正文:
目前,当人们在谈及大数据时,大家更为津津乐道的是,如何利用大数据技术,挖掘出数据背后的商业新模式——然后利用这种“新”模式为公司谋取商业利益。这也难怪,无利不起早。当下,大数据之所以能发展壮大,热火朝天,来自于诸如谷歌(Google)、亚马逊(Amazon)及脸谱(Facebook)等互联网巨头的大力推动,功不可没。
人类社会已经开启了三次产业革命。第一次产业革命,是以蒸汽机为标志。第二次产业革命,是以内燃机和电力发明为标志,第三次产业革命,是以可再生能源(如核能)和互联网为标志。有研究表明,大数据或作为动力引擎之一,引领人类的第四次产业革命。
如果大数据的用途,仅局限于帮商业大佬们挣点钱花,那它绝对不能担当起“天将降大任于斯人也”的重责。目前,科学技术已极大地拓展了人类的视野,大到通过是通过天文望远镜,探索浩瀚无边的宇宙空间,小到利用显微镜细,致观察构成自然界的最小微生物,科学技术无不扮演着重要的角色。
然而,多年以来,在人类社会,一直存在着一个难以降服的恶疾——癌症,严重威胁人类的生命健康。目前,癌症已成为全球发病和死亡的最主要原因之一。据世界卫生组织(WTO)2015年最新的统计资料显示统计资料显示,仅2012年一年就有约1400万新发癌症病例和820万例癌症相关病例死亡。在未来20年里,新发病例数将增加约70%,即死亡病例将从由2012年的1400万上升到2200万。
在过去的50多年里,经过人类社会不断的努力,癌症治愈率仅仅提升了不到8%。这是人类社会所有疑难杂病中,治愈率提升最为缓慢的一种疾病。如果某项技术能较大提升癌症的治愈率,那可真是“善莫大焉”。事实上,大数据站在当前信息领域的最前沿,在对抗癌症的斗争中,可以走得更远。
本文如下的篇幅主要分为下面6个小部分,分别用来回答如下6个小问题:(1)什么是大数据?(2)癌症的成因是什么?(3)大数据用之于癌症,都有哪些挑战?(4)当前都有哪些机构在用大数据抗争癌症?(5)癌症诊疗的大数据主要源于何方?(6)大数据对抗癌症的前景如何?下面一一给予介绍。
1.什么是大数据?
在谈及大数据之前,我们先说说什么是数据。
从一开始起,人类很多的生产及交换活动,都是以数据为基础展开的。例如,度量衡和货币的背后都是数据。人类最早有关数据存储和分析的例子,莫过于记账(或记录财产)用的符木(Tally stick)。例如,1960年,在乌干达发现的伊桑戈骨(Ishango bone),就是史前数据存储和计算的最早的物证(如图1所示)。伊桑戈骨是一种由狒狒骨制作而成,距今已超过20,000年。
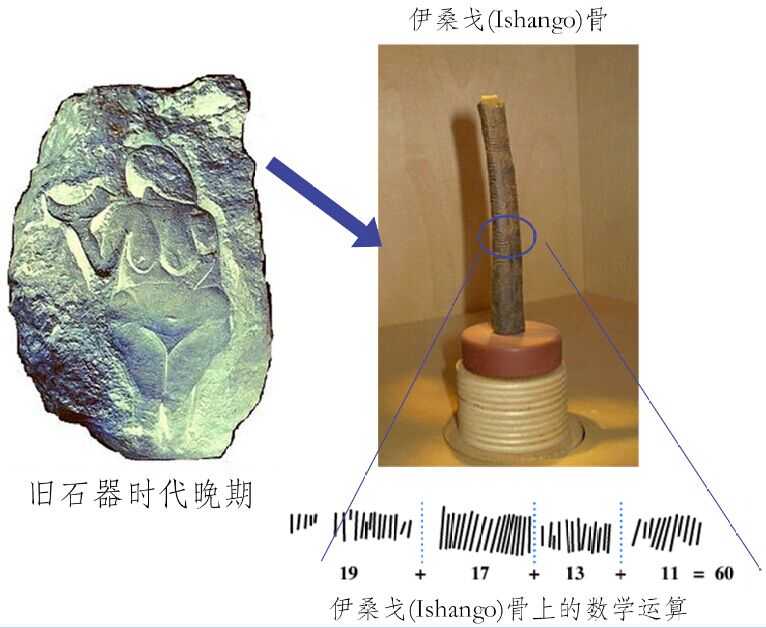
图1 旧石器时代晚期的伊桑戈骨头(Ishango Bone)(图片来源:由译者根据维基百科图片二次绘制而成)
旧石器时代的部落成员(特别是首领),通常会在树棍或者动物骨头上刻下凹槽,用以记录日常的交易活动或物品供应。通过比较树棍或骨头上凹痕的多少与变化,来进行基本的数据运算,从而可使部落首领够对一些事情进行预测,如山洞里食物还可维持几天,何时再去打几只野兔等。
在本质上,数据代表的是已发生的事实,其核心的作用则是对未来的预测。
数据的发明,对人类文明的进步,发挥了举足轻重的作用。传统意义上的“数据”,可视为“有依据的数字”。数字之所以诞生,就是因为人类在长期的实践过程中体会到,难以仅仅用语言、文字和图像,来精确描绘自己身边的世界。例如,由于每个人对“很”、“非常”这类虚词理解不一样,当有人问“今天天气有多热”,如果回答说“很热”、“非常热”,别人听到后,也只能获取一个大致的抽象印象。但如果用数字描述“今天40摄氏度”,就会毫不含糊,一清二楚。
把视野拉回当下。当人类社会进入信息时代以后,“数据”的内涵大大地被延展了,数据不仅是指“有根据的数字”,还包括存储在计算机中的信息,如表格、文本、图片、音频和视频等。
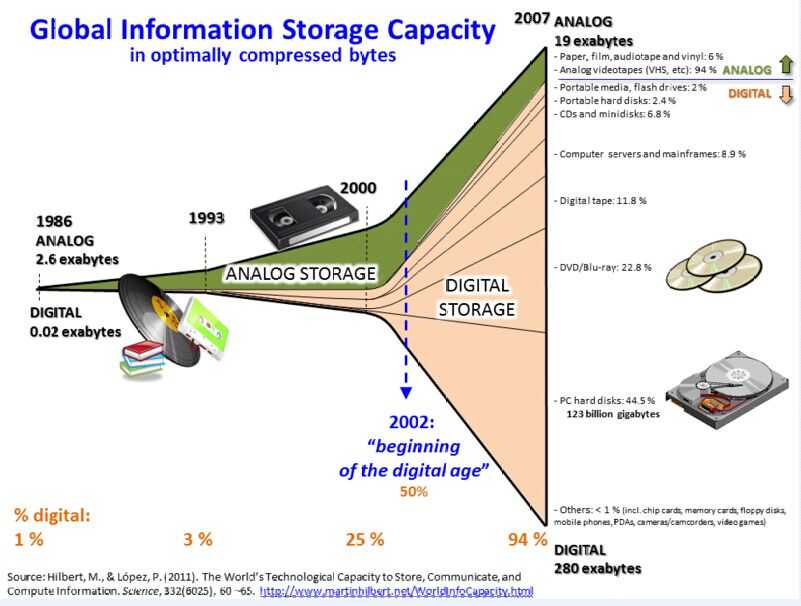
图2 1986年~2007年这30年的全球信息存储容量变化(图片来源:wikipedia.org)
有研究资料显示,自1980年以来,全球信息总量每24个月就可以翻一番。当时间迈过21世纪,自2002年数字时代开启以来,数据呈现海量增长趋势(如图2所示)。特别是在2004年社交媒体产生后,人人都是数据的生产者,数据更是呈现爆炸性增长趋势,大数据开始迈入大众的视野。
由于处于计算机科学的前沿,大数据并没有公认的定义。世界著名咨询机构麦肯锡(McKinsey)公司于2011年5月发布《大数据:下一个创新、竞争和生产力的前沿》的研究报告,报告认为:“大数据是指,大小超出了典型数据库软件的采集、储存、管理和分析等能力的数据集。”
麦肯锡的这个定义有意地带有主观性,对于“究竟多大才算大数据”,其标准是可以调整的。脸谱(Facebook)的工程总监Parikh认为,“大数据”要有“大价值”。“大数据的意义在于,能从数据中挖掘出能对商业有价值的决策力和洞察力。如果不能好好利用自己收集到的数据,那么空有一堆数据,即使体量再大,也不能称之为大数据。”
在大数据时代,由于我们创造的或采集的数据量呈现爆炸性增长,与此同时,随着先进的高性能计算技术和便捷的云计算技术的发展,给我们分析这些海量大数据提供了巨大的契机。抓住这个契机,比以往任何时候都更加重要。
针对癌症研究,2013年3月,世界顶级学术期刊《Cell》发表了一篇题为《从癌症基因组中得到的教训》(Lessons from the Cancer GenomeLessons from the Cancer Genome),研究表明,很多肿瘤的发病概率呈现出一种类似于长尾分布(“long tail” distributions)的特征(如图3所示),也就是说,癌症作为一种基因突变疾病,虽然对部分癌症类型,是由于某些特定基因高频突变所致,但是更多的癌症,是由很多的发生概率极小的基因突变所致。
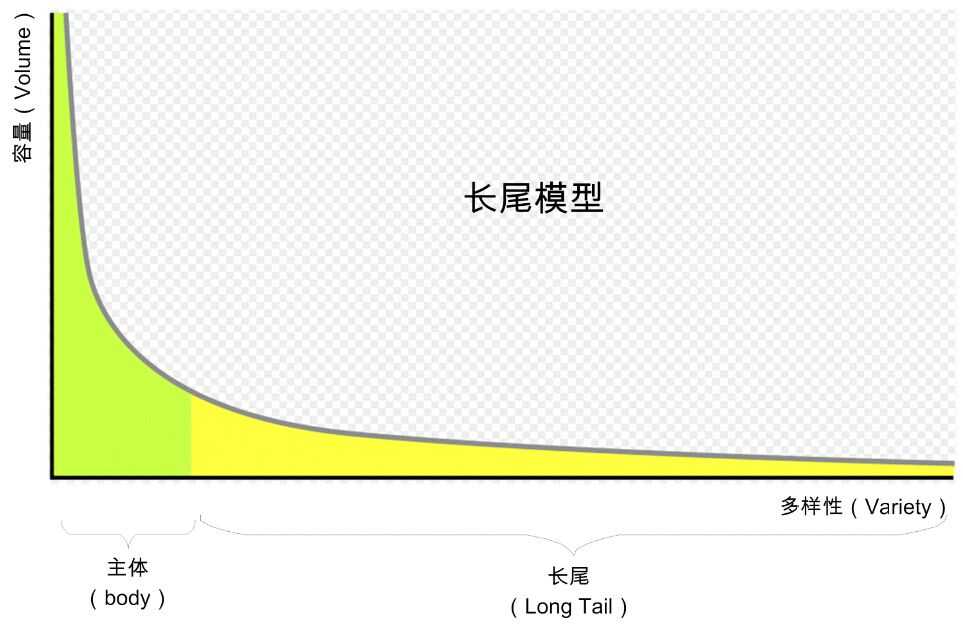
图3 长尾模型(图片来源:由编译者根据维基百科图片二次绘制而成)
由于很多诊疗机构的癌症基因组样本拥有量非常有限,这样就导致,在小样本集合里,很多出于长尾部分的基因突变,由于发生概率极低,研究机构极有可能无法观察到这种基因突变。
此外,由于机构之间的商业利益纷争,加之出于癌症患者隐私的保护,医疗机构间的癌症诊疗基因数据无法互访,彼此为对方的信息“孤岛”。
信息壁垒是延缓这种严重威胁人类生命健康研究进展的重大原因之一。这在某种程度上解释了为什么过去50年癌症的治愈率仅仅提升了8%,这在所有的疑难杂症中是提升最少的!(注:若想了解更多具体详情,建议读者可参阅南加州大学著名肿瘤学专家、乔布斯的主治医生之一戴维•阿古斯的推出著作《疾病的终结》(The end of illness))。
那有没有什么办法,来改善这种情况呢?
事实上,我们可从过往的历史中,寻找一点点启迪。
世界上,第一家欧洲咖啡馆(Coffee House)是于1645年在威尼斯开办的。咖啡馆开办的目的在于,提供一个交流的平台,让三教九流不同种类的人,能够聚在一起,指点江山,侃侃大山,从而完成思想的碰撞,进而产生新的价值——比如,促成一场新的贸易等。在咖啡馆里,有一个特征是值得特别注意的,大家聊完天,侃完大山,各回各家,各找各妈,谁也没有损失!
试想一下,如果让多家医疗研究机构的癌症诊疗数据,也能在“数字咖啡馆”走一遭,碰一碰,或许也能碰撞出“新的火花”,加速癌症的研究。这里的“数据咖啡馆”是由英特尔公司主导开发了一项数据共享技术。针对癌症研究,数据咖啡馆的核心理念就是,让不同研究机构的癌症诊断数据,“可用但不可见”——在不破坏数据归属的基础上,完成对可用信息的提取,这真是个了不起的想法(注:案例介绍来自于英特尔中国研究院院长吴甘沙先生的讲座)!
癌症如此的难以克服,那么癌症从何而来呢?有什么办法可以预防?下一节,我们将讨论这个议题。
2.癌症从哪里来?
癌症是什么?癌症是一组与基因突变有关的疾病,其特征表现为,异常细胞生长不受控制,且肆意攻击正常细胞组织。如果癌症细胞一旦失控扩散,就会导致癌症细胞的宿主(这里通常指的是人)死亡。
所谓基因,是指携带有遗传信息的DNA序列片段,它是控制性状的基本遗传单位。由于DNA分子中发生碱基对的增添、缺失或改变,从而引起基因结构的改变,称之为基因突变。导致基因突变,进而引发癌症病发的因素有二,下面分别给予简要介绍:
2.1外在因素
据美国最知名的癌症研究中心——MD安德森研究表明,所谓的外部环境泛指所有非遗传因素,包括但不限于,不良的生活方式(如滥用烟草,酗酒)、缺乏体力活动、工作压力大、环境污染,主(被)动地接触传染性生物体、不良化学品和辐射等。这些外在因素占癌症发病率比例的90%~95%!其中,最常见的外在因素导致癌症死亡比例中,滥用烟草占25% ~ 30%,不良饮食和肥胖占30% ~ 35%,单纯仅此二项之和就占据55%~65%,超过了癌症死亡的“半壁江山”。
很遗憾地说,这类癌症导致的“不可活”,多是源于病人自己的“自作孽”!
下面举例说明之。图4所示为烟草消费量与20年后肺癌发病率的滞后相关性。所谓“相关性”,是指两个或两个以上变量的取值之间存在某种规律性。这种相关性的滞后,是很容易理解的。因为今天抽支烟,并不会立马就让抽烟者的肺部有癌症病症。事实上,抽烟的危害作用是可以日积月累的,它的“功效”能潜伏20年之久!

图4 烟草消费类于肺癌发病率高度相关(图片来源:wikipedia.org)
换句话说,20岁的你,年轻任性,“一枝梨花压海棠”,潇洒地抽了一口烟,就为人到中年、事业有成40岁左右的你,培养了一个可能突变的癌细胞。但正因为这个巨大的滞后时间间隔——20年,“麻痹”了很多人:抽支烟,解解乏,也没有什么大不了的。殊不知,这种烟草消耗量和肺癌发病率的巨大的相关性,不得不让人们侧目、反省、深思。
当然,也会有人会站在学术层面表态:“相关性”不代表“因果性!”
的确,从严格意义上讲,统计学无法检验逻辑上的因果关系。根据统计结果,可以说“抽烟人群的肺癌发病率,会比不抽烟人群的发病率,高好几倍”,但统计结果无法得出“抽烟致癌”的逻辑结论。
中国概率统计领域的奠基人、国际著名数理统计学家陈希孺院士,生前常用这个例子来说明统计学的特点(案例来源:李国杰院士《大数据研究的科学价值》)。
但话说回来,大数据布道师维克托•迈尔-舍恩伯格在其著作《大数据时代》中提到的核心观点:“要相关,不要因果”。也就是说,大数据关注事物间的相关性(correlation),而非紧盯事物之间的因果关系(causal relation)。
也许正是因为统计方法并不致力于追寻事物间的因果关系,才促使数据挖掘和大数据技术在商业领域广泛流行。利用大数据分析的企业,其目标就是多挣些钱,只要从大数据挖掘中发现某种措施与增加企业利润有较强的相关性,然后采取这种措施就好了。
既然大数据的“相关性”可以正向指导商业获利,为什么我们不能“反其道而用之”呢?
虽然,目前还不能充分证明抽烟人群与肺癌发病率的因果关系,但我们已然“铁板钉钉”地证明了他们的相关性,为了活命,为何不能通过破坏他们的相关性——试一试不抽烟,结果会怎样?
2008年,大名鼎鼎的MD安德森癌症研究中心,在《Pharmaceutical Research》发表文章表明:“癌症是可预防的,但它要求改变你大部分的不良生活习惯(Cancer is a Preventable Disease that Requires Major Lifestyle Changes)”。
生命只有一次,且行且珍惜!
2.2内在因素
致癌的内在因素,主要来自于遗传突变、免疫病症、新陈代谢引发的突变等。研究表明,其实仅有5%~10%的癌症患者是源于基因缺陷。对于这类多数为先天性的癌症疾病治疗方案,包括免疫治疗、靶向治疗,甚至是提前手术——切除病灶。
2013年2月16日,时年37岁的好莱坞当红女影星安吉丽娜•朱莉(Angelina Jolie)在《纽约时报》撰文,自曝接受预防性双乳切除术。之所以切乳,是因为通过检查,她发现自己有基因缺陷,罹患乳癌的风险几率高达87%,而罹患卵巢癌的风险几率也达到50%。
安吉丽娜•朱莉从母亲那遗传了突变的癌症易感基因BRCA1。BRCA1是Breast Cancer Susceptibility Gene 1(乳腺癌易感基因类型1)的缩写,这是一种抑癌基因。在抑癌基因的作用下,正常人体每天也会产生的少量癌细胞,但很快就会被抑制或被免疫系统识别而消灭掉,并不会形成肿瘤。如果BRCA1基因突变导致抑癌功能的丢失,乳腺癌、卵巢癌或一些其他肿瘤发病率就会明显升高。

图5 接受预防性双乳切除术的安吉丽娜•朱莉(图片来源:wikipedia.org)
安吉丽娜•朱莉的母亲就是因为携带这种基因而导致卵巢癌,56岁时因病去世。朱莉不想重蹈覆辙,因此接受了预防性的手术,来降低癌症风险。2015年3月24日,她再次宣布切除了卵巢和输卵管。
注:中国留传下来一句老话,“人的命,天注定”。批判者会说这是“宿命论”的迷信,高喊“王侯将相,宁有种乎!”但就癌症而言,真的是有5%~10%的人,似乎是“天注定”——先天携带基因缺陷,极易致癌!
有时候想想,也真够吊诡的:“迷信”通常是站在“科学”的对立面的,但在某些情况下,我们却用“科学”证明“迷信”是“科学”的!
3.大数据用之于癌症斗争,挑战何在?
取得对癌症斗争胜利的关键,就要寻找到药物的圣杯(Holy Grail)。在生死关头,几乎没有人不动容,要么怕自己死掉,要么怕自己心爱的人死掉。因此,毫无疑问,如果大数据能以某种方式来帮助提升医疗水平,识别癌症潜在风险,并最终给出可靠的治疗方案,这是件多么“夕阳无限好”的事啊。
大数据用之于癌症斗争,一开始并不会那么顺风顺水。其前途无量,但道路曲折。欲取得这场战争的胜利,还面临很多挑战,例如,癌症诊疗数据获取难,数据决策执行难等,下面一一简要描述之。
3.1 癌症诊疗的基础大数据——获取难
目前,在医疗领域,面临的一个重大挑战就是如何获取有关癌症病人的大量诊疗数据。
美国临床肿瘤学协会(American Society of Clinical Oncology,ASCO)首席执行官Allen Lichter曾指出,在超过96%的病例中,病人的详细治疗信息“被锁在医疗档案和文件柜或者存储于未联网的电子系统中”。
“各自为政”的各个医疗机构,并非没有意识到医疗数据流通的重要性。但由于涉及到病人的隐私问题、机构间的利益冲突以及纯粹缺乏电子病历,阻碍着医疗领域的信息共享,让每一次癌症治疗,都像发生一个孤立事件。
令人恼火的是,很多医疗机构的诊断数据,要么从一开始就是一堆纸质文件,根本就没有数字化,从而不能更大范围的共享。要么利用电子病历数字化后,然随后就束之高阁,形成信息孤岛。
各个医疗机构仅在可供自己访问的小数据集合上施以分析,形成最终结论,这如同“盲人摸象”一样,是片面的,甚至是错误的。如果医疗领域的信息共享能取得进展,人们很有可能发现更具普遍意义的治疗方案。
我们知道,大象不是盲人根据大象局部位置的触感,得出的 “大萝卜”、“大蒲扇”、“大柱子”或“细草绳”,大象就是大象。但要得出这个结论,就要睁开眼,看到大象的全景。
在癌症诊疗数据分析中,同样也是如此。我们应看数据的全景,而不是仅仅根据事物的小样本数据就下结论。只有这样才能全面和真实的了解事物的情况 。这或许就是舍恩伯格在《大数据时代》中说的“要全体,不要样本”吧。
前文我们提到,癌症是一类长尾病症,每一个研究机构的基因组样本都相对有限。“小样本”得出的研究结论,得出有关“癌症诊断”的结论,极有可能是“盲人摸象化”的。
英特尔公司提出的“数据咖啡馆”,其核心理念把不同医疗机构的癌症诊疗数据汇聚到一起,形成大数据集合,但不同机构间的数据,“相逢但不相识”,“可用但不可见”。一旦“数据咖啡馆”项目能成功实施,势必在某种程度上加速癌症研究的技术突破。
3.2 数据化带来的颠覆式医疗——执行难
在医疗领域,欲用大数据对抗癌症,其面临的另外一个重大挑战就是,如何让医疗领域的从业人员发生重大的思维转变——重视数据文化。
数据文化的本质,就是尊重客观世界的事实,实事求是。重视数据就是强调用事实说话、按理性思维的科学精神。
而在医疗领域,似乎更看重的是“经验”!
《颠覆医疗——大数据时代的个人健康革命》(The Creative Destruction of Medicine: How the Digital Revolution Will Create Better Health Care)一书的作者、美国著名心脏病学家、基因组学家——埃里克•托普(Eric Topol)认为,医学领域是目前所有领域中最为保守的,在数字化革命以来,似乎被完全孤立起来一样。但在未来的几年里,医学领域将不可避免的被“熊彼特化”——即被创造性破坏。

图6 破坏似创新理论的提出者——约瑟夫•熊彼特(Joseph Schumpeter)(图片来源:wikipedia.org)
目前,信息技术(特别是现在的大数据技术)就如同一个“鲶鱼”,它游进哪个领域,都会带来“创造性破坏”。“创造性破坏理论”是著名美籍奥地利经济学家约瑟夫•熊彼特(Joseph A. Schumpeter, 1883~1950年)最有名的观点。在熊彼特看来,每一次大规模的创新,都淘汰旧的技术和生产体系,并建立起新的生产体系。
大数据给医疗领域带来的“摧枯拉朽”、“吐故纳新”,是医疗领域目前必须承受的“变革之痛”!
4.哪些机构在用大数据对抗癌症?
倘若没有商业大公司和医疗行业的大力推动,大数据对抗癌症的战争,多半如同“水中捞月”、“雾里看花”一样不靠谱。然而,令人欣慰的是,诸如IBM、美国临床肿瘤学协会和谷歌等巨头公司和行业协会的重度参与,给大数据对抗癌症带来了胜利的曙光。
4.1人工智能驱动的癌症诊断大师——沃森
2011年,IBM超级机器人沃森(Watson),在美国著名电视智力竞赛节目“危险边缘(Jeopardy)”中,战胜了两位人类智力冠军——最高奖金得主布拉德•鲁特尔和连胜纪录保持者肯•詹宁斯,并赢得100万美元的奖金。

图7 电脑对垒人脑(图片来源:FT中文网)
如今,“功成名就”的沃森已开始转战医疗领域。自2012年起,沃森开始在美国一家名为“纪念斯隆-凯特琳癌症中心(Memorial Sloan-Kettering Cancer Center)”开始实习。
沃森人工智能(AI)系统,就像一名在医学院接受严格训练的预备役医生那样,每天“学而时习之”——它每天学习数以百万计的临床资料数据、期刊文章以及临床试验报告,然后通过“人工智能”算法,学习如何正确诊断疾病、并拿出可行的治疗方案。目前沃森能帮助医疗专家做癌症等复杂诊断,以及指出医疗专家可能忽略的细微差别。
2015年5月,美国和加拿大的14家癌症研究机构宣布,将使用IBM公司的沃森智能数据分析引擎,其在海量癌症病例数据库中,寻找和当前病例最为相匹配的癌症患者诊疗信息,从而协助医生给出最为有效的诊断方案,以及给出最有可能治疗特定患者的抗癌药物。
沃森(Watson)智能系统,通过对自己体内庞大的诊断数据库——病理和药理分析,还可挖掘出新的关联关系,智能“推荐”从未在癌症治疗使用过的药物。
在沃森(Watson)智能系统中,通过编写数据挖掘分析算法,沃森可以模拟人体和成千上万种药物做病理和药理实验。细胞突变是造成癌症的主要因素,经过一番“深思熟虑”,根据自己的“博学”医学经验,沃森可以给出抑制突变细胞最有效的药物。当然,在是否采纳由人工智能(AI)驱动下的沃森的建议上,医生肯定会综合考量多种因素,但是可以肯定的是,由于沃森的参与,它无疑会大大会加快医生决策的过程。
4.2 医学大数据的解读先锋——CancerLinQ
用大数据技术来化解癌症之痛,是一个很有前途的方向。朝这个方向努力的先行者是——非营利专业组织美国临床肿瘤学协会(American Society of Clinical Oncology,ASCO)。2013年12月,ASCO开启了一个利用大数据帮助癌症治疗的项目——CancerLinQTM,该项目设计的目的在于,力图收集成千上万癌症患者的诊疗数据,用于指导对医疗系统内其他病人的治疗。
癌症患者的主治医师将能像用谷歌一样,搜索这个诊疗大数据库——CancerLinQ。根据其他类似病例的治疗情况,医生可获得诊疗策略方面的建议。
事实上,CancerLinQ本身还是一个“快速学习系统”,通过机器学习技术,可从海量医疗数据中发现有价值的模式,进而形成对癌症深度洞察,并加快发现新药的速度。
ASCO肿瘤信息委员会主席Gregory Masters教授说,我们已经进入精准医学时代,随着对肿瘤学深入了解,将会研制出新的靶向药物,用来定向治疗某种特定癌症。CancerLinQ在这其中,将发挥及为重要的先锋作用。
4.3“熨平”混杂数据的伙计——FlatIron Health
大数据所需面临的挑战还在于,从我们身边的大千世界中获取的数据,十之七八是凌乱无章的,非结构化数据(注:事实上,这正是大数据的4个V特征之一的Variety——多态性)。
尽管多年来,医学管理机构一直在努力说服医生和医院采用电子病历(Electronic Medical Record, EMR),但面向癌症的诊疗数据,依旧难于查找和使用。每位癌症患者的数据可能会有几十个来源:实习医师、肿瘤科医生、放射科医生、外科医生、化验室和病理报告等等。
即使这些诊疗信息已经数字化,也存在着IT技术人员所说的“格式散乱”问题。这些数据的来源很多,有来自病历资料的、医生笔记的、与护理人员互动交谈信息的,还有癌症患者的治疗付费信息。
不同诊断设备的后台数据库没有经过规整,展示方式因化验报告和病历的不同,而存在巨大差异,结果造成各种数据库系统无法兼容,再加上有关个人健康信息的严格隐私规定,令共享数万种肿瘤疗法变得难上加难——数据融合成为医疗大数据的利用的“头等大事”
值得庆幸的是,大数据技术的过人之处就在于,能就从混杂的、非结构化数据便捷地抽取有价值的信息。
在2012年,纳特•特纳(Nat Turner)和扎克•温伯格(Zach Weinberg)成立Flatiron Health,并构建了OncologyCloud(肿瘤学云平台),该项目旨在整合全世界的肿瘤数据。
以“不作恶不(Do not be evil)”为公司口号的谷歌,再次为Flatiron打开支票薄,通过其风险资本部门谷歌风投公司(Google Ventures)给Flatiron注资超过1亿美元,成为Flatiron的幕后老板。
FlatIron Health公司认为,大多数的有临床价值(癌症)数据,停留在医生和护士的笔记,病理报告,PDF文档、CT扫描图形和其他非结构化形式资料中。
此外,目前仅有一小部分癌症患者的治疗数据得到了有系统地采集。这种采集基本上是在临床试验中随意为之的,只覆盖了大约4%的癌症患者,96%的癌症患者其实是不愿意参与临床试验的。
传统的人口健康分析报告,主要基于患者向保险公司提供的病情理赔数据,这的确可达到立竿见影地分析效果。但对于癌症——这个高度复杂的病种,则难以获得对该疾病的深度理解。仅仅通过肿瘤病情的理赔数据来加以分析,从而来获知对癌症的洞察,这无异于冰山一角,管中窥豹、“仅”见一斑!如果要想获得“临床真理”,你就必须深入肿瘤病情的细节。
FlatIron项目希望能从余下的96%患者中,采集更多的数据,然后加以整理,实现标准化,然后将数据提供给医生。Flatiron的厉害之处就在于,它可抓取医患之间各个阶段的交互数据。不管这些数据的多模态的,还是非结构化的,Flatiron都可以很好的利用这些数据,从而使之可以与其它数以百万计患者数据,进行比较分析。
目前,还有些其它研究特定类型的癌症专家系统。例如,Dragon Master基金会就与五家美国儿科医院合作,从罕见儿童脑肿瘤患者提取组织样本,建立癌症样本数据库。
Dragon Master基金会认为,癌症完全是由细胞突变引起的,其主导的研究致力于,从我们的身体中复杂的遗传数据——基因组(Genome)中探寻癌症致病的机理。
5. 癌症大数据的重要源头——基因组数据
现在,很多知名癌症研究中心都会提供全方位的基因分析服务,尤其是针对晚期癌症患者。借助于所有这些基因数据,医生们可以重新对患者进行分类。人们再也无需像以前那样,用‘癌症X期’描述一名癌症患者,而是可以用癌症分子的驱动水平,来精确地描述癌症病情。从这个基因层面上诊疗癌症,是2015年1月美国总统奥巴马宣布的精准医疗计划(precision-medicine plan)背后的驱动力之一。
基因组数据是典型的大数据。例如,位于马里兰州的、由美国国家生物技术信息中心(National Center for Biotechnology Information ,NCBI)维护的GenBank序列数据库,收纳了世界各地实验室中测得的10多万不同的生物序列。
值得注意的是,就在我们眼皮底下,存在着一项超越摩尔定律(Moore’s Law)的数字技术——DNA测序。DNA测序的应用越来越普遍,但是其成本的下降幅度已远超出了摩尔定律的预计。
图8 DNA结构 (图片来源:编译者绘制)
仅以GenBank来说明生物序列数据增长的趋势。根据GenBank公布的文献资料显示,自1982年创库以来,其容量以指数级的速度增长,平均每18个月翻一番,而测序成本也随时间大幅下降,其趋势完全赶超IT领域的“摩尔定律”,如图9所示。
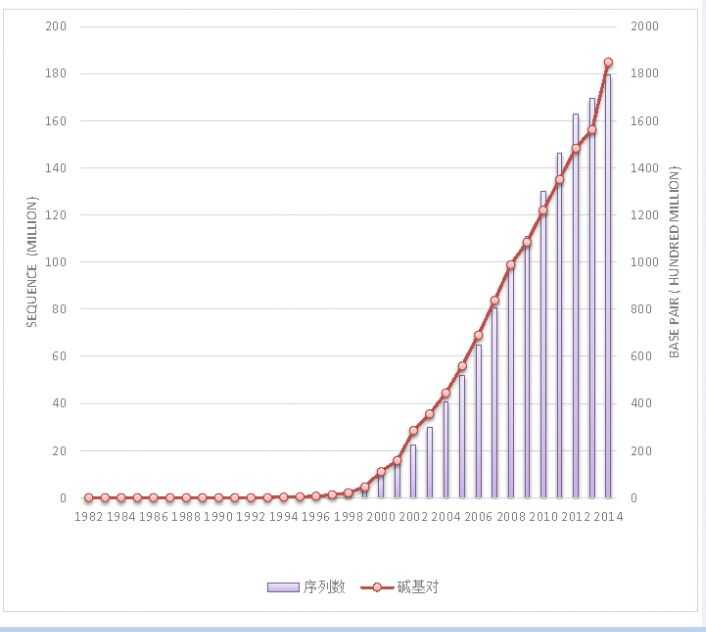
图 9 GenBank的容量每18个月翻一番(图片来源:编译者绘制)
目前,为了存储由基因组测序仪输出的原始代码——基因组数据,计算机系统需要存储200GB数据(译者注:博文作者Bernard Marr可能对生物信息学了解不甚了解,或其语焉不详。事实上,仅单条个人的全基因组数据大小就达到140GB,更何况要构建包含非常多的癌症患者的基因组数据库。对此,欲了解更多信息,读者可参阅《Naure》上的一篇文章:生物学:大数据的大挑战(Biology: The big challenges of big data)
研究者们可利用这些基因组数据,实施全方位的比较分析,从不断增长的基因组数据库中,找出是哪些因素(如致癌基因)是触发癌症的关键要素。
在前文提到的美国奥巴马政府推出的精准医疗计划中,就包括“百万基因组计划(Million Genomes Project)”,在该计划中,预备测量一个百万个人类基因组样本,也就是说,其容量是100万个140G。大数据的“大”,在容量上,已被它结结实实地坐实了!
然而,“大”并不是大数据的最难以克服的挑战,这仅是个规模问题。有些项目,诸如Folding@home就通过提出主动式方案,来解决规模的问题。该方案可充分利用全球性的、分布式网络处理能力,大大加速了在该蛋白质数据的利用率和解码效率。
注:Folding@home是一个研究研究蛋白质折叠,误折,聚合及由此引起的相关疾病的分布式计算工程。Folding@home的中文含义就是“在家折叠”, “折叠(Folding)”是蛋白质的最重要的性状之一,如果蛋白质没有正确地折叠,人类会遭受某些病症的折磨。许多疾病,诸如阿兹海默症(Alzheimer’s),疯牛病(Mad Cow/BSE),还有帕金森氏症(Parkinson’s)等,特别是一些癌症疾病等,正是由于一些细胞内的重要蛋白发生突变,导致蛋白质聚沉或错误折叠而造成的。
图10 Folding@home客户端,点击可下载(图片来源:编译者截图)
Folding@home项目参与的志愿者,可以通过下载一个客户端,在家里(@home)就可以利用自己电脑(甚至是安卓、苹果手机)的闲置计算资源,来帮忙处理部分蛋白质数据的计算。一旦当前的客户端关闭,客户端就会自动把计算得到的临时结果发回计算中心,再由计算中心找到另外一个适用的志愿者客户端,接力计算。2003年,Folding@home项目完成了它的第一个分布式计算项目。
Folding@home项目之所以能够成功,究其本质,是因为“众人拾柴火焰高”,它充分整合世界各地的志愿者的闲置计算资源,来完成以往只能在大规模超级计算机上完成的项目。这是众多大规模分布式计算项目之一,也是最出名、普及最广的“网格计算”项目。而“网格计算”,在某种意义上,就是现在热炒的“云计算”的妈妈)。
6.大数据对抗癌症,前景如何?
前面我们说道,大数据对抗癌症的战争中,已经吸引诸如IBM、谷歌和美国临床肿瘤学协会的重度参与,前途看似一片光明。
然而,在癌症研究领域,也有部分领军人物,对大数据的长期抗癌前景表示质疑。例如, MIT(麻省理工学院)癌症研究中心的著名学者罗伯特•温伯格(Robert Weinberg),就在《细胞》杂志(Cell)撰文,指出大数据和癌症之间存在不稳定的关系。他强调说,从肿瘤里的蛋白质间的相互作用到基因突变,各方面多形式的数据膨胀,已经远远超过研究人员的解读能力。
我们常说,前途是光明的,但道路是曲折的。在征服癌症的这条道路上,“路漫漫,其修远兮”。在这条路上,有一份质疑,多一份冷静,或许可以让路走得更远。
简而言之,大数据领域的科学技术和癌症之间的战争,刚刚打响。这场战争胜利的号角,远未到该吹响的时候,但战斗正在取得显著地进展。就在今年,英国顶级学术咨询机构UCL Consultant,就给出一项研究结论,到2050年,年龄在80岁以下人群,都不会死于癌症。
就如同大数据在其它跨界领域研究大放异彩一样,我们有理由相信,由大数据驱动技术的有关癌症的研究,在获取这场大数据对抗癌症的战争中,无疑将扮演举足轻重的角色。
译者介绍:张玉宏,博士。2012年毕业于电子科技大学,现执教于河南工业大学。中国计算机协会(CCF)会员,ACM/IEEE会员。主要研究方向为高性能计算、生物信息学,主编有《Java从入门到精通》一书。
部分原文来自:Forbes
更多阅读:
